php读取csv文件后,uft8 bom导致在页面上显示出现问题的解决方法
date.csv:
"ID" "NAME" "EMAIL"
"1" "小明" "xm@163.com"
"2" "小东" "xd@sina.com"
"3" "小少" "shaozi@hotmai.com"
<?php
$handle=fopen('date.csv','r');
while($data=fgetcsv($handle,10000,"/t"))
{
echo "$data[0]"."$data[1]"."$data[2]";
}
?>
读取后在页面上显示时,成了这样:
"ID" NAME EMAIL
1 小明 xm@163.com
2 小东 xd@sina.com
3 小少 shaozi@hotmai.com
fgetcsv函数的字段环绕符默认是双引号,
为什么我读取出来时,其它字段都好好的,可是ID还有双引号包着?
上网查了下,原来是utf8编码的bom在php下无法识别.
下面是查来的资料:
Unicode规范中有一个BOM的概念。BOM——Byte Order Mark,就是字节序标记。在
这里
找到一段关于BOM的说明:
在UCS 编码中有一个叫做"ZERO WIDTH NO-BREAK SPACE"的字符,它的编码是FEFF。而FFFE在UCS中是不存在的字符,所以不应该出现在实际传输中。UCS规范建议我们在传输字节流前,先传输字符"ZERO WIDTH NO-BREAK SPACE"。这样如果接收者收到FEFF,就表明这个字节流是Big-Endian的;如果收到FFFE,就表明这个字节流是Little-Endian的。因此字符"ZERO WIDTH NO-BREAK SPACE"又被称作BOM。
UTF-8不需要BOM来表明字节顺序,但可以用BOM来表明编码方式。字符"ZERO WIDTH NO-BREAK SPACE"的UTF-8编码是EF BB BF。所以如果接收者收到以EF BB BF开头的字节流,就知道这是UTF-8编码了。
Windows就是使用BOM来标记文本文件的编码方式的。
另外unicode网站的
FAQ-BOM
详细介绍了BOM。官方的自然权威,不过是英文的,看起来比较费劲。
UTF-8编码的文件中,BOM占三个字节。如果用记事本把一个文本文件另存为UTF-8编码方式的话,用UE打开这个文件,切换到十六进制编辑状态就可以看到开头的FFFE了。这是个标识UTF-8编码文件的好办法,软件通过BOM来识别这个文件是否是UTF-8编码,很多软件还要求读入的文件必须带BOM。可是,还是有很多软件不能识别BOM。我在研究Firefox的时候就知道,在Firefox早期的版本里,扩展是不能有BOM的,不过Firefox 1.5以后的版本已经开始支持BOM了。现在又发现,PHP也不支持BOM。
PHP在设计时就没有考虑BOM的问题,也就是说他不会忽略UTF-8编码的文件开头BOM的那三个字符。由于必须在转换->UTF-8转ASCII,或者在另存为里选择ASCII编码。如果是DOS格式的行尾符,可以用记事本打开,点另存为,选ASCII编码。如果包含中文字符的话,可以用UE的另存为功能,选择“UTF-8 无 BOM”即可。请参考下面的图片: 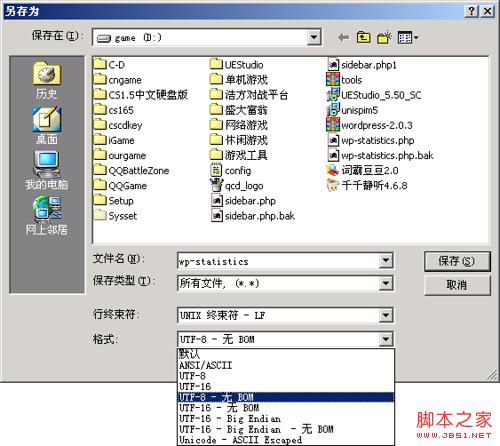
根据Bo-Blog的wiki的说明:Editplus需要先另存为gb,再另存为UTF-8。不过这样做要小心,所有GBK编码中不包含的字符就会都丢了。如果有一些非中文的字符在文件里的话还是不要用这种办法了。(从这一个小方面来看,UE——UltraEdite-32确实比Editplus好很多,Editplus太轻量级了)
另外我发现了一个办法,就是利用Wordpress提供的文件编辑器。这个办法不受限制,不需要去下载专门的编辑器,毕竟大家都在用Wordpress嘛。先在ftp里把要编辑的文件的写入权限打开,然后进入Wordpress后台->管理->文件编辑器,输入要编辑文件的路径,点编辑文件。在显示出来的编辑界面中,你是看不到开头的那三个字符的,不过没关系,把光标定位在整个文件的第一个字符前,按一下Backspace键。OK了,点更新文件吧,在ftp里刷新一下,可以看到文件小了3字节,大功告成。
最后说一下,这是个大问题,所有要自己写插件的,编辑别人的插件自己用的,需要修改模版的(这条估计每个人都需要吧),最好了解一下上面的知识,免得出现问题时不知所措。
相关推荐
-
php使用fgetcsv读取csv文件出现乱码的解决方法
本文实例讲述了php使用fgetcsv读取csv文件出现乱码的解决方法.分享给大家供大家参考.具体分析如下: 一般来说在php中碰到乱码多半是编码问题,在这里我们实例分析了fgetcsv读取csv文件乱码原因所在与解决方法. 例子如下: 复制代码 代码如下: function get_csv_contents( $file_target ){ $handle = fopen( $file_target, 'r'); while ($data = fgetcsv($handle, 1000,
-
php将csv文件导入到mysql数据库的方法
本文实例讲述了php将csv文件导入到mysql数据库的方法.分享给大家供大家参考.具体分析如下: 本程序实现数据导入原理是先把csv文件上传到服务器,然后再通过php的fopen与fgetcsv文件把数据保存到数组,然后再用while把数据一条条插入到mysql数据库,代码如下: 复制代码 代码如下: <?php $fname = $_files['myfile']['name']; $do = copy($_files['myfile']['tmp_name'],$fname); if ($
-
php写入数据到CSV文件的方法
本文实例讲述了php写入数据到CSV文件的方法.分享给大家供大家参考.具体实现方法如下: <?php $row = 0; ini_set('max_execution_time', 300); $cate;$item;$value;$us; $fp = fopen("torah1.csv", "w"); if (($handle = fopen("t.csv", "r")) !== FALSE) { while (($d
-
php读取csv文件并输出的方法
本文实例讲述了php读取csv文件并输出的方法.分享给大家供大家参考.具体实现方法如下: <?php $row = 0; $j = 1; // Linea por la que quieres empezar $file = "name.txt"; //Nombre del fichero if (($handle = fopen($file, "r")) !== FALSE) { while (($data = fgetcsv($handle, "
-
php使用fputcsv()函数csv文件读写数据的方法
本文实例讲述了php使用fputcsv()函数csv文件读写数据的方法.分享给大家供大家参考.具体分析如下: fputcsv() 函数用于将数据格式为csv格式,以便写入文件或者数据库. 1.将字符串写入csv文件中,代码如下: 复制代码 代码如下: $test_array = array( array("111","sdfsd","sdds","43344","rrrr"), array(
-
php导入csv文件碰到乱码问题的解决方法
今天主要是想写一个php导入csv文件的方法,其实网上一搜一大把.都是可以实现怎么去导入的.但是我导入的时候遇到了两个问题,一个是在windows上写代码的时候测试发生了乱码问题,然后解决了.第二个是提交到linux系统上的时候又发生了乱码.我开始还不清楚是乱码的原因,一开始我还以为是代码svn提交发生的错误,到最后我在我的一个群里提问了一下,一朋友是做phpcms的,他说他遇到从Windows提交到Linux的时候刚开始也总是发生错误,后来排查原因就是乱码导致成的.下面切入正题看怎么解决两个问
-

php读取csv文件后,uft8 bom导致在页面上显示出现问题的解决方法
date.csv:"ID" "NAME" "EMAIL""1" "小明" "xm@163.com""2" "小东" "xd@sina.com""3" "小少" "shaozi@hotmai.com" 读取这个csv文件 复制代码 代码如下: <?php$handl
-
解决Python中pandas读取*.csv文件出现编码问题
1.问题 在使用Python中pandas读取csv文件时,由于文件编码格式出现以下问题: Traceback (most recent call last): File "pandas\_libs\parsers.pyx", line 1134, in pandas._libs.parsers.TextReader._convert_tokens File "pandas\_libs\parsers.pyx", line 1240, in pandas._libs
-
基于Pandas读取csv文件Error的总结
OSError:报错1 <span style="font-size:14px;">pandas\_libs\parsers.pyx in pandas._libs.parsers.TextReader.__cinit__ (pandas\_libs\parsers.c:4209)() pandas\_libs\parsers.pyx in pandas._libs.parsers.TextReader._setup_parser_source (pandas\_libs\
-
使用python的pandas库读取csv文件保存至mysql数据库
第一:pandas.read_csv读取本地csv文件为数据框形式 data=pd.read_csv('G:\data_operation\python_book\chapter5\\sales.csv') 第二:如果存在日期格式数据,利用pandas.to_datatime()改变类型 data.iloc[:,1]=pd.to_datetime(data.iloc[:,1]) 注意:=号,这样在原始的数据框中,改变了列的类型 第三:查看列类型 print(data.dtypes) 第四:方法一
-
Python Pandas批量读取csv文件到dataframe的方法
PYTHON Pandas批量读取csv文件到DATAFRAME 首先使用glob.glob获得文件路径.然后定义一个列表,读取文件后再使用concat合并读取到的数据. #读取数据 import pandas as pd import numpy as np import glob,os path=r'e:\tj\month\fx1806' file=glob.glob(os.path.join(path, "zq*.xls")) print(file) dl= [] for f i
-
python中pandas读取csv文件时如何省去csv.reader()操作指定列步骤
优点: 方便,有专门支持读取csv文件的pd.read_csv()函数. 将csv转换成二维列表形式 支持通过列名查找特定列. 相比csv库,事半功倍 1.读取csv文件 import pandas as pd file="c:\data\test.csv" csvPD=pd.read_csv(file) df = pd.read_csv('data.csv', encoding='gbk') #指定编码 read_csv()方法参数介绍 filepath_or_buf
-
Python读取CSV文件并进行数据可视化绘图
介绍:文件 sitka_weather_07-2018_simple.csv是阿拉斯加州锡特卡2018年1月1日的天气数据,其中包含当天的最高温度和最低温度.数据文件存储与data文件夹下,接下来用Python读取该文件数据,再基于数据进行可视化绘图.(详细细节请看代码注释) sitka_highs.py import csv # 导入csv模块 from datetime import datetime import matplotlib.pyplot as plt filename = 'd
-
php实现的读取CSV文件函数示例
本文实例讲述了php实现的读取CSV文件函数.分享给大家供大家参考,具体如下: function read_csv($cvs) { $shuang = false; $str = file_get_contents($cvs); for ($i=0;$i<strlen($str);$i++) { if($str{$i}=='"') { if($shuang) { if($str{$i+1}=='"') { $str{$i} = '*'; $str{$i+1} = '*'; } e
-
go语言读取csv文件并输出的方法
本文实例讲述了go语言读取csv文件并输出的方法.分享给大家供大家参考.具体实现方法如下: 复制代码 代码如下: package main import ( "encoding/csv" "fmt" "io" "os" ) func main() { file, err := os.Open("names.txt") if err != nil {