修复CentOS7升级Python到3.6版本后yum不能正确使用的解决方法
之前把现有这台阿里CentOS7.2系统的Python2.7.5升级成Python3.6后,yum工具就不能不觉使用了。当时查了下说明python版本的问题,但是用网上的方法还是没解决,后面也就一直没管了。最近要弄一个Nodejs小程序,需要用yum安装一些开发工具,不得不修复这个问题。

1 yum工具报错情况
直接执行 yum 命令就会提示 /usr/bin/yum 文件第34行有错误:
[root@typecodes ~]# yum File "/usr/bin/yum", line 34 ^ SyntaxError: EOF while scanning triple-quoted string literal [root@typecodes ~]#
但是vim查看这个文件根本没有这一行:
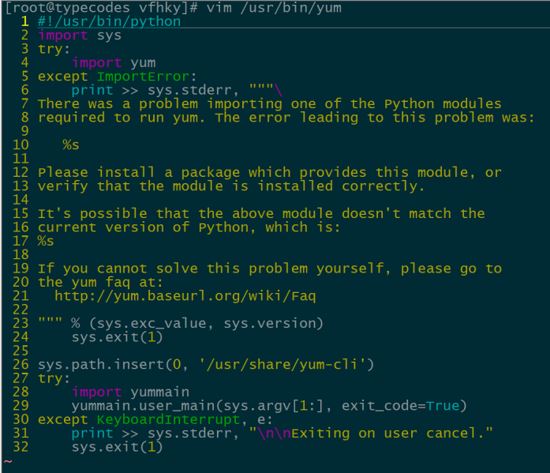
2 解决方法
由于找不到报错的位置,只能考虑重新安装yum了。

2.1、下载yum安装包
[root@typecodes ~]# wget -c http://yum.baseurl.org/download/3.4/yum-3.4.3.tar.gz [root@typecodes ~]# tar -zxf yum-3.4.3.tar.gz [root@typecodes ~]# cd yum-3.4.3/
接着使用 python2 yummain.py install yum 命令(还是不能使用python3来执行)重新安装yum工具:

2.2、执行 yum 命令
尝试执行 yum 命令,在 /usr/bin/yum 文件的第30行报错:
[root@typecodes yum-3.4.3]# yum File "/usr/bin/yum", line 30 except KeyboardInterrupt, e: ^ SyntaxError: invalid syntax [root@typecodes yum-3.4.3]#
显然上面的 except 是python2的写法,当然不能使用默认的Python3来执行了。于是把这个文件第1行的 #!/usr/bin/python 替换成 #!/usr/bin/python2 。
2.2、继续执行 yum 命令
尝试执行 yum -y update 命令更新CentOS系统,结果在文件 /usr/libexec/urlgrabber-ext-down 第28行处还是报 SyntaxError: invalid syntax 的错误。
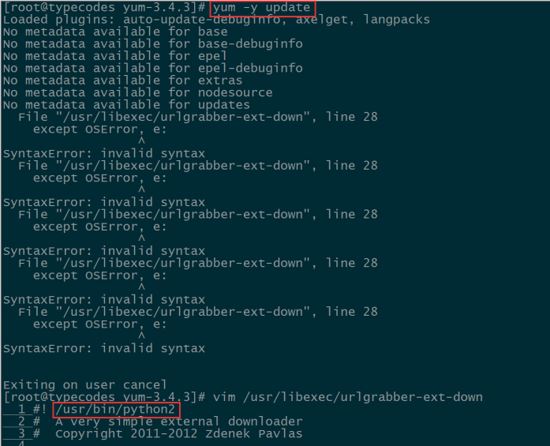
问题是一样的,要么把 /usr/libexec/urlgrabber-ext-down 文件中所有的except写法改成Python3,要么修改第1行的解释器声明。显然第2种方法更新简单有效。
3 解决完毕
到此,可以愉快地使用 yum -y update 命令更新CentOS系统,然后做开发了!

总结
以上所述是小编给大家介绍的修复CentOS7升级Python到3.6版本后yum不能正确使用的解决方法,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对我们网站的支持!
您可能感兴趣的文章:
- Python升级导致yum、pip报错的解决方法
- CentOS下使用yum安装python-pip失败的完美解决方法
相关推荐
-

Python升级导致yum、pip报错的解决方法
前言 本文主要给大家介绍了因Python升级导致yum.pip报错的解放方法,分享出来供大家参考学习,下面话不多说了,来一起看看详细的介绍吧. 原因: yum是Python写的.服务器上Python版本过低,升级为2.7,而yum/pip未升级,导致在执行yum/pip时报这个错误. yum报错: There was a problem importing one of the Python modules required to run yum. The error leading to th
-
CentOS下使用yum安装python-pip失败的完美解决方法
以前用Ubuntu的时候感觉很简单的事到ContOS上却变得很头痛,在执行以下命令安装python-pip居然什么也没执行. yum install python-pip 后来google了一下说是这个包在EPEL源里,要添加EPEL源才可以.然后按博客里说的方法添加,执行以下命令: sudo rpm -ivh epel-release* 但是最后提示系统里已经安装了最新的epel包,但为什么却用不了呢?google了一天多都没有结果,最后在一个博客看到一句话让我找到了方向.CentOS中有的源
-
修复CentOS7升级Python到3.6版本后yum不能正确使用的解决方法
之前把现有这台阿里CentOS7.2系统的Python2.7.5升级成Python3.6后,yum工具就不能不觉使用了.当时查了下说明python版本的问题,但是用网上的方法还是没解决,后面也就一直没管了.最近要弄一个Nodejs小程序,需要用yum安装一些开发工具,不得不修复这个问题. 1 yum工具报错情况 直接执行 yum 命令就会提示 /usr/bin/yum 文件第34行有错误: [root@typecodes ~]# yum File "/usr/bin/yum", lin
-
解决CentOS 7升级Python到3.6.6后yum出错问题总结
最近将一台测试服务器操作系统升级到了Cent0S 7.5,然后顺便也将Python从2.7.5升级到Python 3.6.6,升级完成后,发现yum安装相关包时出现异常,报"File "/usr/libexec/urlgrabber-ext-down", line 28"这样的错误, 具体错误信息如下所示: # yum install openssl .......................... Total download size: 1.7 M Is t
-
springboot 高版本后继续使用log4j的完美解决方法
springboot 高版本后不支持log4j了,很多人还是喜欢log4j风格的日志,我们自己来加载log4j,其实很容易. 第一步:我们手动加入我们想要的log4j jar,在项目里面随便建一个文件夹,将用到的jar丢进去,右键 add to build path 第二步: 在main函数启动类所在的包或者其子包下写一个这样的类,用来加载log4j配置文件,是的,什么内容都没有. import org.springframework.boot.context.properties.Confi
-
详解tensorflow2.x版本无法调用gpu的一种解决方法
最近学校给了一个服务器账号用来训练神经网络使用,服务器本身配置是十路titan V,然后在上面装了tensorflow2.2,对应的python版本是3.6.2,装好之后用tf.test.is_gpu_available()查看是否能调用gpu,结果返回结果是false,具体如下: 这里tensorflow应该是检测出了gpu,但是因为某些库无法打开而导致tensorflow无法调用,返回了false,详细查看错误信息可以看到一行: 可以看到上面几个文件都顺利打开了,但是最后一个libcudnn
-
jQuery多个版本和其他js库冲突的解决方法
jQuery多个版本或和其他js库冲突主要是常用的$符号的问题,这个问题 jquery早早就有给我们预留处理方法了,下面一起来看看解决办法. 1.同一页面jQuery多个版本或冲突解决方法. <!DOCTYPE html> <html lang="en"> <head> <meta charset="utf-8" /> <title>jQuery测试页</title> </head>
-
Python实现动态添加类的属性或成员函数的解决方法
某些时候我们需要让类动态的添加属性或方法,比如我们在做插件时就可以采用这种方法.用一个配置文件指定需要加载的模块,可以根据业务扩展任意加入需要的模块. 本文就此简述了Python实现动态添加类的属性或成员函数的解决方法,具体方法如下: 首先我们可以参考ulipad的实现:mixin. 这里做的比较简单,只是声明一个类,类初始化的时候读取配置文件,根据配置列表加载特定目录下的模块下的函数,函数和模块同名,将此函数动态加载为类的成员函数. 代码如下所示: class WinBAS(Bas): def
-
Python遍历zip文件输出名称时出现乱码问题的解决方法
本文实例讲述了Python遍历zip文件输出名称时出现乱码问题的解决方法.分享给大家供大家参考.具体如下: windows中使用python2.7遍历zip文件之后输出文件名等信息,console打印的中文及一些标点出现乱码.查了一下网上说的windows的编码为cp936,print()函数交给系统处理打印,所以要提前编码成windows能够识别的编码. 这种print的乱码也会出现在形如print(mylist)中(mylist是python的list类型变量,print(mylist[2]
-
python抓取并保存html页面时乱码问题的解决方法
本文实例讲述了python抓取并保存html页面时乱码问题的解决方法.分享给大家供大家参考,具体如下: 在用Python抓取html页面并保存的时候,经常出现抓取下来的网页内容是乱码的问题.出现该问题的原因一方面是自己的代码中编码设置有问题,另一方面是在编码设置正确的情况下,网页的实际编码和标示的编码不符合造成的.html页面标示的编码在这里: 复制代码 代码如下: <meta http-equiv="Content-Type" content="text/html;
-
python生成不重复随机数和对list乱序的解决方法
andom.sample(list, n)即是从list中随机选取n个不同的元素 # -*- coding: utf-8 -*- import random # 从一个list中随机挑选5个 list = [12, 23, 13, 14, 78, 234, 123, 12345] randomlist = random.sample(list, 5) print randomlist # 在range(10)中随机生成5个不重复的数,可以作为随机下标集合,然后到list中取数 len = lis
-
python引用(import)某个模块提示没找到对应模块的解决方法
自己检查了很多遍,自己写的每错,但是还是报没有找到对应python模块.目录结构如下图所示: __init__.py这个文件需要引入models下的todo_kanban.py文件.__init__内容如下: 写法没问题,但是报错没找到对应模块,经过查找官方文档,需要在被引入(import)的目录下创建一个__init__.py文件,即使 该文件为空也没关系. 以上这篇python引用(import)某个模块提示没找到对应模块的解决方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望