Apache Doris的Bitmap索引和BloomFilter索引使用及注意事项
目录
- 1. Bitmap索引的使用
- 1.1 Bitmap索引介绍
- 1.2 Bitmap索引使用的注意事项
- 1.3 Bitmap索引的使用
- 2. BloomFilter索引
- 2.1 BloomFilter索引介绍
- 2.2 BloomFilter原理
- 2.3 BloomFilter索引的使用
- 2.4 Doris BloomFilter使用场景
- 2.5 Doris BloomFilter使用注意事项
1. Bitmap索引的使用
1.1 Bitmap索引介绍
bitmap index是一种位图索引,是一种快速数据结构,能够加快查询速度
1.2 Bitmap索引使用的注意事项
使用限制:
- 目前索引仅支持bitmap类型的索引
- bitmap索引仅在单列上创建
- bitmap索引能够应用在Duplicate、Uniq数据模型的所有列和Aggregate模型的key列上
- bitmap索引仅在Segment V2储存格式下生效。当创建index时,表的存储格式将默认转换为V2格式
bitmap索引支持的数据类型:
- TINYINT
- SMALLINT
- INT
- UNSIGNEDINT
- BIGINT
- CHAR
- VARCHAR
- DATE
- DATETIME
- LARGEINT
- DECIMAL
- BOOL
1.3 Bitmap索引的使用
创建索引
mysql> create index if not exists click_bitmap_index on test_db.click (user_id) using bitmap comment 'bitmap index test'; Query OK, 0 rows affected (0.05 sec) mysql>
查看索引
mysql> show index from test_db.click; +-------------------------------+------------+--------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+-------------------+ | Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | +-------------------------------+------------+--------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+-------------------+ | default_cluster:test_db.click | | click_bitmap_index | | user_id | | | | | | BITMAP | bitmap index test | +-------------------------------+------------+--------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+-------------------+ 1 row in set (0.04 sec) mysql>
删除索引
mysql> drop index if exists click_bitmap_index on test_db.click; Query OK, 0 rows affected (0.03 sec) mysql>
2. BloomFilter索引
2.1 BloomFilter索引介绍
是一种多哈希函数映射的快速查找算法,本质上是一种位图结构。通常应用在一些需要快速判断某个元素是否属于集合,但是并不严格要求100%正确的场合,因为BloomFilter会告诉调用者一个元素存在或不存在一个集合。但存在不一定准确
2.2 BloomFilter原理
实际上是由一个超长的二进制位数组和一系列的哈希函数组成。二进制位数组初始全部为0,当给定一个元素时,这个元素会被一系列哈希函数计算映射出一系列的值,所有的值在位数组的偏移量处置为1。而对于一个待查询的元素,也会用相同的哈希函数映射到位数组上,只要有一个哈希函数映射没有命中之前的元素的偏移量,则不存在于集合中
下图所示出一个m=18, k=3(m是该Bit数组的大小,k是Hash函数的个数)的Bloom Filter示例。集合中的x、y、z三个元素通过3个不同的哈希函数散列到位数组中。当查询元素w时,通过Hash函数计算之后因为有一个比特为0,因此w不在该集合中
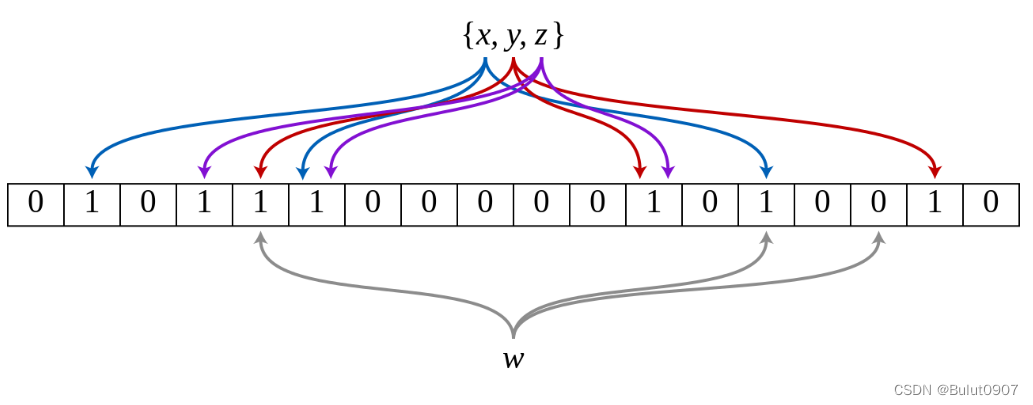
BloomFilter索引也是以Block为粒度创建的。每个Block中,指定列的值作为一个集合生成一个BloomFilter索引条目,用于在查询是快速过滤不满足条件的数据
2.3 BloomFilter索引的使用
创建表使用BloomFilter索引
mysql> create table order_tb(
-> user_id bigint,
-> order_date date,
-> city varchar(32),
-> url varchar(512)
-> ) distributed by hash(user_id, city) buckets 8
-> properties(
-> 'bloom_filter_columns'='user_id,order_date'
-> );
Query OK, 0 rows affected (0.07 sec)
mysql>
查看BloomFilter索引
mysql> show create table order_tb;
删除BloomFilter索引
mysql> alter table test_db.order_tb set ('bloom_filter_columns' = '');
Query OK, 0 rows affected (0.05 sec)
mysql>
修改BloomFilter索引
mysql> alter table test_db.order_tb set ('bloom_filter_columns' = 'user_id,city');
Query OK, 0 rows affected (0.05 sec)
mysql>
2.4 Doris BloomFilter使用场景
- 首先BloomFilter适用于非前缀过滤
- 查询会根据该列高频过滤,而且查询条件大多是in和=过滤
- 不同于Bitmap, BloomFilter适用于高基数列。比如UserID。因为如果创建在低基数的列上,比如”性别“列,则每个Block几乎都会包含所有取值,导致BloomFilter索引失去意义
2.5 Doris BloomFilter使用注意事项
- 不支持对Tinyint、Float、Double 类型的列建Bloom Filter索引
- Bloom Filter索引只对in和=过滤查询有加速效果
- 如果要查看某个查询是否命中了Bloom Filter索引,可以通过查询的Profile信息查看
到此这篇关于Apache Doris的Bitmap索引和BloomFilter索引使用的文章就介绍到这了,更多相关Apache Doris索引内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
apache禁止搜索引擎收录、网络爬虫采集的配置方法
Apache中禁止网络爬虫,之前设置了很多次的,但总是不起作用,原来是是写错了,不能写到Dirctory中,要写到Location中 复制代码 代码如下: <Location /> SetEnvIfNoCase User-Agent "spider" bad_bot BrowserMatchNoCase bingbot bad_bot BrowserMatchNoCase Googlebot bad_bot Order Deny,Allow #下面是禁止soso的爬虫 De
-
禁止apache显示目录索引的常见方法(apache禁止列目录)
禁止Apache显示目录索引,禁止Apache显示目录结构列表,禁止Apache浏览目录,这是网上提问比较多的,其实都是一个意思.下面说下禁止禁止Apache显示目录索引的常见的3种方法.要实现禁止Apache显示目录索引,只需将 Option 中的 Indexes 去掉即可. 1)修改目录配置: 复制代码 代码如下: <Directory "D:/Apache/blog.phpha.com">Options Indexes FollowSymLinks # 修改为: Op
-

Apache Doris的Bitmap索引和BloomFilter索引使用及注意事项
目录 1. Bitmap索引的使用 1.1 Bitmap索引介绍 1.2 Bitmap索引使用的注意事项 1.3 Bitmap索引的使用 2. BloomFilter索引 2.1 BloomFilter索引介绍 2.2 BloomFilter原理 2.3 BloomFilter索引的使用 2.4 Doris BloomFilter使用场景 2.5 Doris BloomFilter使用注意事项 1. Bitmap索引的使用 1.1 Bitmap索引介绍 bitmap index是一种位图索引,是
-
bitmap 索引和 B-tree 索引在使用中如何选择
现在,我们知道优化器如何对这些技术做出反应,清楚地说明 bitmap 索引和 B-tree 索引各自的最好应用. 在 GENDER 列适当地带一个 bitmap 索引,在 SAL 列上创建另外一个位图索引,然后执行一些查询.在这些列上,用 B-tree 索引重新执行查询. 从 TEST_NORMAL 表,查询工资为如下的男员工: 1000 1500 2000 2500 3000 3500 4000 4500 因此: SQL> select * from test_normal 2 where s
-
Apache Doris Join 优化原理详解
目录 背景 & 目标 Doris 数据划分 Partition Bucket Join 方式 总览 Broadcast / Shuffle Join Bucket Shuffle Join Plan Rule Colocate Join Runtime Filter 优化 Join Reorder 优化 Join 调优建议 背景 & 目标 掌握 Apache Doris Join 优化手段及其实现原理 为代码阅读提供理论基础 Doris 数据划分 不同的 Join 方式非常依赖于对 Dor
-
SQLServer性能优化--间接实现函数索引或者Hash索引
SQLServer中没有函数索引,在某些场景下查询的时候要根据字段的某一部分做查询或者经过某种计算之后做查询,如果使用函数或者其他方式作用在字段上之后,就会限制到索引的使用,不过我们可以间接地实现类似于函数索引的功能. 另外一个就是如果查询字段较大或者字段较多的时候,所建立的索引就显得有点笨重,效率也不高,就需要考虑使用一个较小的"替代性"字段做等价替换,类似于Hash索引, 本文粗浅地介绍两种上述两种问题的解决方式,仅供参考. 1,在计算列上建索引,实现"函数索引"
-
详解mysql索引总结----mysql索引类型以及创建
关于MySQL索引的好处,如果正确合理设计并且使用索引的MySQL是一辆兰博基尼的话,那么没有设计和使用索引的MySQL就是一个人力三轮车.对于没有索引的表,单表查询可能几十万数据就是瓶颈,而通常大型网站单日就可能会产生几十万甚至几百万的数据,没有索引查询会变的非常缓慢.还是以WordPress来说,其多个数据表都会对经常被查询的字段添加索引,比如wp_comments表中针对5个字段设计了BTREE索引. 一个简单的对比测试 以我去年测试的数据作为一个简单示例,20多条数据源随机生成200万条
-
MongoDB性能篇之创建索引,组合索引,唯一索引,删除索引和explain执行计划
一.索引 MongoDB 提供了多样性的索引支持,索引信息被保存在system.indexes 中,且默认总是为_id创建索引,它的索引使用基本和MySQL 等关系型数据库一样.其实可以这样说说,索引是凌驾于数据存储系统之上的另一层系统,所以各种结构迥异的存储都有相同或相似的索引实现及使用接口并不足为 奇. 1.基础索引 在字段age 上创建索引,1(升序);-1(降序): db.users.ensureIndex({age:1}) _id 是创建表的时候自动创建的索引,此索引是不能够删除的.当
-
MySQL Hash索引和B-Tree索引的区别
MySQL Hash索引结构的特殊性,其检索效率非常高,索引的检索可以一次定位,不像B-Tree 索引需要从根节点到枝节点,最后才能访问到页节点这样多次的IO访问,所以 Hash 索引的查询效率要远高于 B-Tree 索引. 可 能很多人又有疑问了,既然 Hash 索引的效率要比 B-Tree 高很多,为什么大家不都用 Hash 索引而还要使用 B-Tree 索引呢?任何事物都是有两面性的,Hash 索引也一样,虽然 Hash 索引效率高,但是 Hash 索引本身由于其特殊性也带来了很多限制和弊
-
mysql下普通索引和唯一索引的效率对比
今天在我的虚拟机中布置了环境,测试抓图如下: 抓的这几个都是第一次执行的,刷了几次后,取平均值,效率大致相同,而且如果在一个列上同时建唯一索引和普通索引的话,mysql会自动选择唯一索引. 谷歌一下: 唯一索引和普通索引使用的结构都是B-tree,执行时间复杂度都是O(log n). 补充下概念: 1.普通索引 普通索引(由关键字KEY或INDEX定义的索引)的唯一任务是加快对数据的访问速度.因此,应该只为那些最经常出现在查询条件(WHEREcolumn=)或排序条件(ORDERBYcolumn
-
MySQL中主键索引与聚焦索引之概念的学习教程
主键索引 主键索引,简称主键,原文是PRIMARY KEY,由一个或多个列组成,用于唯一性标识数据表中的某一条记录.一个表可以没有主键,但最多只能有一个主键,并且主键值不能包含NULL. 在MySQL中,InnoDB数据表的主键设计我们通常遵循几个原则: 采用一个没有业务用途的自增属性列作为主键: 主键字段值总是不更新,只有新增或者删除两种操作: 不选择会动态更新的类型,比如当前时间戳等. 这么做的好处有几点: 新增数据时,由于主键值是顺序增长的,innodb page发生分裂的概率降低了:可以
-
MySQL索引之聚集索引介绍
在MySQL里,聚集索引和非聚集索引分别是什么意思,有什么区别? 在MySQL中,InnoDB引擎表是(聚集)索引组织表(clustered index organize table),而MyISAM引擎表则是堆组织表(heap organize table). 也有人把聚集索引称为聚簇索引. 当然了,聚集索引的概念不是MySQL里特有的,其他数据库系统也同样有. 简言之,聚集索引是一种索引组织形式,索引的键值逻辑顺序决定了表数据行的物理存储顺序,而非聚集索引则就是普通索引了,仅仅只是对数据列创