pandas中groupby操作实现
目录
- 一、实验目的
- 二、实验原理
- 三、实验环境
- 四、实验内容
- 五、实验步骤
一、实验目的
熟练掌握pandas中的groupby操作
二、实验原理
groupby(by=None, axis=0, level=None, as_index=True, sort=True, group_keys=True, squeeze=False)
参数说明:
- by是指分组依据(列表、字典、函数,元组,Series)
- axis:是作用维度(0为行,1为列)
- level:根据索引级别分组
- sort:对groupby分组后新的dataframe中索引进行排序,sort=True为升序,
- as_index:在groupby中使用的键是否成为新的dataframe中的索引,默认as_index=True
- group_keys:在调用apply时,将group键添加到索引中以识别片段
- squeeze :如果可能的话,减少返回类型的维数,否则返回一个一致的类型
grouping操作(split-apply-combine)
数据的分组&聚合 – 什么是groupby 技术?
在数据分析中,我们往往需要在将数据拆分,在每一个特定的组里进行运算。比如根据教育水平和年龄段计算某个城市的工作人口的平均收入。
pandas中的groupby提供了一个高效的数据的分组运算。
我们通过一个或者多个分类变量将数据拆分,然后分别在拆分以后的数据上进行需要的计算
我们可以把上述过程理解为三部:
1.拆分数据(split)
2.应用某个函数(apply)
3.汇总计算结果(aggregate)
下面这个演示图展示了“分拆-应用-汇总”的groupby思想

上图所示,分解步骤:
Step1 :数据分组—— groupby 方法
Step2 :数据聚合:
使用内置函数——sum / mean / max / min / count等
使用自定义函数—— agg ( aggregate ) 方法
自定义更丰富的分组运算—— apply 方法
三、实验环境
Python 3.6.1
Jupyter
四、实验内容
练习pandas中的groupby的操作案例
五、实验步骤
1.创建一个数据帧df。
import numpy as np
import pandas as pd
df = pd.DataFrame({'A' : ['foo', 'bar', 'foo', 'bar', 'foo', 'bar', 'foo', 'foo'],'B' : ['one', 'one', 'two', 'three', 'two', 'two', 'one', 'three'],'C' : np.random.randn(8),'D' : np.random.randn(8)})
print(df)

2.通过A列对df进行分布操作。
df.groupby('A')

3.通过A、B列对df进行分组操作。
df.groupby(['A','B'])

4…使用自定义函数进行分组操作,自定义一个函数,使用groupby方法并使用自定义函数给定的条件,按列对df进行分组。
def get_letter_type(letter):
if letter.lower() in 'aeiou':
return 'vowel'
else:
return 'consonant'
grouped = df.groupby(get_letter_type, axis=1)
for group in grouped:
print(group)

5.创建一个Series名为s,使用groupby根据s的索引对s进行分组,返回分组后的新Series,对新Series进行first、last、sum操作。
lst = [1, 2, 3, 1, 2, 3] s = pd.Series([1, 2, 3, 10, 20, 30], lst) grouped = s.groupby(level=0) #查看分组后的第一行数据 grouped.first() #查看分组后的最后一行数据 grouped.last() #对分组的各组进行求和 grouped.sum()

6.分组排序,使用groupby进行分组时,默认是按分组后索引进行升序排列,在groupby方法中加入sort=False参数,可以进行降序排列。
df2=pd.DataFrame({'X':['B','B','A','A'],'Y':[1,2,3,4]})
#按X列对df2进行分组,并求每组的和
df2.groupby(['X']).sum()
#按X列对df2进行分组,分组时不对键进行排序,并求每组的和
df2.groupby(['X'],sort=False).sum()

7.使用get_group方法得到分组后某组的值。
df3 = pd.DataFrame({'X' : ['A', 'B', 'A', 'B'], 'Y' : [1, 4, 3, 2]})
#按X列df3进行分组,并得到A组的df3值
df3.groupby(['X']).get_group('A')
#按X列df3进行分组,并得到B组的df3值
df3.groupby(['X']).get_group('B')

8.使用groups方法得到分组后所有组的值。
df.groupby('A').groups
df.groupby(['A','B']).groups

9.多级索引分组,创建一个有两级索引的Series,并使用两个方法对Series进行分组并求和。
arrays = [['bar', 'bar', 'baz', 'baz', 'foo', 'foo', 'qux', 'qux'],['one', 'two', 'one', 'two', 'one', 'two', 'one', 'two']] index=pd.MultiIndex.from_arrays(arrays,names=['first','second']) s=pd.Series(np.random.randn(8),index=index) s.groupby(level=0).sum() s.groupby(level='second').sum()

10.复合分组,对s按first、second进行分组并求和。
s.groupby(level=['first', 'second']).sum()

11.复合分组(按索引和列),创建数据帧df,使用索引级别和列对df进行分组。
arrays = [['bar', 'bar', 'baz', 'baz', 'foo', 'foo', 'qux', 'qux'],['one', 'two', 'one', 'two', 'one', 'two', 'one', 'two']]
index = pd.MultiIndex.from_arrays(arrays, names=['first', 'second'])
df = pd.DataFrame({'A': [1, 1, 1, 1, 2, 2, 3, 3], 'B': np.arange(8)},index=index)
print(df)
df.groupby([pd.Grouper(level=1),'A']).sum()

12.对df进行分组,将分组后C列的值赋值给grouped,统计grouped中每类的个数。
df = pd.DataFrame({'A' : ['foo', 'bar', 'foo', 'bar', 'foo', 'bar', 'foo', 'foo'],'B' : ['one', 'one', 'two', 'three', 'two', 'two', 'one', 'three'],'C' : np.random.randn(8),'D' : np.random.randn(8)})
grouped=df.groupby(['A'])
grouped_C=grouped['C']
print(grouped_C.count())

13.对上面创建的df的C列,按A列值进行分组并求和。
df['C'].groupby(df['A']).sum()

14.遍历分组结果,通过A,B两列对df进行分组,分组结果的组名为元组。
for name, group in df.groupby(['A', 'B']):
print(name)
print(group)

15.通过A列对df进行分组,并查看分组对象的bar列。
df.groupby(['A']).get_group(('bar'))

16.按A,B两列对df进行分组,并查看分组对象中bar、one都存在的部分。
df.groupby(['A','B']).get_group(('bar','one'))

注意:当分组按两列来分时,查看分组对象也应该包含每列的一部分。
17.聚合操作,按A列对df进行分组,使用聚合函数aggregate求每组的和。
grouped=df.groupby(['A']) grouped.aggregate(np.sum)

按A、B两列对df进行分组,并使用聚合函数aggregate对每组求和。
grouped=df.groupby(['A']) grouped.aggregate(np.sum)

注意:通过上面的结果可以看到。聚合完成后每组都有一个组名作为新的索引,使用as_index=False可以忽略组名。
18.当as_index=True时,在groupby中使用的键将成为新的dataframe中的索引。按A、B两列对df进行分组,这是使参数as_index=False,再使用聚合函数aggregate求每组的和.
grouped=df.groupby(['A','B'],as_index=False) grouped.aggregate(np.sum)

19.聚合操作,按A、B列对df进行分组,使用size方法,求每组的大小。返回一个Series,索引是组名,值是每组的大小。
grouped=df.groupby(['A','B']) grouped.size()

20.聚合操作,对分组grouped进行统计描述。
grouped.describe()
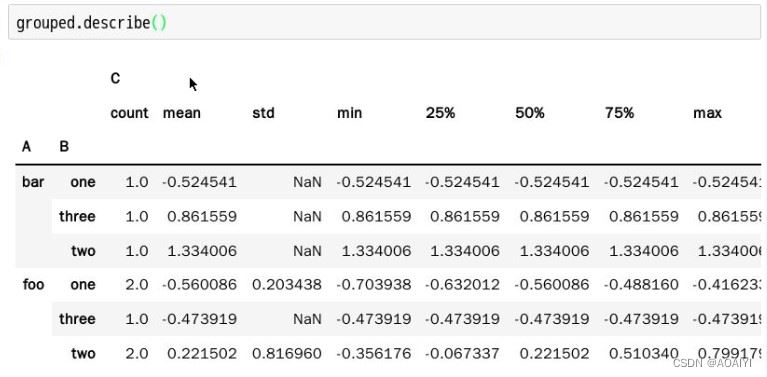
注意:聚合函数可以减少数据帧的维度,常用的聚合函数有:mean、sum、size、count、std、var、sem 、describe、first、last、nth、min、max。
执行多个函数在一个分组结果上:在分组返回的Series中我们可以通过一个聚合函数的列表或一个字典去操作series,返回一个DataFrame。
到此这篇关于pandas中groupby操作实现的文章就介绍到这了,更多相关pandas groupby操作内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Pandas高级教程之Pandas中的GroupBy操作
目录 简介 分割数据 多index get_group dropna groups属性 index的层级 group的遍历 聚合操作 通用聚合方法 可以同时指定多个聚合方法: NamedAgg 不同的列指定不同的聚合方法 转换操作 过滤操作 Apply操作 简介 pandas中的DF数据类型可以像数据库表格一样进行groupby操作.通常来说groupby操作可以分为三部分:分割数据,应用变换和和合并数据. 本文将会详细讲解Pandas中的groupby操作. 分割数据 分割数据的目的是将DF分
-
pandas数据预处理之dataframe的groupby操作方法
在数据预处理过程中可能会遇到这样的问题,如下图:数据中某一个key有多组数据,如何分别对每个key进行相同的运算? dataframe里面给出了一个group by的一个操作,对于"group by"操作,我们通常是指以下一个或多个操作步骤: l (Splitting)按照一些规则将数据分为不同的组: l (Applying)对于每组数据分别执行一个函数: l (Combining)将结果组合到一个数据结构中: 使用dataframe实现groupby的用法: # -*- coding
-
pandas中groupby操作实现
目录 一.实验目的 二.实验原理 三.实验环境 四.实验内容 五.实验步骤 一.实验目的 熟练掌握pandas中的groupby操作 二.实验原理 groupby(by=None, axis=0, level=None, as_index=True, sort=True, group_keys=True, squeeze=False) 参数说明: by是指分组依据(列表.字典.函数,元组,Series) axis:是作用维度(0为行,1为列) level:根据索引级别分组 sort:对group
-
Pandas中GroupBy具体用法详解
目录 简介 分割数据 多index get_group dropna groups属性 index的层级 group的遍历 聚合操作 通用聚合方法 同时使用多个聚合方法 NamedAgg 不同的列指定不同的聚合方法 转换操作 过滤操作 Apply操作 简介 pandas中的DF数据类型可以像数据库表格一样进行groupby操作.通常来说groupby操作可以分为三部分:分割数据,应用变换和和合并数据. 本文将会详细讲解Pandas中的groupby操作. 分割数据 分割数据的目的是将DF分割成为
-
详解Pandas中GroupBy对象的使用
目录 使用 Groupby 三个步骤 将原始对象拆分为组 按组应用函数 Aggregation Transformation Filtration 整合结果 总结 今天,我们将探讨如何在 Python 的 Pandas 库中创建 GroupBy 对象以及该对象的工作原理.我们将详细了解分组过程的每个步骤,可以将哪些方法应用于 GroupBy 对象上,以及我们可以从中提取哪些有用信息 不要再观望了,一起学起来吧 使用 Groupby 三个步骤 首先我们要知道,任何 groupby 过程都涉及以下
-
Pandas中DataFrame常用操作指南
目录 前言 1. 基本使用: 2. 数据select, del, update. 3.运算. 4. Group by 操作. 5. 导出到csv文件 总结 前言 Pandas是Python下一个开源数据分析的库,它提供的数据结构DataFrame极大的简化了数据分析过程中一些繁琐操作. 1. 基本使用: 创建DataFrame. DataFrame是一张二维的表,大家可以把它想象成一张Excel表单或者Sql表. Excel 2007及其以后的版本的最大行数是1048576,最大列数是16384
-
python pandas中DataFrame类型数据操作函数的方法
python数据分析工具pandas中DataFrame和Series作为主要的数据结构. 本文主要是介绍如何对DataFrame数据进行操作并结合一个实例测试操作函数. 1)查看DataFrame数据及属性 df_obj = DataFrame() #创建DataFrame对象 df_obj.dtypes #查看各行的数据格式 df_obj['列名'].astype(int)#转换某列的数据类型 df_obj.head() #查看前几行的数据,默认前5行 df_obj.tail() #查看后几
-
Python pandas 列转行操作详解(类似hive中explode方法)
最近在工作上用到Python的pandas库来处理excel文件,遇到列转行的问题.找了一番资料后成功了,记录一下. 1. 如果需要爆炸的只有一列: df=pd.DataFrame({'A':[1,2],'B':[[1,2],[1,2]]}) df Out[1]: A B 0 1 [1, 2] 1 2 [1, 2] 如果要爆炸B这一列,可以直接用explode方法(前提是你的pandas的版本要高于或等于0.25) df.explode('B') A B 0 1 1 1 1 2 2 2 1 3
-

Pandas中的 transform()结合 groupby()用法示例详解
首先,假设我们有如下餐厅数据集: import pandas as pd df = pd.DataFrame({ 'restaurant_id': [101,102,103,104,105,106,107], 'address': ['A','B','C','D', 'E', 'F', 'G'], 'city': ['London','London','London','Oxford','Oxford', 'Durham', 'Durham'], 'sales': [10,500,48,12,2
-
pandas中pd.groupby()的用法详解
在pandas中的groupby和在sql语句中的groupby有异曲同工之妙,不过也难怪,毕竟关系数据库中的存放数据的结构也是一张大表罢了,与dataframe的形式相似. import numpy as np import pandas as pd from pandas import Series, DataFrame df = pd.read_csv('./city_weather.csv') print(df) ''' date city temperature
-
Pandas中Series的属性,方法,常用操作使用案例
目录 1. Series 对象的创建 1.1 创建一个空的 Series 对象 1.2 通过列表创建一个 Series 对象 1.3 通过元组创建一个 Series 对象 1.4 通过字典创建一个 Series 对象 1.5 通过 ndarray 创建一个 Series 对象 1.6 创建 Series 对象时指定索引 1.7 通过一个标量(数)创建一个 Series 对象 2. Series 的属性 2.1 values ---- 返回一个 ndarray 数组 2.2 index ----