Python爬虫之对CSDN榜单进行分析
前言
本篇文章的主要内容是利用Python对CSDN热榜变冷榜的指标数据进行分析的爬虫
分析一下各指标
开始爬取热榜,请稍候...
耗时:2.199401808s
【Top100指标统计】
浏览为0的: 3
评论为0的: 76
收藏为0的: 51
浏览评论0的: 3
三指标都0的: 2
浏览个位数的: 25
评论个位数的: 98
收藏个位数的: 86
无封面题图的: 74
浏览>=100的: 18
评论>=10的: 1
收藏>=10的: 13
【Top50指标统计】
浏览为0的: 0
评论为0的: 36
收藏为0的: 22
浏览评论0的: 0
三指标都0的: 0
浏览个位数的: 15
评论个位数的: 49
收藏个位数的: 39
无封面题图的: 38
浏览>=200的: 12
评论>=20的: 0
收藏>=20的: 8
开始爬取Top100网页,请稍候(大约1分钟)...
耗时:50.254692171s
下载失败数:0
【Top100博客等级分布】
等级 1: 11
等级 2: 12
等级 3: 22
等级 4: 20
等级 5: 21
等级 6: 3
等级 7: 7
等级 8: 3
【Top100作者码龄分布】
码龄 0: 15
码龄 1: 14
码龄 2: 23
码龄 3: 12
码龄 4: 13
码龄 5: 12
码龄 6: 4
码龄 7: 2
码龄10: 1
码龄12: 1
码龄13: 1
码龄-1: 1
【Top100作者周排名分布】
周榜前100名 : 5
第100~200名 : 2
第200~500名 : 8
第500~1千名 : 5
第1千~5千名 : 17
第5千~1万名 : 14
第1万~2万名 : 7
第2万~5万名 : 10
第5万~10万名 : 11
10万名之后 : 20
代码:
from requests import get
from bs4 import BeautifulSoup as bs
from win32com.shell import shell
from datetime import datetime as dt
from time import perf_counter
from re import findall
def lenB(str):
t = 0
for s in str:
if '\u4e00' <= s <= '\u9fef': t += 1
return t
def reportTime():
d = dt.today()
return f'{d.year}-{d.month:02}-{d.day:02} {d.hour:02}:{d.minute:02}'
def reportData(Index, num=0):
count = [0,0,0,0,0,0]
for i in Index:
if i[0] <= num : count[0]+=1
if i[1] <= num : count[1]+=1
if i[2] <= num : count[2]+=1
if sum(i[:2]) <= num : count[3]+=1
if sum(i[:3]) <= num : count[4]+=1
if i[-1]: count[-1]+=1
return count
def reportData2(Index):
count = [0,0,0,0,0,0]
out1,out2 = (200,20,20),(100,10,10)
for i in Index:
if i[0] >= out1[0] : count[0]+=1
if i[0] >= out2[0] : count[1]+=1
if i[1] >= out1[1] : count[2]+=1
if i[1] >= out2[1] : count[3]+=1
if i[2] >= out1[2] : count[4]+=1
if i[2] >= out2[2] : count[5]+=1
return count
def reportString(count):
outStr = f'浏览为0的:\t{count[0]}\n评论为0的:\t'
outStr += f'{count[1]}\n收藏为0的:\t{count[2]}\n'
outStr += f'浏览评论0的:\t{count[3]}\n'
outStr += f'三指标都0的:\t{count[4]}\n'
return outStr
def reportString2(count):
outStr = f'浏览个位数的:\t{count[0]}\n'
outStr += f'评论个位数的:\t{count[1]}\n'
outStr += f'收藏个位数的:\t{count[2]}\n'
outStr += f'无封面题图的:\t{count[-1]}\n'
return outStr
def reportString3(count,idx=0):
out1,out2 = (200,20,20),(100,10,10)
if idx==0: out = out1
else: idx=1; out = out2
outStr = f'浏览>={out[0]}的:\t{count[idx]}\n'
outStr += f'评论>={out[1]}的:\t{count[idx+2]}\n'
outStr += f'收藏>={out[2]}的:\t{count[idx+4]}\n'
return outStr
def dictFromList(Values,num=5):
tags,tagDict = [],dict()
if num==5:
for tag in Values:
tags.extend(list(tag[num]))
else:
for tag in Values:
tags.append(tag[num])
Tags = list(set(tags))
for t in Tags:
tagDict[str(t)] = tags.count(t)
return tagDict
def matchRange(value):
if 0<value<=100: res = 0
elif 100<value<=200: res = 1
elif 200<value<=500: res = 2
elif 500<value<=1000: res = 3
elif 1000<value<=5000: res = 4
elif 5000<value<=10000: res = 5
elif 10000<value<=20000: res = 6
elif 20000<value<=50000: res = 7
elif 50000<value<=100000: res = 8
else: res = 9
return res
if __name__ == '__main__':
desktop = shell.SHGetFolderPath(0, 25, None, 0)
filename = r'\【CSDN排行榜Top100】'+reportTime()[:10]+'.txt'
output = desktop + filename
tofile = open(output,'w',encoding='utf-8')
rank,ids,articles,index = [],[],[],[]
print('\n开始爬取热榜,请稍候...')
print('\n【CSDN 综合热榜】:\n', file=tofile)
agent = 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.'
agent += '36 (KHTML, like Gecko) Chrome/85.0.4183.83 Safari/537.36'
website = 'https://blog.csdn.net/phoenix/web/blog/'
for i in range(4):
url = website + f'hotRank?page={i}&pageSize=25'
res = get(url,headers={'User-Agent':agent}).json()
if res["code"] == 200:
data = res["data"]
rank += [r for r in data]
print(f'耗时:{perf_counter()}s\n')
rank = [[v for i,v in r.items()] for r in rank]
for i,r in enumerate(rank):
d,m = divmod(i,25)
if m==0:
count = 0
print(f'【{d*25+1}到{d*25+25}名】:\n', file=tofile)
if r[5].lower():
count += 1
ids.append(r[5])
articles.append(r[7])
print(f'★№{i+1:02}:{r[3]} (热度:{r[0]})\n○《{r[6]}》', file=tofile)
print(f'◎ 浏览:{r[-5]} 评论:{r[-4]} 收藏:{r[-3]}', file=tofile)
print(f'¤ {r[7]}\n', file=tofile)
index.append((int(r[-3]),int(r[-5]),int(r[-4]),int(r[0]),r[-1]==[]))
count1 = reportData(index)
outStr1 = '【Top100指标统计】\n\n'
outStr1 += reportString(count1)
count1_2 = reportData(index,9)
outStr1_2 = reportString2(count1_2)
count1_3 = reportData2(index)
outStr1_3 = reportString3(count1_3,1)
print(outStr1, file=tofile)
print(outStr1_2, file=tofile)
print(outStr1_3, file=tofile)
count2 = reportData(index[:50])
outStr2 = '【Top50指标统计】\n\n'
outStr2 += reportString(count2)
count2_2 = reportData(index[:50],9)
outStr2_2 = reportString2(count2_2)
count2_3 = reportData2(index)
outStr2_3 = reportString3(count1_3)
print(outStr2, file=tofile)
print(outStr2_2, file=tofile)
print(outStr2_3, file=tofile)
#标题关键字,可根据需要自行添加
keywords = ('C++','C语言','Python','JAVA','Delphi','C#','mysql','HTML',
'Matlab','Unity','Spring','Nginx',
'Windows','Linux','Android','Ubuntu',
'框架','算法','对象','函数','爬虫')
kwIndex = []
for _ in range(len(keywords)): kwIndex.append(0)
for title in rank:
for i,kw in enumerate(keywords):
if kw.lower() in title[6].lower():
kwIndex[i] += 1
outStr3 = '\n【Top100标题常见关键字统计】\n\n'
for i,kw in enumerate(kwIndex):
if i==1: kwi,kws = kw + kwIndex[0],'C/C++'
else: kwi,kws = kw,keywords[i].title()
if i>=1 and kwi>0:
outStr3 += f'{kws:<{10-lenB(kws)}}: {kwi}\n'
'''
#字典形式可以排序
kwDict = dict()
for i,kw in enumerate(keywords): kwDict[kw] = kwIndex[i]
for item in sorted(kwDict.items(),key=lambda k:k[1],reverse=True):
if not item[1]: print();break
print(f'{item[0]:<{10-lenB(item[0])}}: {item[1]}')
'''
print(outStr1 + '\n' + outStr1_2 + '\n' + outStr1_3)
print(outStr2 + '\n' + outStr2_2 + '\n' + outStr2_3)
#爬取Top100资料
Values = []
print('开始爬取Top100网页,请稍候(大约1分钟)...')
timer = perf_counter()
for idx,url in enumerate(articles):
res = get(url,headers={'User-Agent':agent})
res.encoding='uft-8'
soup = bs(res.text,'html.parser')
value = []
for i in range(3,8):
if i!=4: value.append(rank[idx][i])
try: #码龄
ctxt = 'personal-home-page personal-home-years'
html = soup.find('span',class_=ctxt)
value.append(int(findall(r'\d+',html.text)[0]))
except: value.append(-1)
try: #标签
ctxt = 'tags-box artic-tag-box'
html = soup.find('div',class_=ctxt)
html = html.find_all('a')
value.append(set([i.text.strip().lower().title() for i in html]))
except: value.append(set())
html = soup.find_all('dl')
for dl in range(1,len(html)):
try: dlval = html[dl]['title']
except: break
if '级' in dlval: dlval = dlval[:dlval.find('级')]
if '暂无排名' in dlval: dlval = -1
value.append(int(dlval))
if len(value)==16: value.append(False)
else: value.append(True)
Values.append(value)
print(f'耗时:{perf_counter()-timer}s')
datafile = desktop + r'\【CSDN排行榜Top100】data'+reportTime()[:10]+'.txt'
#收集到的数据全部写入文件*data*.txt
failVals = 0
with open(datafile,'w',encoding='utf-8') as f:
f.write(f'#报告日期:{reportTime()}\n')
for val in Values:
if val[-1]:
failVals += 1
continue
f.writelines('|'.join([str(i) for i in val]))
f.write('\n')
Values = [val for val in Values if not val[-1]]
print(f'下载失败数:{failVals}\n')
'''value列表各元素的索引值分别代表:
0~ 5:昵称 用户名 标题 链接 码龄 文章标签
6~10:原创 周排名 总排名 访问 等级
11~15:积分 粉丝 获赞 评论 收藏
16: 失败标记=False'''
#输出内容
tagsRank,tagDict = [],dictFromList(Values)
for item in sorted(tagDict.items(),key=lambda t:t[1],reverse=True):
tagsRank.append(f'{item[0]:<{22-lenB(item[0])}}: {item[1]}')
if len(tagsRank)>=100: break
outStr4 = lambda x:f'\n【Top100文章标签排名(Top{x})】\n'
outStr5 = '\n【Top100博客等级分布】\n\n'
valDict = dictFromList(Values,10)
for key,value in valDict.items():
outStr5 += f'等级{key:>2}: {value}\n'
print(outStr5, file=tofile)
outStr6 = '\n【Top100作者码龄分布】\n\n'
valDict = dictFromList(Values,4)
for key,value in valDict.items():
outStr6 += f'码龄{key:>2}: {value}\n'
print(outStr6, file=tofile)
outStr7 = '\n【Top100作者周排名分布】\n\n'
valDict = dictFromList(Values,7)
weekRank = [0 for _ in range(10)]
for key,value in valDict.items():
weekRank[matchRange(int(key))] += 1
textRank = ('周榜前100名','第100~200名','第200~500名','第500~1千名','第1千~5千名',
'第5千~1万名','第1万~2万名','第2万~5万名','第5万~10万名','10万名之后')
for i,txt in enumerate(textRank):
outStr7 += f'{txt:<{14-lenB(txt)}}: {weekRank[i]}\n'
print(outStr7, file=tofile)
#更多指标可用以分析或者画折线图柱形图等等,指标索引见上面的注释
print(outStr5 + outStr6 + outStr7)
print(f'更多详情见桌面文件:\n{filename[1:]}')
endStr = '='*26
endStr += f'\n报告日期:{reportTime()[:10]}'
endStr += f'\n报告时间:{reportTime()[11:]}'
endStr += f'\n程序耗时:{round(perf_counter(),2)}s\n'
print(outStr3, file=tofile)
print(outStr4(100), file=tofile)
for t in tagsRank: print(t, file=tofile)
print(endStr, file=tofile)
tofile.close()
print(endStr)
''' 运行环境: Windows7 + Python3.8.8 '''
''' Written by Hann, 2021.10.25 '''
代码比较乱,这就是业余风格⊙﹏⊙‖∣ 程序一共抓取了16种信息,可以根据需要,增加对其他各种数据时行分析。比如,还能用matplotlib来把数据画成图表:
例一:
Top100的热度衰减表
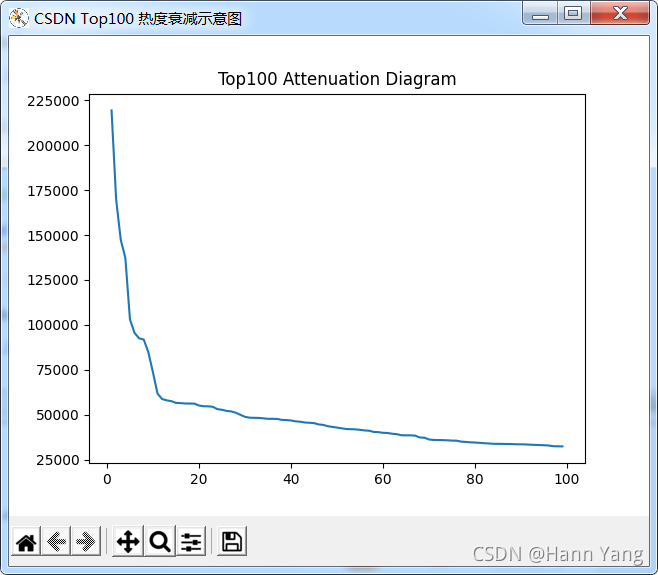
import matplotlib.pyplot as plt
plt.figure().canvas.set_window_title('CSDN Top100 热度衰减示意图')
plt.title('Top100 Attenuation Diagram')
hots = [h[3] for h in index]
x = [i+1 for i in range(len(hots))]
plt.plot(x, hots)
plt.show()
例二:
Top100 博客等级分布图
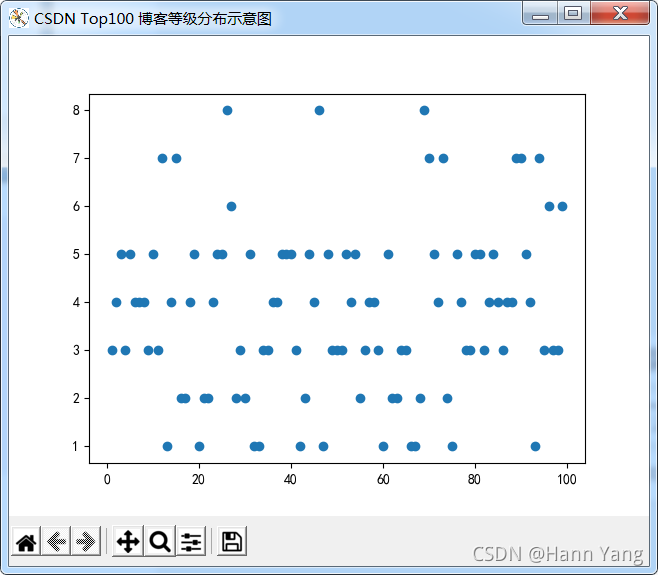
import matplotlib.pyplot as plt
plt.figure().canvas.set_window_title('CSDN Top100 博客等级分布示意图')
Level = [i[10] for i in Values]
x = [i+1 for i in range(len(Level))]
plt.scatter(x, Level,marker='o')
plt.show()
注: 以上两代码中的 index 和 Values 两个列表是原爬虫程序中的全局变量,为省事我直接用了。同样的还有一个变量tagDict可以直接拿来用的:
tagDict
{'红书《题目与解读》': 1, '# Java Web': 1, '负载均衡': 1, 'String': 1, 'Html': 1, '编程入门': 1, 'Python爬虫': 1, '原力计划': 5, 'React.Js': 1, '模板': 1, 'Flutter': 1, 'Python Qt': 1, 'Leetcode题解集锦': 1, '搜索引擎': 1, '基础知识': 1, '后端': 8, 'Flutter骚操作': 1, 'Spring Boot': 2, 'Elasticsearch': 3, '架构': 1, 'Database': 3, 'Nginx': 3, '1024程序员节': 23, 'Waf攻防': 1, '计算机网络': 1, '程序员生存技能': 1, '二叉树': 1, '泛型类': 1, '日期工具类': 1, '拍卖': 1, 'Web前端': 1, 'Date': 1, '排序算法': 2, 'Javascript': 9, '源码分析': 1, '数据分析': 1, '大数据': 3, 'Linux': 6, '数据库': 5, 'Pycharm': 1, 'Vue.Js': 5, '操作系统': 2, '单片机': 1, '生活感悟': 1, 'Java成神之路之设计模式': 1, 'Create-Vue': 1, '蓝桥杯': 1, '贪心': 1, '【详细注释】数据结构与算法': 1, '项目': 1, 'Matlab': 1, 'Jdbc': 1, '微信小程序': 1, '# 中间件': 1, 'Bash': 1, 'Leetcode': 3, '同步': 1, '数据库应用': 1, '栈': 1, 'Language': 1, '开发语言': 10, 'Jwt': 1, 'Css': 3, 'Mysql': 1, '操作系统篇': 1, 'Vj': 1, 'Sqlite': 1, 'Java基础': 1, 'Spring': 4, '计算机网络养成': 1, '机器人': 1, 'Centos': 1, '机器视觉': 1, 'Kube-Controller-Manager': 1, '网络编程专题': 1, '从零开始Python+微信小程序开发': 1, 'C语言': 4, 'Spring Security': 1, '泛型': 1, '面试': 1, 'Elastic': 1, '读论文': 1, '数据处理': 1, '服务器': 3, '重学Java高并发': 1, '云原生': 1, 'Java': 25, '线性回归': 1, '基数排序': 1, '网络': 2, 'Rabbitmq': 1, 'Js': 1, '上位机': 1, 'Java基础概要': 1, 'React系列': 1, 'Qt': 1, '分类': 1, '网络协议': 1, '多线程': 1, '数据库开发': 1, 'Vue': 4, 'Jvm': 1, '常用算法考题': 1, '跨域': 1, 'Visio': 1, 'Es6': 2, '源码': 1, 'Synchronized': 1, '算法之力扣系列': 1, '老王和他的It界朋友们': 1, 'C++语言': 1, '进程管理': 1, '层序遍历': 1, 'Wireshark': 1, '知识点': 1, '经验分享': 1, 'Javascript百炼成仙(试读)': 1, 'Hibernate': 1, '运维': 2, '数据结构与算法': 1, '双指针': 1, '教程': 1, 'Python': 8, '# Python科学计算基础': 1, '编译原理': 1, 'Big Data': 2, '数据结构': 2, '程序人生': 1, 'Linux相关命令': 1, '单调栈': 1, '图像处理': 2, 'Oauth2': 1, 'Qclipboard': 1, 'Jupyter': 1, 'Lintcode算法': 1, 'Opengauss经验总结': 1, 'C++': 5, 'Springboot': 2, '算法设计': 1, 'Redis': 2, '刷题笔记': 1, '杂文': 1, 'Ecmascript': 2, 'Linux学习': 1, '剪贴数据类': 1, '基于Matlab与Fpga的数字图像处理': 1, '前端': 9, 'Opencv': 2, 'Android项目记录': 1, '人工智能学习之路': 1, '算法': 8, '分布式事务': 1, 'Epoll': 1, '复习': 1, 'Http': 1, 'C语言笔记': 1, 'Anaconda': 1, '计算机视觉': 1, '其他': 1, 'Npm': 1, 'Sso': 1, 'Gui设计': 1, 'Array': 1, '笔记': 3, '安装': 1, 'Kubernetes': 1, 'Sqlserver': 1, '泛型方法': 1, '# Spring': 1, '分布式': 1, 'Ros机械臂': 1, 'Docker': 1, '链表': 1, 'Css3': 2, 'Android': 1, '微服务': 1, 'Python计算机视觉': 1, '分布式&Amp;高并发': 1, '排序': 1}
这个变量可以用模块wordcloud (中文分词需要jieba模块配合)加工一下,生成Top100热榜文章的标签词云图。(本篇完)
到此这篇关于Python爬虫之对CSDN榜单进行分析的文章就介绍到这了,更多相关Python爬虫案例内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Python爬虫之Scrapy环境搭建案例教程
Python爬虫之Scrapy环境搭建 如何搭建Scrapy环境 首先要安装Python环境,Python环境搭建见:https://blog.csdn.net/alice_tl/article/details/76793590 接下来安装Scrapy 1.安装Scrapy,在终端使用pip install Scrapy(注意最好是国外的环境) 进度提示如下: alicedeMacBook-Pro:~ alice$ pip install Scrapy Collecting Scrapy Usi
-

Python爬虫入门案例之回车桌面壁纸网美女图片采集
目录 知识点 环境 目标网址: 爬虫代码 导入模块 发送网络请求 获取网页源代码 提取每个相册的详情页链接地址 替换所有的图片链接 换成大图 保存图片 图片名字 翻页 爬取结果 知识点 requests parsel re os 环境 python3.8 pycharm2021 目标网址: https://mm.enterdesk.com/bizhi/63899-347866.html [付费VIP完整版]只要看了就能学会的教程,80集Python基础入门视频教学 点这里即可免费在线观看 注意:
-
Python爬虫实战案例之爬取喜马拉雅音频数据详解
前言 喜马拉雅是专业的音频分享平台,汇集了有声小说,有声读物,有声书,FM电台,儿童睡前故事,相声小品,鬼故事等数亿条音频,我最喜欢听民间故事和德云社相声集,你呢? 今天带大家爬取喜马拉雅音频数据,一起期待吧!! 这个案例的视频地址在这里 https://v.douyu.com/show/a2JEMJj3e3mMNxml 项目目标 爬取喜马拉雅音频数据 受害者地址 https://www.ximalaya.com/ 本文知识点: 1.系统分析网页性质 2.多层数据解析 3.海量音频数据保存 环境
-
python爬虫线程池案例详解(梨视频短视频爬取)
python爬虫-梨视频短视频爬取(线程池) 示例代码 import requests from lxml import etree import random from multiprocessing.dummy import Pool # 多进程要传的方法,多进程pool.map()传的第二个参数是一个迭代器对象 # 而传的get_video方法也要有一个迭代器参数 def get_video(dic): headers = { 'User-Agent':'Mozilla/5.0 (Wind
-
Python爬虫采集Tripadvisor数据案例实现
目录 前言 第三方库 开发环境 开始代码 请求数据 2. 获取数据(网页源代码) 3. 解析数据(提取我们想要的数据内容 详情页链接) 4. 发送请求(访问所有的详情页链接) 获取数据 5. 解析数据 6.保存数据 7.得到数据 前言 Tripadvisor是全球领先的旅游网站,主要提供来自全球旅行者的点评和建议,全面覆盖全球的酒店.景点.餐厅.航空公司 ,以及旅行规划和酒店.景点.餐厅预订功能.Tripadvisor及旗下网站在全球49个市场设有分站,月均独立访问量达4.15亿. 第三方库 r
-
python爬虫系列网络请求案例详解
学习了之前的基础和爬虫基础之后,我们要开始学习网络请求了. 先来看看urllib urllib的介绍 urllib是Python自带的标准库中用于网络请求的库,无需安装,直接引用即可. 主要用来做爬虫开发,API数据获取和测试中使用. urllib库的四大模块: urllib.request: 用于打开和读取url urllib.error : 包含提出的例外,urllib.request urllib.parse:用于解析url urllib.robotparser:用于解析robots.tx
-
Python7个爬虫小案例详解(附源码)中篇
目录 前言 题目三: 分别使用XPath和Beautiful Soup4两种方式爬取并保存非异步加载的“豆瓣某排行榜”如https://movie.douban.com/top250的名称.描述.评分和评价人数等数据 题目四: 实现某东商城某商品评论数据的爬取(评论数据不少于100条,包括评论内容.时间和评分) 本次的7个python爬虫小案例涉及到了re正则.xpath.beautiful soup.selenium等知识点,非常适合刚入门python爬虫的小伙伴参考学习. 前言 关于Pyth
-
Python7个爬虫小案例详解(附源码)上篇
目录 前言 题目一: 使用正则表达式和文件操作爬取并保存“百度贴吧”某帖子全部内容(该帖不少于5页) 题目二: 实现多线程爬虫爬取某小说部分章节内容并以数据库存储(不少于10个章节) 本次的7个python爬虫小案例涉及到了re正则.xpath.beautiful soup.selenium等知识点,非常适合刚入门python爬虫的小伙伴参考学习. 前言 关于Python7个爬虫小案例的文章分为三篇,本篇为上篇,共两题,其余两篇内容请关注! 题目一: 使用正则表达式和文件操作爬取并保存“百度贴吧
-
利用Python爬虫爬取金融期货数据的案例分析
目录 任务简介 解决步骤 代码实现 总结 大家好 我是政胤今天教大家爬取金融期货数据 任务简介 首先,客户原需求是获取https://hq.smm.cn/copper网站上的价格数据(注:获取的是网站上的公开数据),如下图所示: 如果以该网站为目标,则需要解决的问题是“登录”用户,再将价格解析为表格进行输出即可.但是,实际上客户核心目标是获取“沪铜CU2206”的历史价格,虽然该网站也有提供数据,但是需要“会员”才可以访问,而会员需要氪金...... 数据的价值!!! 鉴于,客户需求仅仅是“沪铜
-
Python爬虫Scrapy框架CrawlSpider原理及使用案例
提问:如果想要通过爬虫程序去爬取"糗百"全站数据新闻数据的话,有几种实现方法? 方法一:基于Scrapy框架中的Spider的递归爬去进行实现的(Request模块回调) 方法二:基于CrawlSpider的自动爬去进行实现(更加简洁和高效) 一.简单介绍CrawlSpider CrawlSpider其实是Spider的一个子类,除了继承到Spider的特性和功能外,还派生除了其自己独有的更加强大的特性和功能.其中最显著的功能就是"LinkExtractors链接提取器&qu
-
python爬虫破解字体加密案例详解
本次案例以爬取起小点小说为例 案例目的: 通过爬取起小点小说月票榜的名称和月票数,介绍如何破解字体加密的反爬,将加密的数据转化成明文数据. 程序功能: 输入要爬取的页数,得到每一页对应的小说名称和月票数. 案例分析: 找到目标的url: (右键检查)找到小说名称所在的位置: 通过名称所在的节点位置,找到小说名称的xpath语法: (右键检查)找到月票数所在的位置: 由上图发现,检查月票数据的文本,得到一串加密数据. 我们通过xpathhelper进行调试发现,无法找到加密数据的语法.因此,需要通
-
Python7个爬虫小案例详解(附源码)下篇
目录 前言 题目五: 实现多种方法模拟登录知乎,并爬取与一个与江汉大学有关问题和答案 题目六: 综合利用所学知识,爬取某个某博用户前5页的微博内容 题目七: 自选一个热点或者你感兴趣的主题,爬取数据并进行简要数据分析 本次的7个python爬虫小案例涉及到了re正则.xpath.beautiful soup.selenium等知识点,非常适合刚入门python爬虫的小伙伴参考学习. 前言 关于Python7个爬虫小案例的文章分为三篇,本篇为下篇,共三题,其余两篇内容请关注! 题目五: 实现多种方
-
Python爬虫入门案例之爬取二手房源数据
本文重点 系统分析网页性质 结构化的数据解析 csv数据保存 环境介绍 python 3.8 pycharm 专业版 >>> 激活码 #模块使用 requests >>> pip install requests parsel >>> pip install parsel csv [付费VIP完整版]只要看了就能学会的教程,80集Python基础入门视频教学 点这里即可免费在线观看 爬虫代码实现步骤: 发送请求 >>> 获取数据 &g
-
python爬虫利器之requests库的用法(超全面的爬取网页案例)
requests库 利用pip安装: pip install requests 基本请求 req = requests.get("https://www.baidu.com/") req = requests.post("https://www.baidu.com/") req = requests.put("https://www.baidu.com/") req = requests.delete("https://www.baid
-
Python爬虫入门案例之爬取去哪儿旅游景点攻略以及可视化分析
目录 知识点 第三方库 开发环境: 爬虫程序 导入模块 发送请求 获取数据(网页源代码) 解析网页(re正则表达式,css选择器,xpath,bs4/六年没更新了,json) 向详情页网站发送请求(get,post) 解析网页 保存数据 数据可视化 导入模块 导入数据 旅游胜地Top10及对应费用 出游方式分析 出游时间分析 出游玩法分析 知识点 requests 发送网络请求 parsel 解析数据 csv 保存数据 第三方库 requests >>> pip install requ
-
用Python爬虫破解滑动验证码的案例解析
做爬虫总会遇到各种各样的反爬限制,反爬的第一道防线往往在登录就出现了,为了限制爬虫自动登录,各家使出了浑身解数,所谓道高一尺魔高一丈. 今天分享个如何简单处理滑动图片的验证码的案例. 类似这种拖动滑块移动到图片中缺口位置与之重合的登录验证在很多网站或者APP都比较常见,因为它对真实用户体验友好,容易识别.同时也能拦截掉大部分初级爬虫. 作为一只python爬虫,如何正确地自动完成这个验证过程呢? 先来分析下,核心问题其实是要怎么样找到目标缺口的位置,一旦知道了位置,我们就可以借用selenium
-
python爬虫scrapy框架的梨视频案例解析
之前我们使用lxml对梨视频网站中的视频进行了下载,感兴趣的朋友点击查看吧. 下面我用scrapy框架对梨视频网站中的视频标题和视频页中对视频的描述进行爬取 分析:我们要爬取的内容并不在同一个页面,视频描述内容需要我们点开视频,跳转到新的url中才能获取,我们就不能在一个方法中去解析我们需要的不同内容 1.爬虫文件 这里我们可以仿照爬虫文件中的parse方法,写一个新的parse方法,可以将新的url的响应对象传给这个新的parse方法 如果需要在不同的parse方法中使用同一个item对象,可
-
Python Ajax爬虫案例分享
目录 1. 抓取街拍图片 2. 分析街拍图片结构 3. 按功能不同编写不同方法组织代码 3.1 获取网页json格式数据 3.2 从json格式数据提取街拍图片 3.3 将街拍图片以其md5码命名并保存图片 3.4 main()调用其他函数 4 抓取20page今日头条街拍图片数据 1. 抓取街拍图片 街拍图片网址 2. 分析街拍图片结构 keyword: 街拍 pd: atlas dvpf: pc aid: 4916 page_num: 1 search_json: {"from_search