JAVA超级简单的爬虫实例讲解
爬取整个页面的数据,并进行有效的提取信息,注释都有就不废话了:
public class Reptile {
public static void main(String[] args) {
String url1=""; //传入你所要爬取的页面地址
InputStream is=null; //创建输入流用于读取流
BufferedReader br=null; //包装流,加快读取速度
StringBuffer html=new StringBuffer(); //用来保存读取页面的数据.
String temp=""; //创建临时字符串用于保存每一次读的一行数据,然后html调用append方法写入temp;
try {
URL url2 = new URL(url1); //获取URL;
is = url2.openStream(); //打开流,准备开始读取数据;
br= new BufferedReader(new InputStreamReader(is)); //将流包装成字符流,调用br.readLine()可以提高读取效率,每次读取一行;
while ((temp = br.readLine()) != null) {//读取数据,调用br.readLine()方法每次读取一行数据,并赋值给temp,如果没数据则值==null,跳出循环;
html.append(temp); //将temp的值追加给html,这里注意的时String跟StringBuffere的区别前者不是可变的后者是可变的;
}
//System.out.println(html); //打印出爬取页面的全部代码;
if(is!=null) //接下来是关闭流,防止资源的浪费;
{
is.close();
is=null;
}
Document doc=Jsoup.parse(html.toString()); //通过Jsoup解析页面,生成一个document对象;
Elements elements=doc.getElementsByClass("XX");//通过class的名字得到(即XX),一个数组对象Elements里面有我们想要的数据,至于这个div的值呢你打开浏览器按下F12就知道了;
for (Element element:elements) {
System.out.println(element.text()); //打印出每一个节点的信息;你可以选择性的保留你想要的数据,一般都是获取个固定的索引;
}
} catch (MalformedURLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
上一张自己爬取的图片,并用fusioncharts生成报表(一般抓取的是int类型的数据的话,生成报表可以很直观)
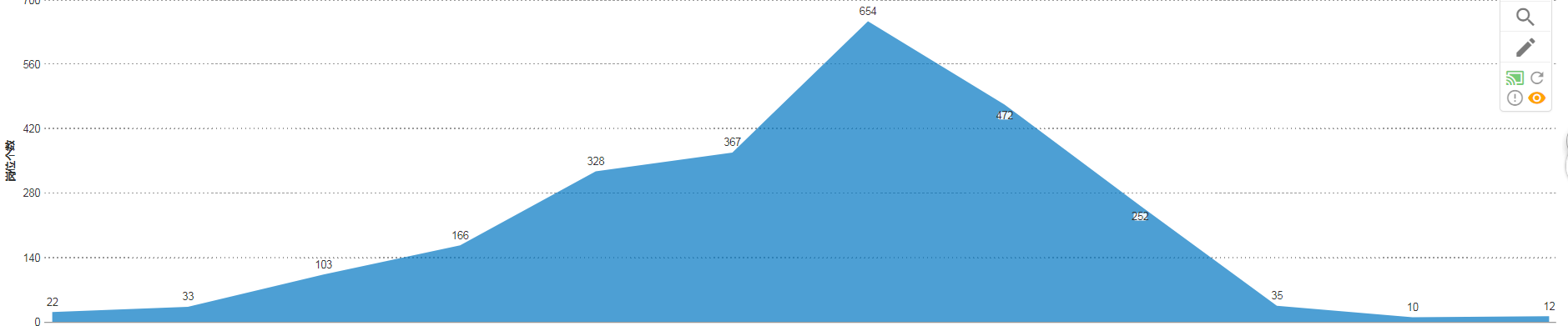
以上这篇JAVA超级简单的爬虫实例讲解就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-

java实现网页爬虫的示例讲解
这一篇目的就是在于网页爬虫的实现,对数据的获取,以便分析. 目录: 1.爬虫原理 2.本地文件数据提取及分析 3.单网页数据的读取 4.运用正则表达式完成超连接的连接匹配和提取 5.广度优先遍历,多网页的数据爬取 6.多线程的网页爬取 7.总结 爬虫实现原理 网络爬虫基本技术处理 网络爬虫是数据采集的一种方法,实际项目开发中,通过爬虫做数据采集一般只有以下几种情况: 1) 搜索引擎 2) 竞品调研 3) 舆情监控 4) 市场分析 网络爬虫的整体执行流程: 1) 确定一个(多个)种子网页 2) 进
-
java 爬虫详解及简单实例
Java爬虫 一.代码 爬虫的实质就是打开网页源代码进行匹配查找,然后获取查找到的结果. 打开网页: URL url = new URL(http://www.cnblogs.com/Renyi-Fan/p/6896901.html); 读取网页内容: BufferedReader bufr = new BufferedReader(new InputStreamReader(url.openStream())); 正则表达式进行匹配: tring mail_regex = "\\w+@\\w+
-
java实现简单的爬虫之今日头条
前言 需要提前说下的是,由于今日头条的文章的特殊性,所以无法直接获取文章的地址,需要获取文章的id然后在拼接成url再访问.下面话不多说了,直接上代码. 示例代码如下 public class Demo2 { public static void main(String[] args) { // 需要爬的网页的文章列表 String url = "http://www.toutiao.com/news_finance/"; //文章详情页的前缀(由于今日头条的文章都是在group这个目
-
JAVA超级简单的爬虫实例讲解
爬取整个页面的数据,并进行有效的提取信息,注释都有就不废话了: public class Reptile { public static void main(String[] args) { String url1=""; //传入你所要爬取的页面地址 InputStream is=null; //创建输入流用于读取流 BufferedReader br=null; //包装流,加快读取速度 StringBuffer html=new StringBuffer(); //用来保存读取页
-
python3之微信文章爬虫实例讲解
前提: python3.4 windows 作用:通过搜狗的微信搜索接口http://weixin.sogou.com/来搜索相关微信文章,并将标题及相关链接导入Excel表格中 说明:需xlsxwriter模块,另程序编写时间为2017/7/11,以免之后程序无法使用可能是网站做过相关改变,程序较为简单,除去注释40多行. 正题: 思路:打开初始Url --> 正则获取标题及链接 --> 改变page循环第二步 --> 将得到的标题及链接导入Excel 爬虫的第一步都是先手工操作一遍(
-
Java成员变量的隐藏(实例讲解)
一.如果子类与父类中有一个相同名称的成员变量,那么子类的成员变量会不会覆盖父类的成员变量?我们看下在的例子: public class A { public int x=10; } public class B extends A { public int x=20; } public class C { public static void main(String[] args) { A a=new B(); System.out.println(a.x); //1 B b=new B();
-
java RMI详细介绍及实例讲解
java本身提供了一种RPC框架--RMI(即RemoteMethodInvoke远程方法调用),在编写一个接口需要作为远程调用时,都需要继承了Remote,Remote接口用于标识其方法可以从非本地虚拟机上调用的接口,只有在"远程接口"(扩展java.rmi.Remote的接口)中指定的这些方法才可远程使用,下面通过一个简单的示例,来讲解RMI原理以及开发流程: 为了真正实现远程调用,首先创建服务端工程rmi-server,结构如下: 代码说明: 1.User.java:用于远程调用
-
java构造器的重载实现实例讲解
说到重载的问题,已经提过很多次了.我们可以把名称一致,但是内在参数不同的对象看成重载,可以说这些类的名称相同是很有迷惑性的.同时,构造器中装有许多的方法,那么构造器也是可以实现重载的功能.下面我们就构造方法格式.注意事项进行简单介绍,然后带来构造起的重载实例. 1.构造方法格式 public class 类名(){ 类名(String name); 类名 对象=new 类名(String name): } 2.注意事项 构造器必须与主类同名 构造器可以有参数 构造器可以重载 没有返回值 不添加构
-
java发送email一般步骤(实例讲解)
java发送email一般步骤 一.引入javamail的jar包: 二.创建一个测试类,实现将要发送的邮件内容写入到计算机本地,查看是否能够将内容写入: public static void main(String[] args) throws Exception { // 1. 创建一封邮件 Properties props = new Properties(); // 用于连接邮件服务器的参数配置(发送邮件时才需要用到) Session session= Session.getDefaul
-
java 动态生成SQL的实例讲解
代码如下: /** * 动态生成SQ及SQL参数L * @param ve 接收到的消息的CHGLIST * @param paramList MQ消息中的SQL参数 * @param t 泛型对象 * @param table 数据表 * @param list 可执行SQL语句集合 * @return */ public <T> String updateSqlAndParamList(Vector<String> ve,List<String> paramList
-
Scrapy爬虫实例讲解_校花网
学习爬虫有一段时间了,今天使用Scrapy框架将校花网的图片爬取到本地.Scrapy爬虫框架相对于使用requests库进行网页的爬取,拥有更高的性能. Scrapy官方定义:Scrapy是用于抓取网站并提取结构化数据的应用程序框架,可用于广泛的有用应用程序,如数据挖掘,信息处理或历史存档. 建立Scrapy爬虫工程 在安装好Scrapy框架后,直接使用命令行进行项目的创建: E:\ScrapyDemo>scrapy startproject xiaohuar New Scrapy projec
-
JavaScript实现简单的双色球(实例讲解)
如下所示: <!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>双色球</title> <link rel="stylesheet" type="text/css" href="css/twoToneClass.css" rel="e
-
java对象类型转换和多态性(实例讲解)
对象类型转换 分为向上转型和向下转型(强制对象转型). 向上转型是子对象向父对象转型的过程,例如猫类转换为动物类:向下转型是强制转型实现的,是父对象强制转换为子对象. 这和基础数据类型的转换是类似的,byte在需要时会自动转换为int(向上转型),int可以强制转型为byte(向下转型). 对于对象转型来说, 向上转型后子对象独有的成员将不可访问 . 意思是,在需要一只动物时,可以把猫当作一只动物传递,因为猫继承自动物,猫具有动物的所有属性.但向上转型后,猫不再是猫,而是被当作动物看待,它自己独