SQLSERVER 表分区操作和设计方法
一 .聚集索引
聚集索引的页级别包含了索引键,还包含数据页,因此,关于 除了键值以外聚集索引的叶级别还存放了什么的答案就是一切,也就是说,每行的所有字段都在叶级别种。
另一种说话是:数据本身也是聚集索引的一部分,聚集索引基于键值保持表中的数据有序。
SQL SERVER 中,所有的聚集索引都是唯一的,如果在创建聚集索引时没有指定UNIQUE 关键字,SQL SERVER 会在需要时通过往记录中添加一个唯一标识符(Uniqueifier)在内部保证索引的唯一性,该唯一标识符是一个4字节的值,作为附加在聚集索引键的字段添加到数据中,只有那些声明为索引键字段并拥有重复值的行才会被添加。
二 .非聚集索引
对于非聚集索引,叶级别不包含全部的数据。除了键值以外,每个叶级别(树的最低层)中的索引行包含了一个书签(bookmark),告诉SQL Server 可以在哪里找到与索引键相应的数据行。一个书签课能有两种格式。如果表上存在聚集索引,书签就是相应的数据行的聚集索引键。如果表是堆(heap)结构 ,就是没有聚集索引的情况下 ,书签就是一个行标识符 row identifier,rid ,以 文件号 页号 槽号 的格式来定位实际的行。
非聚集索引的存在与否并不影响数据分页的组织,因此每张表上并不像聚集索引那样只局限于拥有一个非聚集索引,SQL Server 2005 每张表能够包含249 个非聚集索引 SQL Server 2008 每张表能够包含999 个非聚集索引 ,但是实际上所用到的比这个数要少的多。
三 .包含索引
索引键字段数量限制是16个,总共900个字节大小 ,包含性列只在叶级别中出现而且不以任何方式控制索引行的排序。它们的目的是使叶级别能够包含更多的信息从而更大地发挥覆盖索引(Covering index)的索引调优能力.覆盖索引是一种非聚集索引,在其叶级别就可以找到满足查询的全部信息,这样sql server就根本没有必要访问数据分页了,在一些情况下 sql serer 会悄悄的为索引添加一个包含性列。这可能发生在索引建立于分区表 也就是我今天是发的博客 O(∩_∩)O (partitioned table )上没有指定 on filegroup 或者 no partition_scheme 的情况下。
一 .SQL SERVER 表分区介绍:
SQL Server 引入的表分区技术,让用户能够把数据分散存放到不同的物理磁盘中,提高这些磁盘的并行处理性能以优化查询性能……
二 .SQL SERVER 数据库表分区由三个步骤来完成:
1.创建分区函数
2.创建分区架构
3.对表进行分区
基于缓存更新机制,我使用时间来进行分区,这里大家根据业务的要求使用合适的字段来作为分区
创建数据库分区文件数量,这里存储一年的数据分成十二个分区,需要现在D盘建立好Data 的文件夹 里面包含Primary 文件夹和 FG1 FG2 FG3 FG4............
代码如下:
IF EXISTS (SELECT name FROM sys.databases WHERE name = N'AirAvCache')
DROP DATABASE [AirAvCache]
GO
CREATE DATABASE [AirAvCache]
ON PRIMARY
(NAME='Data Partition DB Primary FG',
FILENAME=
'D:\Data\Primary\AirAvCache Primary FG.mdf',
SIZE=5,
MAXSIZE=500,
FILEGROWTH=1 ),
FILEGROUP [AirAvCache FG1]
(NAME = 'AirAvCache FG1',
FILENAME =
'D:\Data\FG1\AirAvCache FG1.ndf',
SIZE = 5MB,
MAXSIZE=500,
FILEGROWTH=1 ),
FILEGROUP [AirAvCache FG2]
(NAME = 'AirAvCache FG2',
FILENAME =
'D:\Data\FG2\AirAvCache FG2.ndf',
SIZE = 5MB,
MAXSIZE=500,
FILEGROWTH=1 ),
FILEGROUP [AirAvCache FG3]
(NAME = 'AirAvCache FG3',
FILENAME =
'D:\Data\FG3\AirAvCache FG3.ndf',
SIZE = 5MB,
MAXSIZE=500,
FILEGROWTH=1 ),
FILEGROUP [AirAvCache FG4]
(NAME = 'AirAvCache FG4',
FILENAME =
'D:\Data\FG4\AirAvCache FG4.ndf',
SIZE = 5MB,
MAXSIZE=500,
FILEGROWTH=1 ),
FILEGROUP [AirAvCache FG5]
(NAME = 'AirAvCache FG5',
FILENAME =
'D:\Data\FG5\AirAvCache FG5.ndf',
SIZE = 5MB,
MAXSIZE=500,
FILEGROWTH=1 ),
FILEGROUP [AirAvCache FG6]
(NAME = 'AirAvCache FG6',
FILENAME =
'D:\Data\FG6\AirAvCache FG6.ndf',
SIZE = 5MB,
MAXSIZE=500,
FILEGROWTH=1 ),
FILEGROUP [AirAvCache FG7]
(NAME = 'AirAvCache FG7',
FILENAME =
'D:\Data\FG7\AirAvCache FG7.ndf',
SIZE = 5MB,
MAXSIZE=500,
FILEGROWTH=1 ),
FILEGROUP [AirAvCache FG8]
(NAME = 'AirAvCache FG8',
FILENAME =
'D:\Data\FG8\AirAvCache FG8.ndf',
SIZE = 5MB,
MAXSIZE=500,
FILEGROWTH=1 ),
FILEGROUP [AirAvCache FG9]
(NAME = 'AirAvCache FG9',
FILENAME =
'D:\Data\FG9\AirAvCache FG9.ndf',
SIZE = 5MB,
MAXSIZE=500,
FILEGROWTH=1 ),
FILEGROUP [AirAvCache FG10]
(NAME = 'AirAvCache FG10',
FILENAME =
'D:\Data\FG10\AirAvCache FG10.ndf',
SIZE = 5MB,
MAXSIZE=500,
FILEGROWTH=1 ),
FILEGROUP [AirAvCache FG11]
(NAME = 'AirAvCache FG11',
FILENAME =
'D:\Data\FG11\AirAvCache FG11.ndf',
SIZE = 5MB,
MAXSIZE=500,
FILEGROWTH=1 ),
FILEGROUP [AirAvCache FG12]
(NAME = 'AirAvCache FG12',
FILENAME =
'D:\Data\FG12\AirAvCache FG12.ndf',
SIZE = 5MB,
MAXSIZE=500,
FILEGROWTH=1 )
创建好后如图: 
打开FG1 文件夹 看到多了AirAvCacheFG1.ndf 文件 
创建分区函数
代码
代码如下:
USE AirAvCache
GO
-- 创建函数
CREATE PARTITION FUNCTION [AirAvCache Partition Range](DATETIME)
AS RANGE LEFT FOR VALUES ('2010-09-01','2010-10-01','2010-11-01','2010-12-01','2011-01-01','2011-02-01','2011-03-01','2011-04-01','2011-05-01','2011-06-01','2010-07-01');
CREATE PARTITION SCHEME [AirAvCache Partition Scheme]
AS PARTITION [AirAvCache Partition Range]
TO ([AirAvCache FG1], [AirAvCache FG2], [AirAvCache FG3],[AirAvCache FG4],[AirAvCache FG5],[AirAvCache FG6],[AirAvCache FG7],[AirAvCache FG8],
[AirAvCache FG9],[AirAvCache FG10],[AirAvCache FG11],[AirAvCache FG12]);
创建一个使用AirAvCache Partitiion Scheme 架构的表
代码如下:
CREATE TABLE [dbo].[AvCache](
[CityPair] [varchar](6) NOT NULL,
[FlightNo] [varchar](10) NULL,
[FlightDate] [datetime] NOT NULL,
[CacheTime] [datetime] NOT NULL DEFAULT (getdate()),
[AVNote] [varchar](300) NULL
) ON [AirAvCache Partition Scheme] (FlightDate); --注意这里使用[AirAvCache Partition Scheme]架构,根据FlightDate 分区
-- 查看使用情况
SELECT *, $PARTITION.[AirAvCache Partition Range](FlightDate)
FROM dbo.AVCache
可以看到9 月和 10 月已经分开了。 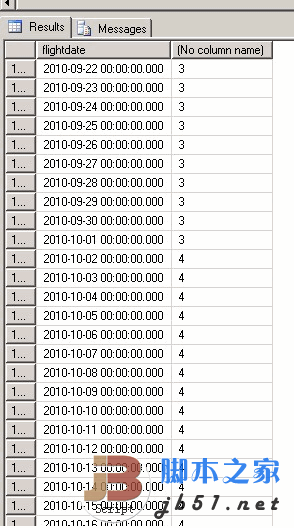
相关推荐
-
SQLServer 通用的分区增加和删除的算法
首先是将一个数据表加入到分区表的方法: [dbo].[SP_Helper_Partition_Add] @SrcTable nvarchar(256), 待加入的表 @DestTable nvarchar(256), 目标表 @idxOnDest nvarchar(1024), 目标表上的索引创建语句 @Partition_func_name nvarchar(256), 分区函数 @PartCol nvarchar(256), 分区的列 @SonIsPart tinyint=1, 待加入的表是
-
SQL server 2005的表分区
下面来说下,在SQL SERVER 2005的表分区里,如何对已经存在的有数据的表进行分区,其实道理和之前在http://www.cnblogs.com/jackyrong/archive/2006/11/13/559354.html说到一样,只不过交换下顺序而已,下面依然用例子说明: 依然在c盘的data2目录下建立4个文件夹,用来做4个文件组,然后建立数据库 use masterIF EXISTS (SELECT name FROM sys.databases WHERE name =
-

SQL Server实现自动循环归档分区数据脚本详解
概述 大家应该都知道在很多业务场景下我们需要对一些记录量比较大的表进行分区,同时为了保证性能需要将一些旧的数据进行归档.在分区表很多的情况下如果每一次归档都需要人工干预的话工程量是比较大的而且也容易发生纰漏.接下来分享一个自己编写的自动归档分区数据的脚本,原理是分区表和归档表使用相同的分区方案,循环利用当前的文件组,话不多说了,来一起看看详细的介绍吧. 一.创建测试数据 ----01创建文件组 USE [master] GO ALTER DATABASE [chenmh] ADD FILEGRO
-
SQL Server根据分区表名查找所在的文件及文件组实现脚本
SELECT ps.name AS PSName, dds.destination_idAS PartitionNumber, fg.name AS FileGroupName,fg.name, t.name, f.name as filename FROM (((sys.tables AS t INNER JOIN sys.indexes AS i ON (t.object_id = i.object_id)) INNER JOIN sys.partition_schemes AS ps ON
-
SQLSERVER 表分区操作和设计方法
一 .聚集索引 聚集索引的页级别包含了索引键,还包含数据页,因此,关于 除了键值以外聚集索引的叶级别还存放了什么的答案就是一切,也就是说,每行的所有字段都在叶级别种.另一种说话是:数据本身也是聚集索引的一部分,聚集索引基于键值保持表中的数据有序.SQL SERVER 中,所有的聚集索引都是唯一的,如果在创建聚集索引时没有指定UNIQUE 关键字,SQL SERVER 会在需要时通过往记录中添加一个唯一标识符(Uniqueifier)在内部保证索引的唯一性,该唯一标识符是一个4字节的值,作为附加在
-
SqlServer表死锁的解决方法分享
其实不光是上面描述的情况会锁住表,还有很多种场景会使表放生死锁,解锁其实很简单,下面用一个示例来讲解: 1 首先创建一个测试用的表: 复制代码 代码如下: CREATE TABLE Test ( TID INT IDENTITY(1,1) ) 2 执行下面的SQL语句将此表锁住: 复制代码 代码如下: SELECT * FROM Test WITH (TABLOCKX) 3 通过下面的语句可以查看当前库中有哪些表是发生死锁的: 复制代码 代码如下: SELECT request_session_
-
SqlServer 表单查询问题及解决方法
Q1:表StudentScores如下,用一条SQL语句查询出每门课都大于80分的学生姓名 Q2:表DEMO_DELTE如下,删除除了自动编号不同,其他都相同的学生冗余信息 Q3:Team表如下,甲乙丙丁为四个球队,现在四个球对进行比赛,用一条sql语句显示所有可能的比赛组合 Q4:请考虑如下SQL语句在Microsoft SQL Server 引擎中的逻辑处理顺序 USE TSQLFundamentals2008 SELECT empid,YEAR(orderdate) AS orderyea
-
sqlserver进程死锁关闭的方法
1.首先我们需要判断是哪个用户锁住了哪张表. --查询被锁表 select request_session_id spid,OBJECT_NAME(resource_associated_entity_id) tableName from sys.dm_tran_locks where resource_type='OBJECT' 查询后会返回一个包含spid和tableName列的表. 其中spid是进程名,tableName是表名. 2.了解到了究竟是哪个进程锁了哪张表后,需要通过进程找到锁
-
MongoDB设计方法以及技巧示例详解
前言 MongoDB是一种流行的数据库,可以在不受任何表格schema模式的约束下工作.数据以类似JSON的格式存储,并且可以包含不同类型的数据结构.例如,在同一集合collection 中,我们可以拥有以下两个文档document: { id: '4', name: 'Mark', age: '21', addresses : [ { street: '123 Church St', city: 'Miami', cc: 'USA' }, { street: '123 Mary Av', ci
-
迁移sqlserver数据到MongoDb的方法
前言 随着数据量的日积月累,数据库总有一天会不堪重负的,除了通过添加索引.分库分表,其实还可以考虑一下换个数据库.我强烈推荐使用MongoDb,我举例说一下我的经历:我的项目中有一张表的数据大概是3000万行数据,sqlserver查找的速度是16秒左右.我导入到MongoDb中后查询的速度大概能快一倍多,7秒左右,如果还是不能满足需求,MongoDb同样可以:索引,分库分表.那么下面就开干吧: 迁移方案:sqlserver和mongodb都支持导入导出csv格式,这肯定是比手动编码写个查询然后
-
SqlServer事务语法及使用方法详解
事务是关于原子性的.原子性的概念是指可以把一些事情当做一个不可分割的单元来看待.从数据库的角度看,它是指应全部执行或全部不执行的一条或多条语句的最小组合.为了理解事务的概念,需要能够定义非常明确的边界.事务要有非常明确的开始和结束点.SqlServer中的每一条select.insert.update.delete语句都是隐式事务的一部分.即使只发出一条语句,也会把这条语句当做一个事务-或执行语句的所有内容或什么都不执行.但是如果需要的不只是一条,而是多条语句呢?在这种情况下,就需要有一种方法来
-
MYSQL锁表问题的解决方法
本文实例讲述了MYSQL锁表问题的解决方法.分享给大家供大家参考,具体如下: 很多时候!一不小心就锁表!这里讲解决锁表终极方法! 案例一 mysql>show processlist; 参看sql语句 一般少的话 mysql>kill thread_id; 就可以解决了 kill掉第一个锁表的进程, 依然没有改善. 既然不改善, 咱们就想办法将所有锁表的进程kill掉吧, 简单的脚本如下. #!/bin/bash mysql - u root - e " show processli
-
Oracle修改表空间大小的方法
本文讲述了Oracle修改表空间大小的方法.分享给大家供大家参考,具体如下: 1)查看各表空间分配情况 SQL> select tablespace_name, sum(bytes) / 1024 / 1024 from dba_data_files group by tablespace_name; TABLESPACE_NAME SUM(BYTES)/1024/1024 ------------------------------ -------------------- UNDOTBS1
-
jQuery Validate让普通按钮触发表单验证的方法
一般的表单校验都是直接注册在页面上的匿名函数,导致只能通过固定的提交方式触发表单校验,如果想自定义一个按钮触发表单校验如何实现呢? 目前写法: $(function(){ $("#form").validate({ rules : { user_name : { required : true }, -- }, messages : { user_name : { required : '用户名必填', }, -- } }); }); 改写方法: //编写表单验证函数validform