Apache Pulsar 微信大流量实时推荐场景下实践详解
目录
- 导语
- 作者简介
- 实践 1:大流量场景下的 K8s 部署实践
- 实践 2:非持久化 Topic 的应用
- 实践 3:负载均衡与 Broker 缓存优化
- 实践 4:COS Offloader 开发与应用
- 未来展望与计划
导语
本文整理自 8 月 Apache Pulsar Meetup 上,刘燊题为《Apache Pulsar 在微信的大流量实时推荐场景实践》的分享。本文介绍了微信团队在大流量场景下将 Pulsar 部署在 K8s 上的实践与优化、非持久化 Topic 的应用、负载均衡与 Broker 缓存优化实践与COS Offloader 开发与应用。
作者简介
刘燊,腾讯微信高级研发工程师,Apache Pulsar Contributor。
在通信社交领域,微信已经成为国内当之无愧的社交霸主。用户人数在 2018 年突破了 10 亿,截至 2021 年第三季度末,微信每月活动账户总数已达到 12.6 亿人,可以说,微信已经成为国人生活的一部分。
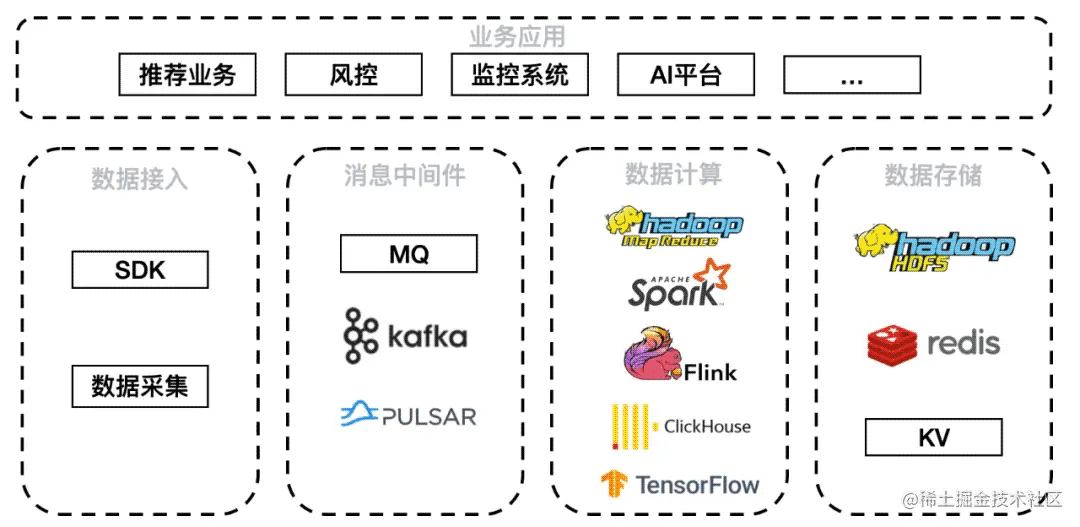
微信的业务场景包括推荐业务、风控、监控系统、AI 平台等。数据通过 SDK 和数据采集方式接入,经由 MQ、Kafka、Pulsar 消息中间件,其中 Pulsar 发挥了很大的作用。中间件下游接入数据计算层 Hadoop、Spark、Flink、ClickHouse、TensorFlow 等计算平台,由于本次介绍实时推荐场景,因此较多使用 Flink 和 TensorFlow。落地存储平台则包括 HDFS、HBase、Redis 以及各类自研 KV。
团队选型 Pulsar 的初期目标是获得一个满足大数据流量场景并且运维管理便捷的消息队列系统。最终选择 Pulsar 的主要原因有五点:
- 在腾讯自研上云的大背景下,团队非常看重云原生特性。Pulsar 的云原生特性,包括分布式、弹性伸缩、读写分离等都体现出优势。Pulsar 逻辑层 Broker 无状态,直接提供服务。存储层 Bookie 有状态,但是节点对等,且 Bookie 自带多副本容灾;
- Pulsar 支持资源隔离,可以软隔离或硬隔离,避免不同业务之间互相影响;
- Pulsar 支持灵活的 Namespace/Topic 策略管控,对集群的管理和维护有很大帮助;
- Pulsar 能够便捷扩容,逻辑层 Broker 的无状态和负载均衡策略允许快速扩容,存储层 Bookie 节点之间互相对等也便于快速扩容,可以轻松应对流量暴涨场景;
- Pulsar 具备多语言客户端能力,微信的业务场景中涉及 C/C++、TensorFlow、Python 等语言,Pulsar 可以满足需求。
实践 1:大流量场景下的 K8s 部署实践
微信团队使用了 Pulsar 官网提供的 K8s Helm chart 部署方式。

原生部署架构中,流量从 Proxy 代理层进入,经过 Broker 逻辑服务层写入 Bookie 存储层。Proxy 代理层代理客户端和 Broker 之间的连接,Broker 层管理 Topic,Bookie 层负责持久化消息存储。在上图中,入流量和出流量分别用 In 和 Out 进行标记,Replica 是配置的副本。
在应用的过程中团队发现了两个问题:首先 Proxy 代理了 Pulsar 客户端的请求,导致 Broker 无法获取客户端 IP,增加了运维难度;其次,当集群流量较大时,集群内部带宽会成为瓶颈。上图架构内,集群入流量为 (2+ 副本数)倍;出流量最大为 3 倍,Consumer、Proxy、Broker 和 Bookie 间分别有一倍流量,但是仅极端情况下流量会全量从 Bookie 流出。假设出入流量都是 10 GBps,副本数为 3,集群内入流量会放大为 50 GBps,出流量会放大为 30 GBps。另外默认情况下 Proxy 服务只有一个负载均衡器承载所有流量,压力巨大。
这里可以看出瓶颈主要出现在 Proxy 层,该层造成了很大流量浪费。而 Pulsar 实际上支持 Broker 直连,因此团队在此基础上进行了一些优化:

团队利用了腾讯云 K8s 集群的能力,给 Broker 配置了弹性网卡,并使 Broker 的 IP 直接暴露在集群外,可以被外部客户端直接访问。Broker 服务也配置了负载均衡器。这样客户端可以直接访问负载均衡器 IP,再经过 Pulsar 内部协议的 Lookup 操作找到要访问的 Topic 所处的 Broker。由此节省了 Proxy 带来的额外带宽消耗。
团队在 K8s 部署方面还做了以下优化工作:
- 如上文所述去 Proxy;
- Bookie 使用多盘多目录 + 本地 SSD 提升性能,由于原社区版本 Pulsar 不支持多盘多目录,这里团队做了改进支持并合并入社区(github.com/apache/puls…);
- 日志采集使用腾讯云 CLS(日志服务),统一的日志服务可以简化分布式多节点系统的运维、问题查询操作;
- 指标采集使用 Grafana + Kvass + Thanos,默认指标采集使用了单机服务,很快出现了性能瓶颈,优化后问题解决且支持水平扩容。
实践 2:非持久化 Topic 的应用
生产者和消费者是同 Broker 中的 Dispatcher 模块交互的,而持久化 Topic 中生产者数据会通过 Dispatcher 进入 Managed Ledger 模块,再调用 Bookie 客户端与 Bookie 交互。非持久化 Topic 中数据不会进入 Managed Ledger,而是直接发送给消费者。在大流量场景中,非持久化 Topic 由于不需要与 Bookie 交互,对集群的带宽压力会明显降低。

非持久化 Topic 在大流量实时推荐场景中有应用,但具体的应用场景必须满足“可容忍少量数据丢失”的要求。实践中有三种场景满足这一要求:
- 大流量 + 消费端处理能力不足的实时训练任务;
- 时效性敏感的实时训练任务;
- 抽样评测任务。
实践 3:负载均衡与 Broker 缓存优化


以上是一个线上真实的场景。生产环境中出现了反复 bundle unload 的问题,导致 Broker 负载反复波动。
该场景中使用了以下负载均衡配置:
loadManagerClassName=org.apache.pulsar.broker.loadbalance.impl.ModularLoadManagerImpl loadBalancerLoadSheddingStrategy=org.apache.pulsar.broker.loadbalance.impl.ThresholdShedder loadBalancerBrokerThresholdShedderPercentage=10 loadBalancerBrokerOverloadedThresholdPercentage=70 Load bundle处理类(select for broker):org.apache.pulsar.broker.loadbalance.impl.LeastLongTermMessageRate

如上图,假设三个 Broker 平均负载是 50%,则阈值就是 60%,超出 60% 的部分需要均衡。但实际应用中发现 Broker 1 的多余 20% 负载会卸载到 Broker 2 上,之后由于 Broker 2 超载所以又会卸载下来,还会回到 Broker 1 上。结果流量就在 Broker 1 和 Broker 2 上反复横跳。
跟踪代码发现,Load Bundle 处理类是根据 Broker 的消息量判断该承载多余流量的 Broker,但生产中消息量与机器负载并不完全正相关,且 Threshold shedder 是根据 CPU、出入流量、内存等多种指标平均加权得出 Broker 负载,所以 bundle 的加载和卸载逻辑并不一致。
对此团队进行了代码优化改进:
loadManagerClassName=org.apache.pulsar.broker.loadbalance.impl.ModularLoadManagerImpl loadBalancerLoadSheddingStrategy=org.apache.pulsar.broker.loadbalance.impl.ThresholdShedder loadBalancerBrokerThresholdShedderPercentage=10 loadBalancerBrokerOverloadedThresholdPercentage=70 Load bundle处理类(select for broker):在低于平均负载的broker中随机选择 loadBalancerDistributeBundlesEvenlyEnabled=false (相同的代码实现:PR-16059)
优化后的效果如下,可以看到集群流量稳定许多:

团队还在实时推荐场景下优化了 Broker 缓存。这种场景有以下特征:
- 消费任务数量众多;
- 消费速度参差不齐;
- 消费任务经常重启。
对此,社区原有的 Broker 缓存逻辑效果不佳。以下是 Broker 缓存的原有驱逐逻辑:
void doCacheEviction(long maxTimestamp) {
if (entryCache.getsize() <= 0) {
return;
}
// Always remove all entries already read by active cursors
PositionImpl slowestReaderPos = getEarlierReadPositionForActiveCursors);
if (slowestReaderPos != null) {
entryCache.invalidateEntries(slowestReaderPos):
}
// Remove entries older than the cutoff threshold
entryCache.invalidateEntriesBeforeTimestamp(maxTimestamp);
}
默认策略会找出当前消费不活跃(由阈值控制,Cursor 消费的 entry 超过阈值即被认为是不活跃)的 Cursor,对 Cursor 之前的数据做驱逐。对此,腾讯工程师向社区提交了代码改进:
void doCacheEviction (long maxTimestamp){
if (entryCache.getSize() (= 0) {
return;
)
PositionImpl evictionPos;
if (config.isCacheEvictionByMarkDeletedPosition()){
evictionPos=getEarlierMarkDeletedPositionForActiveCursors().getNext();
} else {
// Always remove all entries already read by active cursors
evictionPos=getEarlierReadPositionForActiveCursors();
}
if (evictionPos != null) {
entryCache.invalidateEntries(evictionPos);
}
// Remove entries older than the cutoff threshold
entryCache.invalidateEntriesBeforeTimestamp(maxTimestamp);
}
这里将选择非活跃 Cursor 的逻辑改成了寻找需要删除的数据位置。这样消费速度相对较慢的数据就不会穿越到 Bookie 中增加集群压力,只要数据有 Backlog 就会被缓存。但这种方法会导致缓存空间吃紧,因为消费任务重启期间仍旧要无意义地保留缓存,占用缓存空间。
对此微信团队在社区改进的基础上又做了调整:
void doCacheEviction(long maxTimestamp){
if (entryCache.getSize() <= 0) {
return;
}
if (factory.getConfig().isRemoveReadEntriesInCache()){
PositionImpl evictionPos;
if (config.isCacheEvictionByMarkDeletedPosition()){
PositionImplearlierMarkDeletedPosition=getEarlierMarkDeletedPositionForActiveCursors();
evictionPos = earlierMarkDeletedPosition != null? earlierMarkDeletedPosition.getNext() : null;
} else {
// Always remove all entries already read by active cursors
evictionPos=getEarlierReadPositionForActiveCursors();
}
if (evictionPos != null) {
entryCache.invalidateEntries(evictionPos);
}
}
//Remove entries older than the cutoff threshold
entryCache.invalidateEntriesBeforeTimestamp(maxTimestamp);
}
这里简单地将一定时间内的数据缓存到 Broker 中,有效提升了场景中的缓存效率:

实践 4:COS Offloader 开发与应用

Pulsar 提供了分层存储能力,可以将存储转移到廉价的存储层。Pulsar Offloader 可以将超过一定时长的 Ledger 搬运到远端存储,不再停留在 Bookie 层,由 Broker 接管这部分的数据管理。
团队使用 Pulsar Offloader 的原因有:
- Bookie Journal/Ledger 盘都使用 SSD,成本较高;
- 业务需求存储时间长、数据存储量大;
- 数据消费任务异常,需要容忍较长时间的数据 Backlog;
- 数据回放需求。
Pulsar 社区版本并不支持腾讯云对象存储(COS),所以团队开发了内部云上 COS Offloader 插件并应用于线上。
未来展望与计划
团队在部署与使用过程中一直和社区密切沟通,团队未来计划跟进社区版本升级与 bug 修复。微信团队将着重参与一些特性,比如 PIP 192 Broker 负载均衡与缓存优化,计划重构负载均衡器;PIP 180 通过影子 Topic 解决读放大问题,帮助精细化管理 Topic。微信团队也在关注 Pulsar 生态进展,如 Flink、Pulsar、数据湖全链路打通。
以上就是Apache Pulsar 微信大流量实时推荐场景下实践详解的详细内容,更多关于Apache Pulsar微信大流量推荐的资料请关注我们其它相关文章!
相关推荐
-

Apache SkyWalking 修复TTL timer 失效bug详解
目录 正文 SkyWalking OAP 角色 SkyWalking OAP 集群 Data TTL timer 配置 DataTTLKeeperTimer 定时任务 Bug 产生的原因 解决 Bug 正文 近期,Apache SkyWalking 修复了一个隐藏了近4年的Bug - TTL timer 可能失效问题,这个 bug 在 SkyWalking <=9.2.0 版本中存在. 关于这个 bug 的详细信息可以看邮件列表 lists.apache.org/thread/ztp4… 具体如
-
Apache Doris Colocate Join 原理实践教程
目录 What Colocate Join Why Colocate Join How Colocate Join 核心思路 术语定义 1 数据导入时保证本地性 2 Colocate Join Query Plan 3 Colocate Join Query Schedule 4 Colocate Join At Bucket Seq Level 5 Colocate Join Metadata Maintenance 6 How to decide a query can colocate j
-
Apache Pulsar集群搭建部署详细过程
目录 一.集群组成说明 二.安装前置条件 三.ZooKeeper集群搭建 四.BookKeeper集群搭建 五.Broker集群搭建 六.docker安装pulsar-dashboard 一.集群组成说明 1.搭建Pulsar集群至少需要3个组件:ZooKeeper集群.BookKeeper集群和Broker集群(Broker是Pulsar的自身实例).这三个集群组件如下:ZooKeeper集群(3个ZooKeeper节点组成)Bookie集群(也称为BookKeeper集群,3个BookKee
-
Apache Doris Join 优化原理详解
目录 背景 & 目标 Doris 数据划分 Partition Bucket Join 方式 总览 Broadcast / Shuffle Join Bucket Shuffle Join Plan Rule Colocate Join Runtime Filter 优化 Join Reorder 优化 Join 调优建议 背景 & 目标 掌握 Apache Doris Join 优化手段及其实现原理 为代码阅读提供理论基础 Doris 数据划分 不同的 Join 方式非常依赖于对 Dor
-
Apache SkyWalking 监控 MySQL Server 实战解析
目录 正文 监控 MySQL Server 安装过程 docker compose 部署 正文 Apache SkyWalking 在本月初发布了 SkyWalking Backend.UI 的 9.2.0 版本 以及 SkyWalking Java Agent 8.12.0 版本,其中就有笔者贡献的 hutool-http client 5.x 插件,以后大家通过 hutool 工具发送的 http 请求也可以出现在分布式链路中了. 另外,社区宣布计划在 2022 年 11 月 30 日结束所
-
Apache Cordova Android原理应用实例详解
目录 前言 技术选型 技术原理 1. 如何本地加载url对应的资源 2. webview如何使用js调用app原生api 3. app原生api如何回调webview中的js 4. 多个plugin的情况 关于踩到的坑 1. 打包路径配置问题 2. success不回调问题 前言 从原理到应用复盘一下自己做过的所有项目,希望能让我自己过两年仍然能看懂现在写的代码哈哈.在项目里我只负责了Android的开发包括插件开发和集成,ios没摸到,有机会也得自己玩下,但是这篇文章不会接触. 技术选型 现在
-
Apache Pulsar结合Hudi构建Lakehouse方案分析
目录 1. 动机 2. 分析 3. 当前方案 4. 新的Lakehouse存储方案 4.1 新的存储布局 4.2 支持高效Upserts 4.3 将Hudi表当做Pulsar Topic 4.4 可扩展的元数据管理 5. 引用 1. 动机 Lakehouse最早由Databricks公司提出,其可作为低成本.直接访问云存储并提供传统DBMS管系统性能和ACID事务.版本.审计.索引.缓存.查询优化的数据管理系统,Lakehouse结合数据湖和数据仓库的优点:包括数据湖的低成本存储和开放数据格式访
-
Apache Pulsar 微信大流量实时推荐场景下实践详解
目录 导语 作者简介 实践 1:大流量场景下的 K8s 部署实践 实践 2:非持久化 Topic 的应用 实践 3:负载均衡与 Broker 缓存优化 实践 4:COS Offloader 开发与应用 未来展望与计划 导语 本文整理自 8 月 Apache Pulsar Meetup 上,刘燊题为<Apache Pulsar 在微信的大流量实时推荐场景实践>的分享.本文介绍了微信团队在大流量场景下将 Pulsar 部署在 K8s 上的实践与优化.非持久化 Topic 的应用.负载均衡与 Bro
-
货拉拉大数据对BitMap的探索实践详解
目录 关于Bitmap What BitMap的简单实现 BitSet源码理解 备注信息 核心片段理解 Why BitMap的特点 BitMap的优化 RoaringBitmap的核心原理 how BitMap在用户分群的应用 传统解决方案 使用BitMap的方案 BitMap在A/B实验平台业务的应用 结语 关于Bitmap 在大数据时代,想要不断提升基于海量数据获取的决策.洞察发现和流程优化等能力,就需要不停思考,如何在利用有限的资源实现高效稳定地产出可信且丰富的数据,从而提高赋能下游产品的
-
eBay 打造基于 Apache Druid 的大数据实时监控系统
首先需要注意的是,本文即将提到的 Druid,并非阿里巴巴的 Druid 数据库连接池,而是另一个大数据场景下的解决方案:Apache Druid. Apache Druid 是一个用于大数据实时查询和分析的高容错.高性能开源分布式时序数据库系统,旨在快速处理大规模的数据,并能够实现快速查询和分析.尤其是当发生代码部署.机器故障以及其他产品系统遇到宕机等情况时,Druid 仍能够保持 100% 正常运行.创建 Druid 的最初意图主要是为了解决查询延迟问题,当时试图使用 Hadoop 来实现交
-
G1垃圾回收器在并发场景调优详解
目录 序言 G1概览 1.最大堆大小 2.Region大小 3.获取默认值 三种GC模式 1.新生代回收 2.混合回收 3.Full GC 默认参数 1.堆内存 2.新生代内存回收 3.混合回收 垃圾在堆中流转 1.对象如何进入老年代 (1)大对象直接到老年代 (2)动态年龄判断 2.高并发加速进入老年代 调优步骤 1.设置垃圾回收器 2.设置堆大小 3.元空间设置 4.GC停顿时间 5.新生代大小 调优实践 1.频繁的YGC 2.频繁的Mixed GC (1)大对象 (2)元空间 3.Full
-
微信小程序网络数据请求的实现详解
目录 一.限制 二.配置服务器合法域名 三.发起请求 GET请求 POST请求 二者区别 四. 跳过requst合法域名校验 五.关于跨域和Ajax的说明 番外-GET与POST二者的通俗化解释 一.限制 出于安全性考虑,小程序官方对数据接口的请求做出了如下两点限制: 只能请求HTTPS类型的接口 必须先将接口的域名添加到信任列表中 二.配置服务器合法域名 配置步骤: 登录微信小程序管理后台 链接 点击开发 开发管理 开发设置 服务器域名 点击右上角修改requst合法域名 注意事项: 域名只支
-
微信小程序的日期选择器的实例详解
微信小程序的日期选择器的实例详解 前言: 关于微信小程序中的日期选择器大家用过都会发现有个很大的问题,就是在2月的时候会有31天,没有进行对闰年的判断等各种情况.看了官方文档提供的源码后进行了一些修改,测试修复了上面所说的bug! 下面源码: <!---js---> const date = new Date();//获取系统日期 const years = [] const months = [] const days = [] const bigMonth = [1,3,5,7,8,10,
-
微信小程序 获取二维码实例详解
微信小程序 获取二维码实例详解 理论: 接口A: 适用于需要的码数量较少的业务场景 接口地址:(永久有效,数量有限,进入path对应的页面) https://api.weixin.qq.com/wxa/getwxacode?access_token=ACCESS_TOKEN path String 不能为空,最大长度 128 字节 width Int 430(默认) 二维码的宽度 auto_color .. line_color .. 接口B:适用于需要的码数量极多,或仅临时使用的业务场景(永
-
微信小程序后台解密用户数据实例详解
微信小程序后台解密用户数据实例详解 微信小程序API文档:https://mp.weixin.qq.com/debug/wxadoc/dev/api/api-login.html openId : 用户在当前小程序的唯一标识 因为最近根据API调用https://api.weixin.qq.com/sns/jscode2session所以需要配置以下服务,但是官方是不赞成这种做法的, 而且最近把在服务器配置的方法给关闭了.也就是说要获取用户openid,地区等信息只能在后台获取. 一下是官方的
-
微信小程序富文本渲染引擎的详解
微信小程序富文本渲染引擎的详解 步骤 把 wxParser 目录放到小程序项目的根目录下 在需要富文本解析的 WXML 内引入 wxParser/index.wxml 在页面 JS 文件内使用 wxParser.parse(options) 方法解析 HTML 内容 在小程序项目根目录的 app.wxss 内引入 wxParser 的默认样式库 wxParser.parse(options) 方法的 options 参数说明 参数名 类型 必填 描述 bind String 是 要绑定的数据名称
-
微信小程序 scroll-view的使用案例代码详解
scroll-view:滚动视图 使用view其实也能实现滚动,跟div用法差不多 而scroll-view跟view最大的区别就在于:scroll-view视图组件封装了滚动事件,监听滚动事件什么的直接写方法就行. scroll-view纵向滚动添加属性scroll-y,然后写一个固定高度就行了,我主要说一下scroll-view的横向滚动scroll-x: 我使用了display: flex;布局,特么的直接写在scroll-view上面,显示出来的结果总是不对头,试了好多次,得到了下面两种