利用python脚本提取Abaqus场输出数据的代码
笔者为科研界最后的摆烂王,目前利用python代码对Abaqus进行二次开发尚在学习中。欢迎各位摆烂的仁人志士们和我一起摆烂!ps:搞什么科研,如果不是被逼无奈,谁要搞科研!
该代码是学习过程中,对前人已有工作所做的稍加修改。为什么是稍加修改,是因为原代码跑不出来!!笔者在提取场输出的位移数据时,渴望偷懒,打算百度一下草草了事,奈何发现网上代码多半驴头不对马嘴,笔者明明是想提取位移,而不是节点和单元的集合!!所以被逼无奈之下,只好硬着头皮修改!欢迎各位大佬们把小弟代码更优化,然后也发给小弟,让小弟尝尝被带飞的滋味!万分感谢,给您老们拜个大年,祝各位新年新气象,文章多多,money多多!!
首先,利用python脚本对Abaqus进行数据提取时,要对python脚本做前步的导入处理。
第一个是一定要给出python脚本遍历查询的路径提示,该代码如下:
#!/usr/bin/python# -*- coding:UTF-8-*-
第二个是在调用odb数据文件时,要导入Abaqus内置的模块,代码如下:
其中 from odbAccess import* 是调用odb数据文件必须要用的。
from odbAccess import*from abaqusConstants import *from odbMaterial import *from odbSection import *import csvimport string
随后的代码编写则按照以下思路进行:
(1)打开odb对象文件
(2)创建变量表示第一个分析步
(3)创建变量表示第一个分析步的最后一帧
(4)创建变量表示节点集
(5)创建变量表示2,3步中输出的位移
其代码如下:
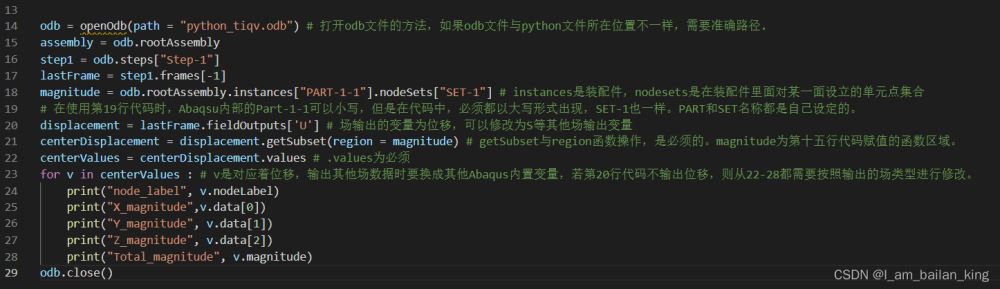
通过该代码便完成了对已生成的odb文件中的特定节点集合进行的位移提取
笔者为了验证代码的正确性,做了简单的弹性材料的梁受压模拟,利用python脚本遍历循环输出的结果如下:

若想对输出的数据再进一步优化,可以利用open()与write()等函数进行二次处理,将输出的数据直接写入到文档中方便使用。
相关推荐
-

利用python脚本提取Abaqus场输出数据的代码
笔者为科研界最后的摆烂王,目前利用python代码对Abaqus进行二次开发尚在学习中.欢迎各位摆烂的仁人志士们和我一起摆烂!ps:搞什么科研,如果不是被逼无奈,谁要搞科研! 该代码是学习过程中,对前人已有工作所做的稍加修改.为什么是稍加修改,是因为原代码跑不出来!!笔者在提取场输出的位移数据时,渴望偷懒,打算百度一下草草了事,奈何发现网上代码多半驴头不对马嘴,笔者明明是想提取位移,而不是节点和单元的集合!!所以被逼无奈之下,只好硬着头皮修改!欢迎各位大佬们把小弟代码更优化,然后也发给小弟,让小
-
利用python对Excel中的特定数据提取并写入新表的方法
最近刚开始学python,正好实习工作中遇到对excel中的数据进行处理的问题,就想到利用python来解决,也恰好练手. 实际的问题是要从excel表中提取日期.邮件地址和时间,然后统计在一定时间段内某个人在某个项目上用了多少时间,最后做成一张数据透视表(这是问题的大致意思). 首先要做的就是数据提取了,excel中本身有一个text to column的功能,但是对列中规律性不好的数据处理效果很差,不能分割出想要的数据,所以我果断选择用python来完成. 要用的库一个是对excel读写处理
-
Python脚本提取fasta文件单序列信息实现
目录 Python脚本编辑 使用的文件 输入 sys模块 从命令行获得文件名称 进行序列信息统计的函数 使用def制作一个函数 .format使用: 进行函数计算 结果屏幕展示 结果输出文件 脚本运行 Python脚本编辑 使用Python对fasta格式的序列进行基本信息统计 预期设计输出文件中包括fasta文件名,序列长度,GC含量以及ATCG各自的含量. 使用的文件 test.fasta stat.py 输入 sys模块 #!/usr/bin/env python import sys 从
-
如何利用python批量提取txt文本中所需文本并写入excel
目录 1.提取txt文本 2.增加数据框的列 3.引入基础csv数据,并扩列 汇总 总结 1.提取txt文本 我想要的文本是如图所示,宝可梦的外貌描述文本,由于原本的数据源结构并不是很稳定,而且也不是表格形式,因此在csdn上查了半天. 最原始的一行一行提取(不建议,未采用) fi = open("D:\python_learning\data\data\Axew.txt","r",encoding="utf-8") wflag =False #
-
使用Python脚本提取基因组指定位置序列
引言 在基因组分析中,我们经常会有这么一个需求,就是在一个fasta文件中提取一些序列出来.有时这些序列是一段完整的序列,而有时仅仅为原fasta文件中某段序列的一部分.特别是当数据量很多时,使用肉眼去挑选序列会很吃力,那么这时我们就可以通过简单的编程去实现了. 例如此处在网盘附件中给定了某物种的全基因组序列(0-refer/ Bacillus_subtilis.str168.fasta),及其基因组gff注释文件(0-refer/ Bacillus_subtilis.str168.gff).
-
利用Python脚本实现自动刷网课
人在学校,身不由己.总有一些奇奇怪怪的学习任务,需要我们刷够一定的时长去完成,但这很多都是不太令人感兴趣的文字或是视频,而这些课都有共同的特点就是会间隔一定时间发出弹窗,确认屏幕前的我们是否还在浏览页面.每次靠人工去点击,会严重影响我们做其他正事的效率. 最近小李也需要刷够一定的学习时长.于是乎,我便找了好兄弟Python来帮忙.下面我们就用Python来实现自动化刷课吧! 说到自动化,Selenium这个浏览器自动化测试框架就派上了用场,整个自动刷课的主角便是它. 网站登录 那么为了实现自动刷
-
利用Python脚本批量生成SQL语句
通过Python脚本批量生成插入数据的SQL语句 原始SQL语句: INSERT INTO system_user (id, login_name, name, password, salt, code, createtime, email, main_org, positions, status, used, url, invalid, millis, id_card, phone_no, past, end_date, start_date) VALUES ('6', 'db', 'db',
-
利用Python多处理库处理3D数据详解
今天我们将介绍处理大量数据时非常方便的工具.我不会只告诉您可能在手册中找到的一般信息,而是分享一些我发现的小技巧,例如tqdm与 multiprocessingimap一起使用.并行处理档案.绘制和处理 3D 数据以及如何搜索如果您有点云,则用于对象网格中的类似对象. 那么我们为什么要求助于并行计算呢?如今,如果您处理任何类型的数据,您可能会面临与"大数据"相关的问题.每次我们有不适合 RAM 的数据时,我们都需要一块一块地处理它.幸运的是,现代编程语言允许我们生成在多核处理器
-
利用Python对中国500强排行榜数据进行可视化分析
目录 一.前言 二.数据采集 1.开始爬取 获取企业列表 获取企业对应url 获取每一个企业相关数据 2.保存到Excel 三.可视化分析 1.省份分布 导入相关可视化库 统计数据 地图可视化 2.营业收入年增率 3.营业收入年减率 4.利润年增率 5.利润年减率 6.排名上升最快20家企业 7.排名下降最快20家企业 8.资产区间分布 9.市值区间分布 10.营业收入区间分布 11.利润区间分布 12.中国500强企业-排名前10营业收入.利润.资产.市值.股东权益 四.总结 一.前言 今天来
-
如何利用python在剪贴板上读取/写入数据
目录 读取剪贴板上的数据 将数据写入剪贴板 补充:python 剪切板写入文件,产生随机数写入剪切板 总结 读取剪贴板上的数据 先给大家介绍pandas.read_clipboard,从剪贴板读取文本并传递到Read_csv. pandas.read_clipboard(sep='\\s+', **kwargs) 其中参数sep是字段定界符,默认为’\s+’,也就是说将tab和多个空格都当成一样的分隔符. 接下来执行操作,打开表格→选中数据Ctrl+C复制→再执行以下代码 import pand