前端框架ECharts dataset对数据可视化的高级管理
目录
- dataset 管理数据
dataset 管理数据
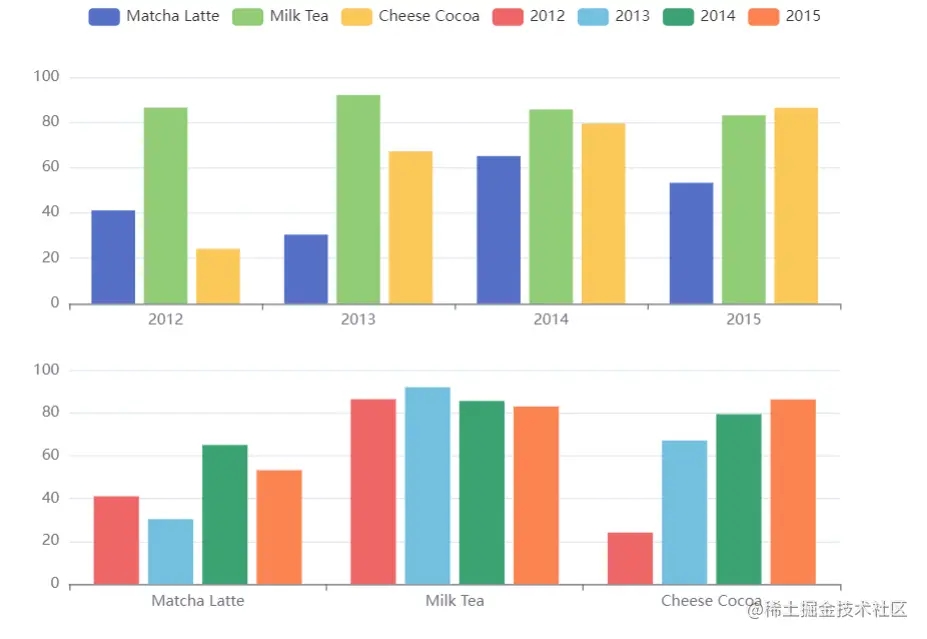
提供一份数据。 声明一个 X 轴,类目轴(category)。默认情况下,类目轴对应到声明多个 bar 系列,默认情况下,每个系列会自动对应到 dataset 的每一列。
option = {
legend: {},
tooltip: {},
dataset: {
//
source: [
['product', '2015', '2016', '2017'],
['Matcha Latte', 43.3, 85.8, 93.7],
['Milk Tea', 83.1, 73.4, 55.1],
['Cheese Cocoa', 86.4, 65.2, 82.5],
['Walnut Brownie', 72.4, 53.9, 39.1]
]
},
//dataset 第一列。
xAxis: {type: 'category'},
// 声明一个 Y 轴,数值轴。
yAxis: {},
//
series: [
{type: 'bar'},
{type: 'bar'},
{type: 'bar'}
]
}
Apache EChartsTM 4开始支持数据集组件进行单独的数据集声明,以便数据可以单独管理,由多个组件重用,并且可以基于数据指定数据到可视化的映射。这可以在许多场景中带来方便。 在ECharts 4之前,数据只能以“series”形式声明,
option = {
xAxis: {
type: 'category',
data: ['Matcha Latte', 'Milk Tea', 'Cheese Cocoa', 'Walnut Brownie']
},
yAxis: {},
series: [
{
type: 'bar',
name: '2015',
data: [89.3, 92.1, 94.4, 85.4]
},
{
type: 'bar',
name: '2016',
data: [95.8, 89.4, 91.2, 76.9]
},
{
type: 'bar',
name: '2017',
data: [97.7, 83.1, 92.5, 78.1]
}
]
}
该方法的优点是直观、易于理解,适用于某些特殊图表类型的特定数据类型定制。然而,缺点是为了匹配这种数据输入形式,通常需要有一个数据处理过程,并将数据分割设置为每个系列(和类别轴)。此外,这不利于多个系列共享一个数据,也不利于基于原始数据的图表类型和系列的映射排列。 因此,ECharts 4提供了一个单独声明数据的数据集组件,这带来了以下效果: 它可以接近数据可视化的常见思维模式:(I)提供数据,(II)指定数据到视觉的映射,从而形成图表。 数据和其他配置可以分开。数据始终在变化,其他配置始终不变。分离易于单独管理。 数据可以被多个系列或组件重用。对于具有大量数据的场景,不必为每个系列创建一个数据。 支持更常见的数据格式,如二维数组、对象数组等,在一定程度上避免用户转换为数据格式。
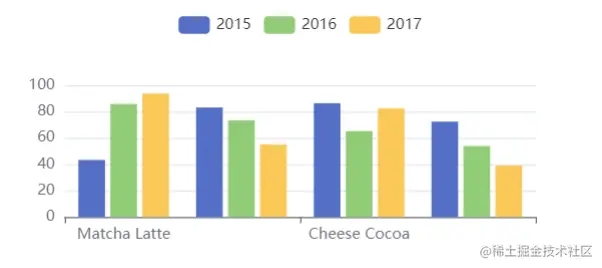
用 dimensions 指定了维度的顺序。直角坐标系中, 默认把第一个维度映射到 X 轴上,第二个维度映射到 Y 轴上。如果不指定 dimensions,也可以通过指定 series.encode,完成映射。
option = {
legend: {},
tooltip: {},
dataset: {
dimensions: ['product', '2015', '2016', '2017'],
source: [
{product: 'Matcha Latte', '2015': 43.3, '2016': 85.8, '2017': 93.7},
{product: 'Milk Tea', '2015': 83.1, '2016': 73.4, '2017': 55.1},
{product: 'Cheese Cocoa', '2015': 86.4, '2016': 65.2, '2017': 82.5},
{product: 'Walnut Brownie', '2015': 72.4, '2016': 53.9, '2017': 39.1}
]
},
xAxis: {type: 'category'},
yAxis: {},
series: [
{type: 'bar'},
{type: 'bar'},
{type: 'bar'}
]
};
一目了然,可以进行以下映射: 指定数据集的列或行是否映射到一系列图形。您可以使用SeriesLayoutBy属性。默认值是按列映射。
series: {
// 注意维度序号(dimensionIndex)从 0 开始计数,第三列是 dimensions[2]。
encode: {x: 2, y: 4},
...
}
指定维度映射规则:如何将数据集维度(“维度”表示行/列)映射到坐标轴(如X和Y轴)、工具提示、标签、图形元素大小和颜色(visualMap)。您可以使用series配置encode属性和visualMap组件(如果需要映射的颜色大小等视觉维度)。在上面的示例中,ECharts没有提供这种映射配置,因此ECharts将根据最常见的理解执行默认映射:X坐标轴声明为类别轴,默认情况下将自动对应于数据集源中的第一列;三列图表系列,逐一对应数据集源中的每个后续列。
series: {
encode: {x: 2, y: 4},
seriesLayoutBy: 'row',
...
}
在系列中设置的 dimensions 会更优先采纳。可以在 type 中指定维度类型。可以简写为 string,表示维度名。
var option1 = {
dataset: {
dimensions: [
{name: 'score'},
//
'amount',
//
{name: 'product', type: 'ordinal'}
],
source: [...]
},
...
};
var option2 = {
dataset: {
source: [...]
},
series: {
type: 'line',
//
dimensions: [
null, // 可以设置为 null 表示不想设置维度名
'amount',
{name: 'product', type: 'ordinal'}
]
},
...
};
在大多数常见的图表中,数据可以以二维表格的形式描述。广泛使用的数据表软件(如MS Excel、Numbers)或关系数据数据库是二维表。它们的数据可以导出为JSON格式并输入到数据集。在源代码中,在许多情况下可以省略一些数据处理步骤。 如果数据导出到csv文件,则可以使用一些csv工具(如dsv或PapaParse)将csv转换为JSON。 在JavaScript的常见数据传输格式中,二维数组可以直观地存储二维表。前面的示例都由二维数组表示。 除了二维数组,数据集还支持以下键值数据格式,这些格式也非常常见。但是,seriesLayoutBy参数在此类格式中不受支持。 按行的 key-value 形式(对象数组),这是个比较常见的格式。 按列的 key-value 形式。
dataset: [{
//
source: [
{product: 'Matcha Latte', count: 823, score: 95.8},
{product: 'Milk Tea', count: 235, score: 81.4},
{product: 'Cheese Cocoa', count: 1042, score: 91.2},
{product: 'Walnut Brownie', count: 988, score: 76.9}
]
}, {
//
source: {
'product': ['Matcha Latte', 'Milk Tea', 'Cheese Cocoa', 'Walnut Brownie'],
'count': [823, 235, 1042, 988],
'score': [95.8, 81.4, 91.2, 76.9]
}
}]

目前,并非所有图表都支持数据集。支持数据集的图表包括直线、条形图、饼图、扫描仪、效应扫描仪、平行线、烛台、地图、基金和自定义。未来将有更多图表可供支持。 最后,给出一个例子。多个图表共享具有链接交互的数据集。
以上就是前端框架ECharts dataset对数据可视化的高级管理的详细内容,更多关于ECharts dataset数据可视化管理的资料请关注我们其它相关文章!
相关推荐
-

使用antv替代Echarts实现数据可视化图表详解
目录 前言 面积图 常用参数文档 图表 度量 scale 提示 tooltip 坐标系 axis chart.line(options) chart.area(options) geom.position() geom.color() geom.shape() 柱状图 数据标签 label chart.coordinate() chart.interval(options) 地图 地图容器配置项 map 地图等级 viewLevel 小结 前言 技术永无止尽,多看看不同风景 周一,还在愉快的为移
-
ECharts异步加载数据与数据集(dataset)
目录 异步加载数据 数据的动态更新 数据集(dataset) 数据到图形的映射 视觉通道(颜色.尺寸等)的映射 交互联动 异步加载数据 ECharts 通常数据设置在 setOption 中,如果我们需要异步加载数据,可以配合 jQuery等工具,在异步获取数据后通过 setOption 填入数据和配置项就行. json 数据: { "data_pie" : [ {"value":235, "name":"视频广告"}, {&
-
ECharts的三维可视化及在微信小程序中使用示例
目录 在微信小程序中使用 ECharts 三维可视化 在微信小程序中使用 ECharts 关于微信小程序的项目创建. 创建项目后,可以用新项目完全替换weixin项目下载的电子商务/图表,然后修改代码:或者只需将ec画布目录复制到新项目,然后进行相应的调整. 如果采用完全替换的方法,则project.config json中的appid将替换为公共平台上应用的项目id. pages目录下的每个文件夹都是一个页面.可以根据情况删除不必要的页面,然后单击应用程序删除json中的相应页面. 如果只复制
-
JavaScript实现echarts水球图百分比展示大屏可视化
目录 前言: 示例: 简介: 代码实现 项目文件中引入 声明实例,设置参数,绘制水球图 设置缩放 总结: 前言: 掘友们,大家晚上好啊.今天突然的看到之前的同学,在宿舍群里询问关于echarts水球图的问题,刚好,小编在之前做大屏可视化的时候,关于电脑磁盘空间的存储量做了水球图的展示,我就简单的给他分享了制作过程. 示例: 水球图的应用场景很广泛,一般最多的就是应用于容量大小的展示,使用空间的多少.这里先编以自己的项目为例,向大家展示. 简介: echarts已经升级到了V5版本,但是我们从官方
-
Pyecharts绘制可视化地球实现示例
目录 正文 数据处理 Pyecharts 绘图 部署为 Web 服务 tup2 正文 今天我们使用 Pyecharts 制作一个地球可视化项目,一起来看看吧 Let’s go! 数据处理 这里我们使用全球新冠感染人数的数据集作为我们的测试数据,先来看看数据的整体情况 import pandas as pd df = pd.read_csv("owid-covid-data.csv") df_0608 = df[df['date'] == '2022-06-08'] df_new = d
-
JavaScript可视化与Echarts详细介绍
目录 一.可视化介绍 二.可视化库介绍 三.Echarts Echarts引入和使用 了解基础配置 一.可视化介绍 可视化:将数据用图表展示出来,让数据更加直观.让数据特点更加突出 应用场景:营销数据.生产数据.用户数据 二.可视化库介绍 常见的数据可视化库: D3.js:目前 Web 端评价最高的 Javascript 可视化工具库(入手难) ECharts.js:百度出品的一个开源 Javascript 数据可视化库 Highcharts.js:国外的前端数据可视化库,非商用免费,被许多国外
-
前端框架ECharts dataset对数据可视化的高级管理
目录 dataset 管理数据 dataset 管理数据 提供一份数据. 声明一个 X 轴,类目轴(category).默认情况下,类目轴对应到声明多个 bar 系列,默认情况下,每个系列会自动对应到 dataset 的每一列. option = { legend: {}, tooltip: {}, dataset: { // source: [ ['product', '2015', '2016', '2017'], ['Matcha Latte', 43.3, 85.8, 93.7], ['
-
SpringBoot+thymeleaf+Echarts+Mysql 实现数据可视化读取的示例
目录 实现过程 1. pom.xml 2. 后端程序示例 3. 前端程序示例 通过从数据库获取数据转为JSON数据,返回前端界面实现数据可视化. 数据可视化测试 实现过程 1. pom.xml pom.xml引入(仅为本文示例需要,其他依赖自行导入) <!--Thymeleaf整合security--> <dependency> <groupId>org.thymeleaf.extras</groupId> <artifactId>thymele
-
layui前端框架之table表数据的刷新方法
最简单的方法就是: //当前页的刷新 $(".layui-laypage-btn")[0].click(); 以上这篇layui前端框架之table表数据的刷新方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们.
-
前端框架Vue父子组件数据双向绑定的实现
目录 一.父子组件单向传值 1.父向子传值 2.子向父传值 二.父子组件数据双向绑定 实现思路: 父 向 子 组件传值:使用 props 属性.( props 是property[属性] 的复数简写 ) 子 向 父 组件传值:使用自定义事件. 一.父子组件单向传值 1.父向子传值 父向子组件传值,子组件接收到数据之后,保存到自己的变量中. //父组件写法 <cld :numP="num" ></cld> //子组件定义以及数据 components:{ cld:
-
SpringBoot+Thymeleaf+ECharts实现大数据可视化(基础篇)
目录 0x01 新建SpringBoot项目 2. 编写HelloWorld程序代码 0x02 引入ECharts资源 1. 获取JQuery与ECharts资源 2. 新建ECharts模版html文件 3. 添加后台java代码 4. ECharts模版样式预览 0x03 SpringBoot整合Thymeleaf 1. 新建myECharts方法 2. 引入Thymeleaf 3. ECharts新样式预览 4. 模式升级 0xFF 总结 0x01 新建SpringBoot项目 1. 新建
-
vue基于Echarts的拖拽数据可视化功能实现
背景 我司产品提出了一个需求,做一个数据基于Echars的可拖拽缩放的数据可视化,上网百度了一番,结果出现了两种结局,一种花钱买成熟产品(公司不出钱),一种没有成熟代码,只能自己写了,故事即将开始,敬请期待....... 不,还是先上一张效果图吧,请看...... 前期知识点 1. offset(偏移量) 定义:当前元素在屏幕上占用的空间,如下图: 其中: offsetHeight: 该元素在垂直方向上的占用的空间,单位为px,不包括margin. offsetWidth:该元素在水平方向上的
-
详解Vue2+Echarts实现多种图表数据可视化Dashboard(附源码)
数据可视化 将数据通过图表的形式展现出来将大大的提升可读性和阅读效率 本例包含柱状图.折线图.散点图.热力图.复杂柱状图.预览面板等 技术栈 vue2.x vuex 存储公共变量,如色值等 vue-router 路由 element-ui 饿了么基于vue2开发组件库,本例使用了其中的datePicker echarts 一款丰富的图表库 webpack.ES6.Babel.Stylus... 项目截图 开发 组件化 本项目完全采用组件化的思想进行开发.使用vue-router作为路由,每个页面
-
基于vue+echarts数据可视化大屏展示的实现
获取 ECharts 的路径有以下几种,请根据您的情况进行选择: 1) 最直接的方法是在 ECharts 的官方网站中挑选适合您的版本进行下载,不同的打包下载应用于不同的开发者功能与体积的需求,或者您也可以直接下载完整版本:开发环境建议下载源代码版本,包含了常见的错误提示和警告. 2) 也可以在 ECharts 的 GitHub 上下载最新的 release 版本,解压出来的文件夹里的 dist 目录里可以找到最新版本的 echarts 库. 3) 或者通过 npm 获取 echarts,npm
-
SpringBoot+ECharts是如何实现数据可视化的
一.提出任务 查询班级表数据,利用ECharts绘制各班人数柱形图. (一)班级数据 (二)运行效果 二.实现步骤 (一)创建数据库与表 1.创建数据库 - test create database test; 2.创建数据表 - t_class 创建表结构 CREATE TABLE `t_class` ( `id` int(11) NOT NULL AUTO_INCREMENT, `class` varchar(50) CHARACTER SET utf8 COLLATE utf8_gener
-
JavaScript数据可视化:ECharts制作地图
目录 概述 注意事项 一. 使用方式 二. 实现步骤 初步实现代码 效果: geo常见配置 添加上面配置之后的效果图: 显示某一个省份(河南省) 效果 不同区域显示不同颜色 地图和散点图的结合 总结 概述 地图在我们日常的数据可视化分析中是很常见的一种展示手段,不仅美观而且很大气.尤其是在大屏展示中更是扮演着必不可缺的角色 注意事项 一. 使用方式 1.百度地图API(高德地图API) 需要申请百度API 2.矢量地图 需要准备矢量地图数据 二. 实现步骤 1.ECharts最基本的代码结构 引