如何使用python生成大量数据写入es数据库并查询操作
前言:
模拟学生成绩信息写入es数据库,包括姓名、性别、科目、成绩。
示例代码1:【一次性写入10000*1000条数据】 【本人亲测耗时5100秒】
from elasticsearch import Elasticsearch
from elasticsearch import helpers
import random
import time
es = Elasticsearch(hosts='http://127.0.0.1:9200')
# print(es)
names = ['刘一', '陈二', '张三', '李四', '王五', '赵六', '孙七', '周八', '吴九', '郑十']
sexs = ['男', '女']
subjects = ['语文', '数学', '英语', '生物', '地理']
grades = [85, 77, 96, 74, 85, 69, 84, 59, 67, 69, 86, 96, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86]
datas = []
start = time.time()
# 开始批量写入es数据库
# 批量写入数据
for j in range(1000):
print(j)
action = [
{
"_index": "grade",
"_type": "doc",
"_id": i,
"_source": {
"id": i,
"name": random.choice(names),
"sex": random.choice(sexs),
"subject": random.choice(subjects),
"grade": random.choice(grades)
}
} for i in range(10000 * j, 10000 * j + 10000)
]
helpers.bulk(es, action)
end = time.time()
print('花费时间:', end - start)
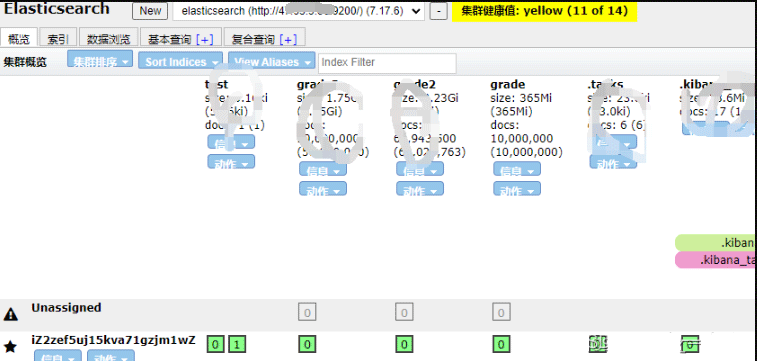
elasticsearch-head中显示:
示例代码2:【一次性写入10000*5000条数据】 【本人亲测耗时23000秒】
from elasticsearch import Elasticsearch
from elasticsearch import helpers
import random
import time
es = Elasticsearch(hosts='http://127.0.0.1:9200')
# print(es)
names = ['刘一', '陈二', '张三', '李四', '王五', '赵六', '孙七', '周八', '吴九', '郑十']
sexs = ['男', '女']
subjects = ['语文', '数学', '英语', '生物', '地理']
grades = [85, 77, 96, 74, 85, 69, 84, 59, 67, 69, 86, 96, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86]
datas = []
start = time.time()
# 开始批量写入es数据库
# 批量写入数据
for j in range(5000):
print(j)
action = [
{
"_index": "grade3",
"_type": "doc",
"_id": i,
"_source": {
"id": i,
"name": random.choice(names),
"sex": random.choice(sexs),
"subject": random.choice(subjects),
"grade": random.choice(grades)
}
} for i in range(10000 * j, 10000 * j + 10000)
]
helpers.bulk(es, action)
end = time.time()
print('花费时间:', end - start)
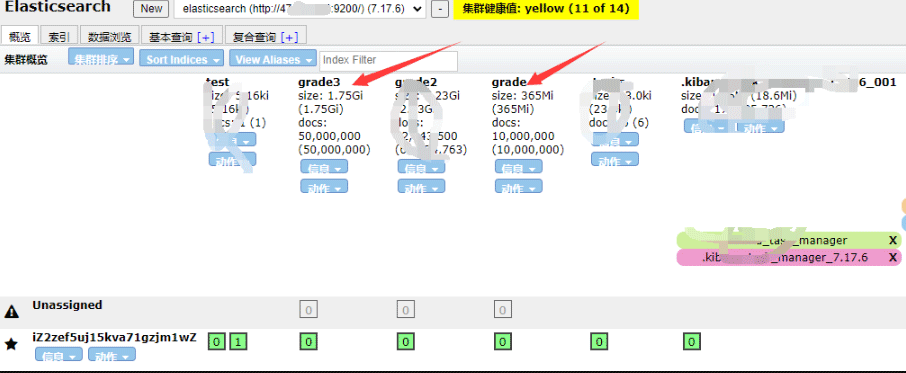
示例代码3:【一次性写入10000*9205条数据】 【耗时过长】
from elasticsearch import Elasticsearch
from elasticsearch import helpers
import random
import time
es = Elasticsearch(hosts='http://127.0.0.1:9200')
names = ['刘一', '陈二', '张三', '李四', '王五', '赵六', '孙七', '周八', '吴九', '郑十']
sexs = ['男', '女']
subjects = ['语文', '数学', '英语', '生物', '地理']
grades = [85, 77, 96, 74, 85, 69, 84, 59, 67, 69, 86, 96, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86]
datas = []
start = time.time()
# 开始批量写入es数据库
# 批量写入数据
for j in range(9205):
print(j)
action = [
{
"_index": "grade2",
"_type": "doc",
"_id": i,
"_source": {
"id": i,
"name": random.choice(names),
"sex": random.choice(sexs),
"subject": random.choice(subjects),
"grade": random.choice(grades)
}
} for i in range(10000*j, 10000*j+10000)
]
helpers.bulk(es, action)
end = time.time()
print('花费时间:', end - start)
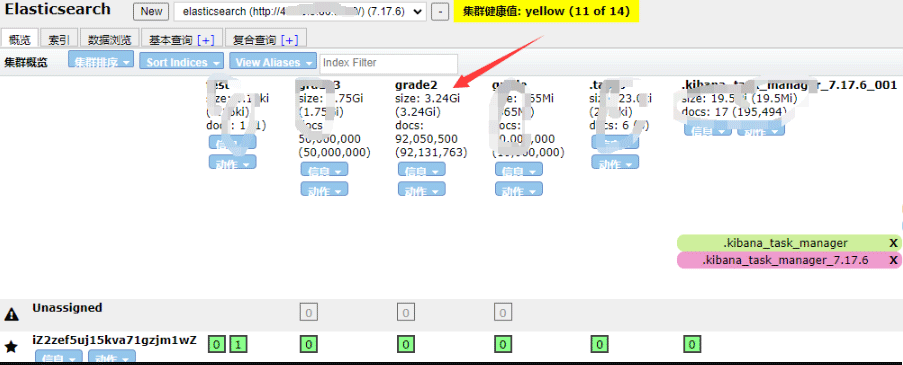
查询数据并计算各种方式的成绩总分。
示例代码4:【一次性获取所有的数据,在程序中分别计算所耗的时间】
from elasticsearch import Elasticsearch
import time
def search_data(es, size=10):
query = {
"query": {
"match_all": {}
}
}
res = es.search(index='grade', body=query, size=size)
# print(res)
return res
if __name__ == '__main__':
start = time.time()
es = Elasticsearch(hosts='http://192.168.1.1:9200')
# print(es)
size = 10000
res = search_data(es, size)
# print(type(res))
# total = res['hits']['total']['value']
# print(total)
all_source = []
for i in range(size):
source = res['hits']['hits'][i]['_source']
all_source.append(source)
# print(source)
# 统计查询出来的所有学生的所有课程的所有成绩的总成绩
start1 = time.time()
all_grade = 0
for data in all_source:
all_grade += int(data['grade'])
print('所有学生总成绩之和:', all_grade)
end1 = time.time()
print("耗时:", end1 - start1)
# 统计查询出来的每个学生的所有课程的所有成绩的总成绩
start2 = time.time()
names1 = []
all_name_grade = {}
for data in all_source:
if data['name'] in names1:
all_name_grade[data['name']] += data['grade']
else:
names1.append(data['name'])
all_name_grade[data['name']] = data['grade']
print(all_name_grade)
end2 = time.time()
print("耗时:", end2 - start2)
# 统计查询出来的每个学生的每门课程的所有成绩的总成绩
start3 = time.time()
names2 = []
subjects = []
all_name_all_subject_grade = {}
for data in all_source:
if data['name'] in names2:
if all_name_all_subject_grade[data['name']].get(data['subject']):
all_name_all_subject_grade[data['name']][data['subject']] += data['grade']
else:
all_name_all_subject_grade[data['name']][data['subject']] = data['grade']
else:
names2.append(data['name'])
all_name_all_subject_grade[data['name']] = {}
all_name_all_subject_grade[data['name']][data['subject']] = data['grade']
print(all_name_all_subject_grade)
end3 = time.time()
print("耗时:", end3 - start3)
end = time.time()
print('总耗时:', end - start)
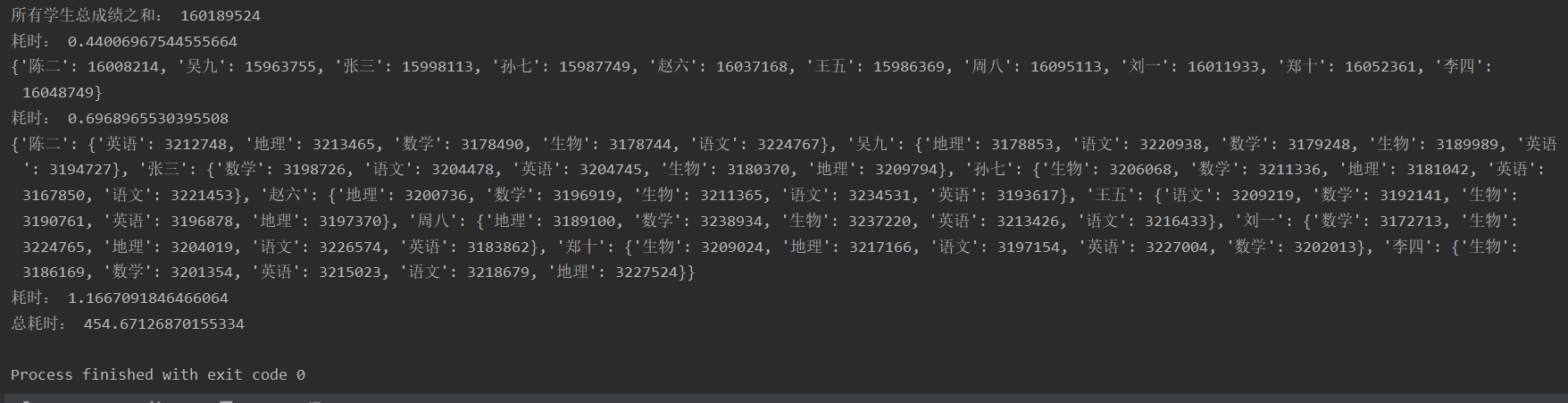
运行结果:

在示例代码4中当把size由10000改为 2000000时,运行效果如下所示:
在项目中一般不用上述代码4中所统计成绩的方法,面对大量的数据是比较耗时的,要使用es中的聚合查询。计算数据中所有成绩之和。
示例代码5:【使用普通计算方法和聚类方法做对比验证】
from elasticsearch import Elasticsearch
import time
def search_data(es, size=10):
query = {
"query": {
"match_all": {}
}
}
res = es.search(index='grade', body=query, size=size)
# print(res)
return res
def search_data2(es, size=10):
query = {
"aggs": {
"all_grade": {
"terms": {
"field": "grade",
"size": 1000
}
}
}
}
res = es.search(index='grade', body=query, size=size)
# print(res)
return res
if __name__ == '__main__':
start = time.time()
es = Elasticsearch(hosts='http://127.0.0.1:9200')
size = 2000000
res = search_data(es, size)
all_source = []
for i in range(size):
source = res['hits']['hits'][i]['_source']
all_source.append(source)
# print(source)
# 统计查询出来的所有学生的所有课程的所有成绩的总成绩
start1 = time.time()
all_grade = 0
for data in all_source:
all_grade += int(data['grade'])
print('200万数据所有学生总成绩之和:', all_grade)
end1 = time.time()
print("耗时:", end1 - start1)
end = time.time()
print('200万数据总耗时:', end - start)
# 聚合操作
start_aggs = time.time()
es = Elasticsearch(hosts='http://127.0.0.1:9200')
# size = 2000000
size = 0
res = search_data2(es, size)
# print(res)
aggs = res['aggregations']['all_grade']['buckets']
print(aggs)
sum = 0
for agg in aggs:
sum += (agg['key'] * agg['doc_count'])
print('1000万数据总成绩之和:', sum)
end_aggs = time.time()
print('1000万数据总耗时:', end_aggs - start_aggs)
运行结果:

计算数据中每个同学的各科总成绩之和。
示例代码6: 【子聚合】【先分组,再计算】
from elasticsearch import Elasticsearch
import time
def search_data(es, size=10):
query = {
"query": {
"match_all": {}
}
}
res = es.search(index='grade', body=query, size=size)
# print(res)
return res
def search_data2(es):
query = {
"size": 0,
"aggs": {
"all_names": {
"terms": {
"field": "name.keyword",
"size": 10
},
"aggs": {
"total_grade": {
"sum": {
"field": "grade"
}
}
}
}
}
}
res = es.search(index='grade', body=query)
# print(res)
return res
if __name__ == '__main__':
start = time.time()
es = Elasticsearch(hosts='http://127.0.0.1:9200')
size = 2000000
res = search_data(es, size)
all_source = []
for i in range(size):
source = res['hits']['hits'][i]['_source']
all_source.append(source)
# print(source)
# 统计查询出来的每个学生的所有课程的所有成绩的总成绩
start2 = time.time()
names1 = []
all_name_grade = {}
for data in all_source:
if data['name'] in names1:
all_name_grade[data['name']] += data['grade']
else:
names1.append(data['name'])
all_name_grade[data['name']] = data['grade']
print(all_name_grade)
end2 = time.time()
print("200万数据耗时:", end2 - start2)
end = time.time()
print('200万数据总耗时:', end - start)
# 聚合操作
start_aggs = time.time()
es = Elasticsearch(hosts='http://127.0.0.1:9200')
res = search_data2(es)
# print(res)
aggs = res['aggregations']['all_names']['buckets']
# print(aggs)
dic = {}
for agg in aggs:
dic[agg['key']] = agg['total_grade']['value']
print('1000万数据:', dic)
end_aggs = time.time()
print('1000万数据总耗时:', end_aggs - start_aggs)
运行结果:
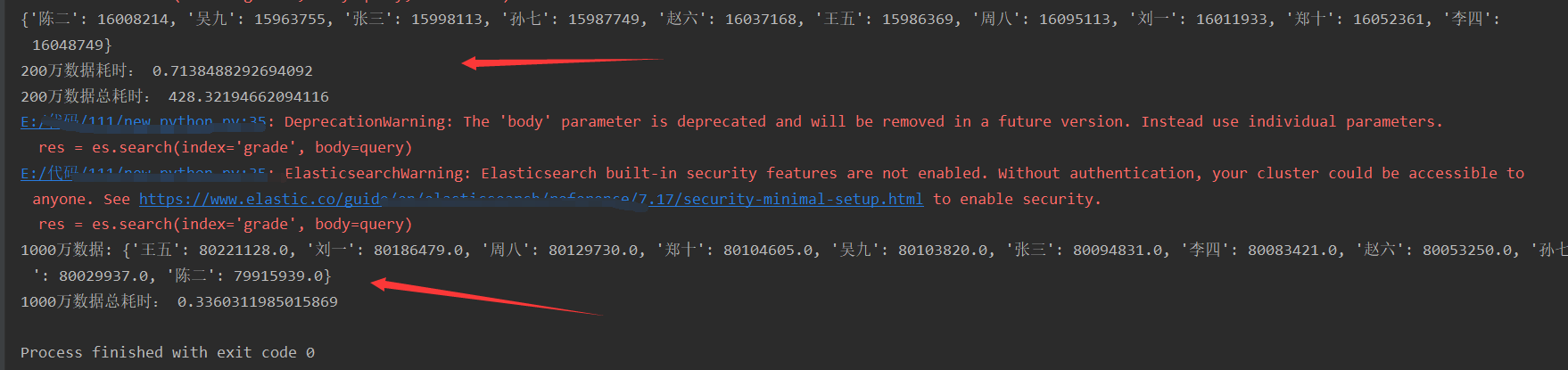
计算数据中每个同学的每科成绩之和。
示例代码7:
from elasticsearch import Elasticsearch
import time
def search_data(es, size=10):
query = {
"query": {
"match_all": {}
}
}
res = es.search(index='grade', body=query, size=size)
# print(res)
return res
def search_data2(es):
query = {
"size": 0,
"aggs": {
"all_names": {
"terms": {
"field": "name.keyword",
"size": 10
},
"aggs": {
"all_subjects": {
"terms": {
"field": "subject.keyword",
"size": 5
},
"aggs": {
"total_grade": {
"sum": {
"field": "grade"
}
}
}
}
}
}
}
}
res = es.search(index='grade', body=query)
# print(res)
return res
if __name__ == '__main__':
start = time.time()
es = Elasticsearch(hosts='http://127.0.0.1:9200')
size = 2000000
res = search_data(es, size)
all_source = []
for i in range(size):
source = res['hits']['hits'][i]['_source']
all_source.append(source)
# print(source)
# 统计查询出来的每个学生的每门课程的所有成绩的总成绩
start3 = time.time()
names2 = []
subjects = []
all_name_all_subject_grade = {}
for data in all_source:
if data['name'] in names2:
if all_name_all_subject_grade[data['name']].get(data['subject']):
all_name_all_subject_grade[data['name']][data['subject']] += data['grade']
else:
all_name_all_subject_grade[data['name']][data['subject']] = data['grade']
else:
names2.append(data['name'])
all_name_all_subject_grade[data['name']] = {}
all_name_all_subject_grade[data['name']][data['subject']] = data['grade']
print('200万数据:', all_name_all_subject_grade)
end3 = time.time()
print("耗时:", end3 - start3)
end = time.time()
print('200万数据总耗时:', end - start)
# 聚合操作
start_aggs = time.time()
es = Elasticsearch(hosts='http://127.0.0.1:9200')
res = search_data2(es)
# print(res)
aggs = res['aggregations']['all_names']['buckets']
# print(aggs)
dic = {}
for agg in aggs:
dic[agg['key']] = {}
for sub in agg['all_subjects']['buckets']:
dic[agg['key']][sub['key']] = sub['total_grade']['value']
print('1000万数据:', dic)
end_aggs = time.time()
print('1000万数据总耗时:', end_aggs - start_aggs)
运行结果:
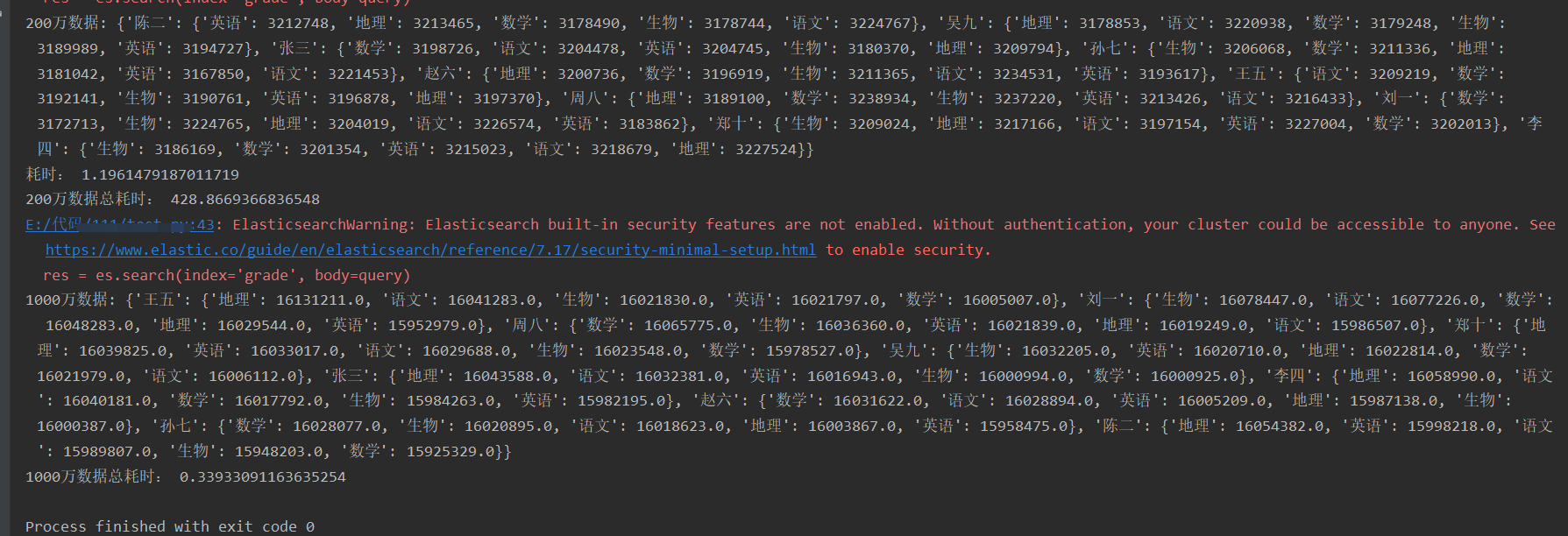
在上面查询计算示例代码中,当使用含有1000万数据的索引grade时,普通方法查询计算是比较耗时的,使用聚合查询能够大大节约大量时间。当面对9205万数据的索引grade2时,这时使用普通计算方法所消耗的时间太大了,在线上开发环境中是不可用的,所以必须使用聚合方法来计算。
示例代码8:
from elasticsearch import Elasticsearch
import time
def search_data(es):
query = {
"size": 0,
"aggs": {
"all_names": {
"terms": {
"field": "name.keyword",
"size": 10
},
"aggs": {
"all_subjects": {
"terms": {
"field": "subject.keyword",
"size": 5
},
"aggs": {
"total_grade": {
"sum": {
"field": "grade"
}
}
}
}
}
}
}
}
res = es.search(index='grade2', body=query)
# print(res)
return res
if __name__ == '__main__':
# 聚合操作
start_aggs = time.time()
es = Elasticsearch(hosts='http://127.0.0.1:9200')
res = search_data(es)
# print(res)
aggs = res['aggregations']['all_names']['buckets']
# print(aggs)
dic = {}
for agg in aggs:
dic[agg['key']] = {}
for sub in agg['all_subjects']['buckets']:
dic[agg['key']][sub['key']] = sub['total_grade']['value']
print('9205万数据:', dic)
end_aggs = time.time()
print('9205万数据总耗时:', end_aggs - start_aggs)
运行结果:

注意:写查询语句时建议使用kibana去写,然后复制查询语句到代码中,kibana会提示查询语句。
到此这篇关于如何使用python生成大量数据写入es数据库并查询操作的文章就介绍到这了,更多相关python es 内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python实现mysql数据库中的SQL文件生成和导入
目录 1.将mysql数据导出到SQL文件中(数据库存在的情况) 2.将现有的sql文件数据导入到数据库中(前提数据库存在) 3.利用Navicat导出SQL文件和导入SQL文件 1)从数据库导出SQL文件 2)导入SQL文件到数据库 1.将mysql数据导出到SQL文件中(数据库存在的情况) 主要需要修改数据库的相关信息,端口号.用户名.密码等 其中数据库得存在,不然会报错 : #!/usr/bin/env python # -*- coding: utf-8 -*- # @descripti
-
Python读取Excel数据实现批量生成合同
目录 一.背景 二.准备 三.实战 1.安装相关库 2.读取合同数据 3.批量合同生成 大家好,我是J哥. 在我们的工作中,面临着大量的重复性工作,通过人工方式处理往往耗时耗力易出错.而Python在自动化办公方面具有极大的优势,可以解决我们工作中遇到的很多重复性问题,分分钟搞定办公需求. 一.背景 在我们经济交往中,有时会涉及到销售合同的批量制作.比如我们需要根据如下合同数据(Excel),进行批量生成销售合同(Word). 二.准备 我们首先要准备好一份合同模板(Word),将需要替换的合同
-
Python读取Excel数据实现批量生成PPT
目录 背景 需求 准备 PPT数据 PPT模板 实战 导入相关模块 读取电影数据 读取PPT模板插入数据 背景 大家好,我是J哥. 我们常常面临着大量的重复性工作,通过人工方式处理往往耗时耗力易出错.而Python在办公自动化方面具有天然优势,分分钟解决你的办公需求,提前下班不是梦. 需求 前几天我发表了一篇办公自动化文章Python读取Excel数据并批量生成合同,获得许多小伙伴的认可和喜欢.其中有一位粉丝提议,能否出一篇PPT自动化的教程,通过读取Excel数据批量生成幻灯片.于是,我以豆瓣
-
Python Request爬取seo.chinaz.com百度权重网站的查询结果过程解析
一:脚本需求 利用Python3查询网站权重并自动存储在本地数据库(Mysql数据库)中,同时导出一份网站权重查询结果的EXCEL表格 数据库类型:MySql 数据库表单名称:website_weight 表单内容及表头设置:表头包含有id.main_url(即要查询的网站).website_weight(网站权重) 要查询的网站:EXCEL表格 二:需求实现 一:利用openpyxl模块解析excel文件,将查询的网站读取到一个列表中保存 # 解析excel文件,取出所有的url def ge
-
利用Python实现自动生成数据日报
目录 前言 需求详解 数据处理 前言 人生苦短,快学Python! 日报,是大部分打工人绕不过的难题. 对于管理者来说,日报是事前管理的最好抓手,可以了解团队的氛围和状态.可对于员工来说,那就有的聊了.对于重复性的工作,我非常推荐大家使用Python将其变成模块化.自动化,帮助我们实现高效办公. 下面我们通过一个补写销售日报的案例,展示一下Python自动化办公的优势.本文简化了案例的流程. 需求详解 朋友的需求是这样的,他们平时的销售数据是记录在Excel上,汇总后会按照部门进行统计.但是今年
-
使用python生成大量数据写入es数据库并查询操作(2)
目录 方案一 方案二 1.顺序插入5000000条数据 2.批量插入5000000条数据 3.批量插入50000000条数据 前言 : 上一篇文章:如何使用python生成大量数据写入es数据库并查询操作 模拟学生个人信息写入es数据库,包括姓名.性别.年龄.特点.科目.成绩,创建时间. 方案一 在写入数据时未提前创建索引mapping,而是每插入一条数据都包含了索引的信息. 示例代码:[多线程写入数据][一次性写入10000*1000条数据] [本人亲测耗时3266秒] from elast
-
如何使用python生成大量数据写入es数据库并查询操作
前言: 模拟学生成绩信息写入es数据库,包括姓名.性别.科目.成绩. 示例代码1:[一次性写入10000*1000条数据] [本人亲测耗时5100秒] from elasticsearch import Elasticsearch from elasticsearch import helpers import random import time es = Elasticsearch(hosts='http://127.0.0.1:9200') # print(es) names = ['刘
-
Python将json文件写入ES数据库的方法
1.安装Elasticsearch数据库 PS:在此之前需首先安装Java SE环境 下载elasticsearch-6.5.2版本,进入/elasticsearch-6.5.2/bin目录,双击执行elasticsearch.bat 打开浏览器输入http://localhost:9200 显示以下内容则说明安装成功 安装head插件,便于查看管理(还可以用kibana) 首先安装Nodejs(下载地址https://nodejs.org/en/) 再下载elasticsearch-head-
-
python将Dataframe格式的数据写入opengauss数据库并查询
目录 一.将数据写入opengauss 二.python条件查询opengauss数据库中文列名的数据 一.将数据写入opengauss 前提准备: 成功opengauss数据库,并创建用户jack,创建数据库datasets. 数据准备: 所用数据以csv格式存在本地,编码格式为GB2312. 数据存入: 开始hello表未存在,那么执行程序后,系统会自动创建一个hello表(这里指定了名字为hello): 若hello表已经存在,那么会增加数据到hello表.列名需要与hello表一一对应.
-
Python实现生成随机数据插入mysql数据库的方法
本文实例讲述了Python实现生成随机数据插入mysql数据库的方法.分享给大家供大家参考,具体如下: 运行结果: 实现代码: import random as r import pymysql first=('张','王','李','赵','金','艾','单','龚','钱','周','吴','郑','孔','曺','严','华','吕','徐','何') middle=('芳','军','建','明','辉','芬','红','丽','功') last=('明','芳','','民','敏
-
Python实现将数据写入netCDF4中的方法示例
本文实例讲述了Python实现将数据写入netCDF4中的方法.分享给大家供大家参考,具体如下: nc文件为处理气象数据文件.用户可以去https://www.lfd.uci.edu/~gohlke/pythonlibs/ 搜索netCDF4,下载相应平台的whl文件,使用pip安装即可. 这里演示的写入数据操作代码如下: # -*- coding:utf-8 -*- import numpy as np ''' 输入的data的shape=(627,652) ''' def write_to_
-
Python把csv数据写入list和字典类型的变量脚本方法
如下所示: #coding=utf8 import csv import logging logging.basicConfig(level=logging.DEBUG, format='%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s', datefmt='%a, %d %b %Y %H:%M:%S', filename='readDate.log', filemode='w') ''' 该模块的主要功能,是
-
Python将列表数据写入文件(txt, csv,excel)
写入txt文件 def text_save(filename, data):#filename为写入CSV文件的路径,data为要写入数据列表. file = open(filename,'a') for i in range(len(data)): s = str(data[i]).replace('[','').replace(']','')#去除[],这两行按数据不同,可以选择 s = s.replace("'",'').replace(',','') +'\n' #去除单引号,
-
python学习将数据写入文件并保存方法
python将文件写入文件并保存的方法: 使用python内置的open()函数将文件打开,用write()函数将数据写入文件,最后使用close()函数关闭并保存文件,这样就可以将数据写入文件并保存了. 示例代码如下: file = open("ax.txt", 'w') file.write('hskhfkdsnfdcbdkjs') file.close() 执行结果: 内容扩展: python将字典中的数据保存到文件中 d = {'a':'aaa','b':'bbb'} s =
-
python 生成正态分布数据,并绘图和解析
1.生成正态分布数据并绘制概率分布图 import pandas as pd import numpy as np import matplotlib.pyplot as plt # 根据均值.标准差,求指定范围的正态分布概率值 def normfun(x, mu, sigma): pdf = np.exp(-((x - mu)**2)/(2*sigma**2)) / (sigma * np.sqrt(2*np.pi)) return pdf # result = np.random.randi