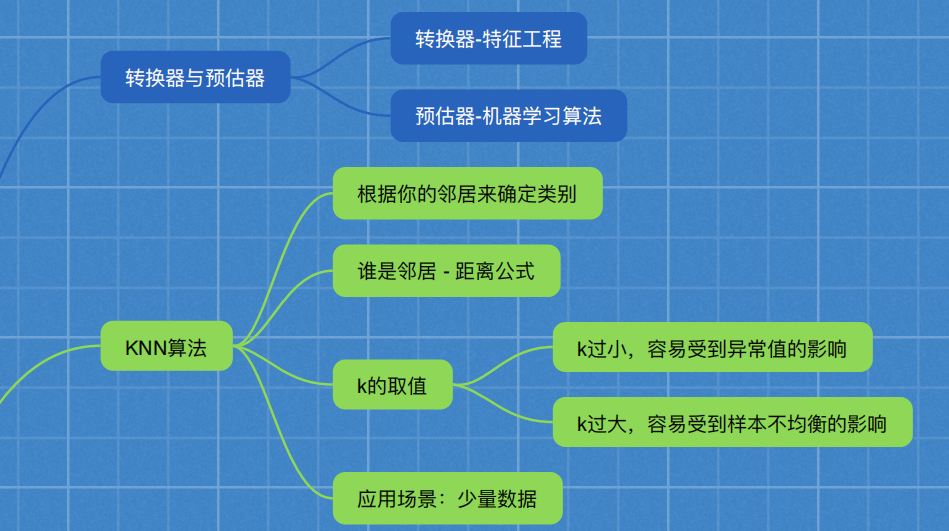
Python sklearn转换器估计器和K-近邻算法
目录
- 一、转换器和估计器
- 1. 转换器
- 2.估计器(sklearn机器学习算法的实现)
- 3.估计器工作流程
- 二、K-近邻算法
- 1.K-近邻算法(KNN)
- 2. 定义
- 3. 距离公式
- 三、电影类型分析
- 1 问题
- 2 K-近邻算法数据的特征工程处理
- 四、K-近邻算法API
- 1.步骤
- 2.代码
- 3.结果及分析
- 五、K-近邻总结
一、转换器和估计器
1. 转换器
想一下之前做的特征工程的步骤?
- 1、实例化 (实例化的是一个转换器类(Transformer))
- 2、调用fit_transform(对于文档建立分类词频矩阵,不能同时调用)
我们把特征工程的接口称之为转换器,其中转换器调用有这么几种形式:
- 标准化:(x - mean) / std
- fit_transform():fit() 计算 每一列的平均值、标准差,transform() (x - mean) / std进行最终的转换
这几个方法之间的区别是什么呢?我们看以下代码就清楚了
In [1]: from sklearn.preprocessing import StandardScaler
In [2]: std1 = StandardScaler()
In [3]: a = [[1,2,3], [4,5,6]]
In [4]: std1.fit_transform(a)
Out[4]:
array([[-1., -1., -1.],
[ 1., 1., 1.]])
In [5]: std2 = StandardScaler()
In [6]: std2.fit(a)
Out[6]: StandardScaler(copy=True, with_mean=True, with_std=True)
In [7]: std2.transform(a)
Out[7]:
array([[-1., -1., -1.],
[ 1., 1., 1.]])
从中可以看出,fit_transform的作用相当于transform加上fit。
但是为什么还要提供单独的fit呢, 我们还是使用原来的std2来进行标准化看看:
In [8]: b = [[7,8,9], [10, 11, 12]]
In [9]: std2.transform(b)
Out[9]:
array([[3., 3., 3.],
[5., 5., 5.]])
In [10]: std2.fit_transform(b)
Out[10]:
array([[-1., -1., -1.],
[ 1., 1., 1.]])
2.估计器(sklearn机器学习算法的实现)
在sklearn中,估计器(estimator)是一个重要的角色,是一类实现了算法的API
- 1 实例化一个estimator
- 2 estimator.fit(x_train, y_train) 计算—— 调用完毕,模型生成
- 3 模型评估:1)直接比对真实值和预测值y_predict = estimator.predict(x_test)
y_test == y_predict
2)计算准确率accuracy = estimator.score(x_test, y_test)
种类:1、用于分类的估计器:
- sklearn.neighbors k-近邻算法
- sklearn.naive_bayes 贝叶斯
- sklearn.linear_model.LogisticRegression 逻辑回归
- sklearn.tree 决策树与随机森林
2、用于回归的估计器:
- sklearn.linear_model.LinearRegression 线性回归
- sklearn.linear_model.Ridge 岭回归
3、用于无监督学习的估计器
- sklearn.cluster.KMeans 聚类
3.估计器工作流程

二、K-近邻算法
1.K-近邻算法(KNN)
你的“邻居”来推断出你的类别
2. 定义
如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。
来源:KNN算法最早是由Cover和Hart提出的一种分类算法
3. 距离公式
两个样本的距离可以通过如下公式计算,又叫欧式距离
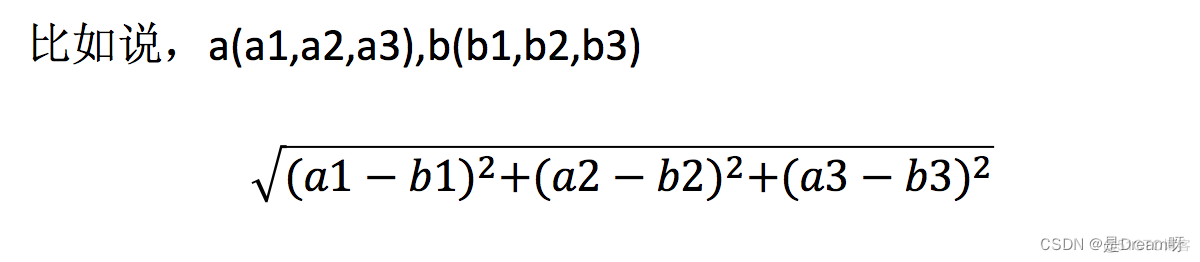
三、电影类型分析
假设我们有现在几部电影:
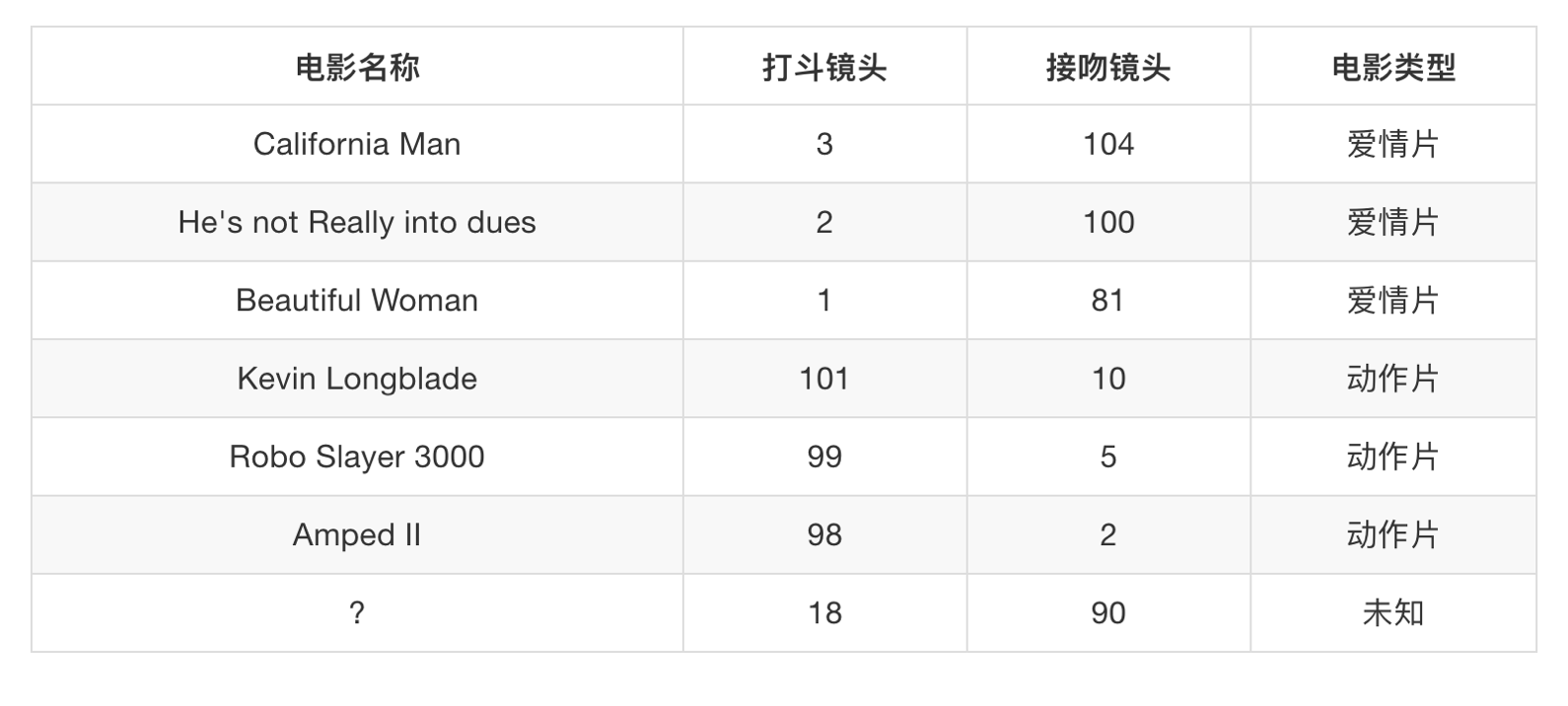
其中? 号电影不知道类别,如何去预测?我们可以利用K近邻算法的思想
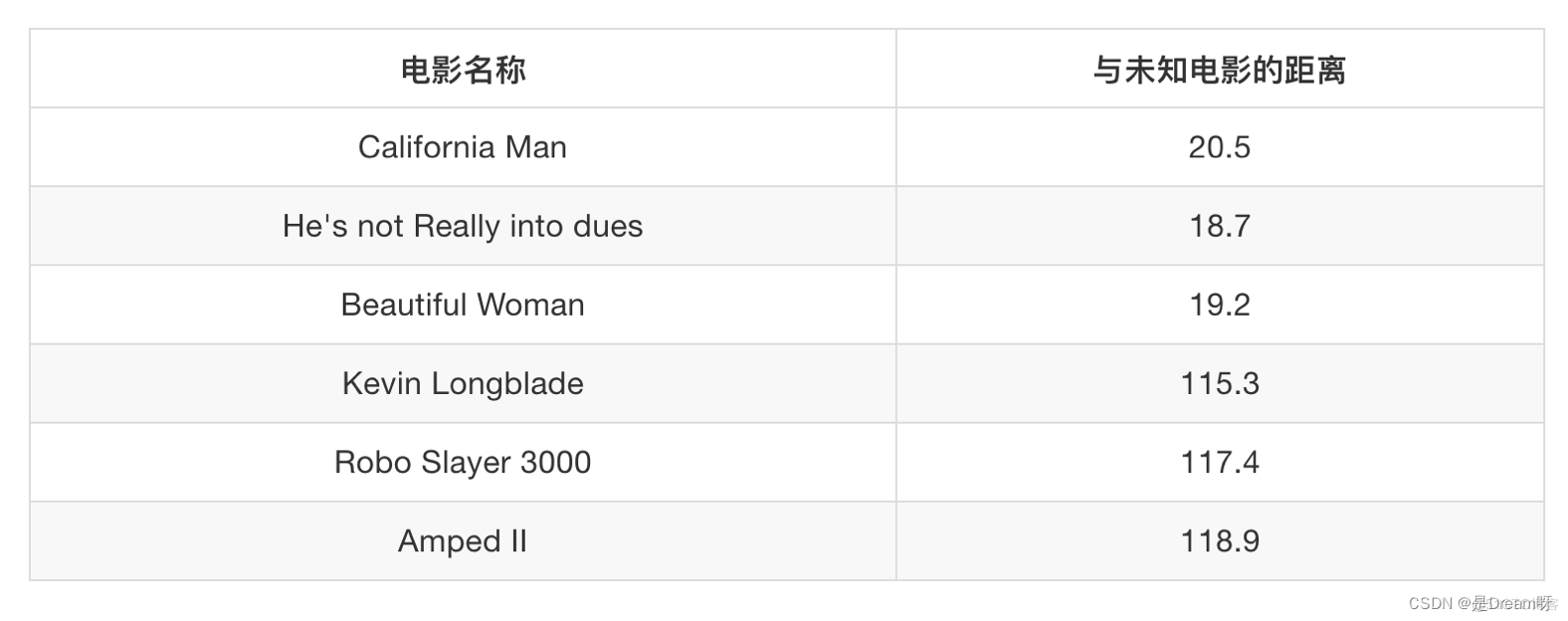
1 问题
如果取的最近的电影数量不一样?会是什么结果?
k = 1 爱情片
k = 2 爱情片
……
k = 6 无法确定
k = 7 动作片
如果取的最近的电影数量不一样?会是什么结果?
- - k 值取得过小,容易受到异常点的影响
- - k 值取得过大,样本不均衡的影响
2 K-近邻算法数据的特征工程处理
结合前面的约会对象数据,分析K-近邻算法需要做什么样的处理
- 无量纲化的处理
- 标准化
四、K-近邻算法API
sklearn.neighbors.KNeighborsClassifier(n_neighbors=5,algorithm=‘auto’)n_neighbors:k值
- n_neighbors:int,可选(默认= 5),k_neighbors查询默认使用的邻居数
- algorithm:{‘auto’,‘ball_tree’,‘kd_tree’,‘brute’},可选用于计算最近邻居的算法:‘ball_tree’将会使用 BallTree,‘kd_tree’将使用 KDTree。‘auto’将尝试根据传递给fit方法的值来决定最合适的算法。 (不同实现方式影响效率)
1.步骤
鸢尾花种类预测:数据,我们用的就是sklearn中自带的鸢尾花数据。
- 1)获取数据
- 2)数据集划分
- 3)特征工程
- 标准化
- 4)KNN预估器流程
- 5)模型评估
2.代码
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
def knn_iris():
"""
用KNN算法对鸢尾花进行分类
:return:
"""
# 1)获取数据
iris = load_iris()
# 2)划分数据集
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, random_state=22)
# 3)特征工程:标准化
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
# 4)KNN算法预估器
estimator = KNeighborsClassifier(n_neighbors=3)
estimator.fit(x_train, y_train)
# 5)模型评估
# 方法1:直接比对真实值和预测值
y_predict = estimator.predict(x_test)
print("y_predict:\n", y_predict)
print("直接比对真实值和预测值:\n", y_test == y_predict)
# 方法2:计算准确率
score = estimator.score(x_test, y_test)
print("准确率为:\n", score)
return None
3.结果及分析
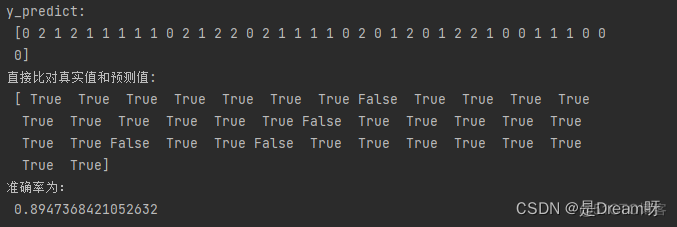
结果分析:准确率: 分类算法的评估之一
1、k值取多大?有什么影响?
k值取很小:容易受到异常点的影响k值取很大:受到样本均衡的问题
2、性能问题?
距离计算上面,时间复杂度高
五、K-近邻总结
优点:简单,易于理解,易于实现,无需训练
缺点:
- 懒惰算法,对测试样本分类时的计算量大,内存开销大
- 必须指定K值,K值选择不当则分类精度不能保证
使用场景: 小数据场景,几千~几万样本,具体场景具体业务去测试
到此这篇关于Python sklearn转换器估计器和K-近邻算法的文章就介绍到这了,更多相关Python sklearn 内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

python机器学习sklearn实现识别数字
目录 简介 数据集 数据处理 数据分离 训练数据 数据可视化 完整代码 简介 本文主要简述如何通过sklearn模块来进行预测和学习,最后再以图表这种更加直观的方式展现出来 数据集 学习数据 预测数据 数据处理 数据分离 因为我们打开我们的的学习数据集,最后一项是我们的真实数值,看过小唐上一篇的人都知道,老规矩先进行拆分,前面的特征放一块,后面的真实值放一块,同时由于数据没有列名,我们选择使用iloc[]来实现分离 def shuju(tr_path,ts_path,sep='\t'): tra
-
python sklearn 画出决策树并保存为PDF的实现过程
目录 利用sklearn画出决策树并保存为PDF 下载Graphviz python sklearn 决策树运用 数据形式(tree.csv) 利用sklearn画出决策树并保存为PDF 下载Graphviz 进入官网下载并安装: https://graphviz.gitlab.io/_pages/Download/Download_windows.html 并将下列路径配置为环境变量: D:\software\Graphviz\bin 在cmd中测试: dot -version python代
-
python机器学习Sklearn实战adaboost算法示例详解
目录 pandas批量处理体测成绩 adaboost adaboost原理案例举例 弱分类器合并成强分类器 pandas批量处理体测成绩 import numpy as np import pandas as pd from pandas import Series,DataFrame import matplotlib.pyplot as plt data = pd.read_excel("/Users/zhucan/Desktop/18级高一体测成绩汇总.xls") cond =
-
用Python制作简单的朴素基数估计器的教程
假设你有一个很大的数据集,非常非常大,以至于不能全部存入内存.这个数据集中有重复的数据,你想找出有多少重复的数据,但数据并没有排序,由于数据量太大所以排序是不切实际的.你如何来估计数据集中含有多少无重复的数据呢?这在许多应用中是很有用的,比如数据库中的计划查询:最好的查询计划不仅仅取决于总共有多少数据,它也取决于它含有多少无重复的数据. 在你继续读下去之前,我会引导你思考很多,因为今天我们要讨论的算法虽然很简单,但极具创意,它不是这么容易就能想出来的. 一个简单的朴素基数估计器 让我们从一个简单
-
基于Python实现简易文档格式转换器
目录 需求分析 开发环境 引用模块 UI界面代码块 格式转换主要代码块 效果展示 最近看到市场上各种的文档格式转换软件,要么是收费.要么是有大量的广告.于是学习了一下 PyQt5 的页面操作,再加上了解 pandas 的使用方法.所以,萌生了想法写一个简单的文档格式转换应用.或者有更好的实现方式请在评论区留言,大家一起讨论学习~ 需求分析 1.将 .txt 的文本文档转换成 csv 格式文件. 2.将 .txt 的文本文档转换成 excel 格式文件. 开发环境 1.运行环境:python-3.
-
Python 机器学习工具包SKlearn的安装与使用
1.SKlearn 是什么 Sklearn(全称 SciKit-Learn),是基于 Python 语言的机器学习工具包. Sklearn 主要用Python编写,建立在 Numpy.Scipy.Pandas 和 Matplotlib 的基础上,也用 Cython编写了一些核心算法来提高性能. Sklearn 包括六大功能模块: 分类(Classification):识别样本属于哪个类别,常用算法有 SVM(支持向量机).nearest neighbors(最近邻).random forest(
-
运行python提示no module named sklearn的解决方法
在Python中,出现'no module named sklean'的原因是,没有正确安装sklean包.可以使用pip包管理器来安装包,pip包管理器会自动安装包所依赖bai的包而无需额外手动安装,因此十分方便.使用pip包管理器安装包的方法如下: 在命令行中输入:pip install sklean 如果成功安装,会提示"Successfully installed sklean". 其实参考下面的方法 1.安装支持部分: 在terminal里面直接输入以下命令,这个命令会安装s
-
Python sklearn转换器估计器和K-近邻算法
目录 一.转换器和估计器 1. 转换器 2.估计器(sklearn机器学习算法的实现) 3.估计器工作流程 二.K-近邻算法 1.K-近邻算法(KNN) 2. 定义 3. 距离公式 三.电影类型分析 1 问题 2 K-近邻算法数据的特征工程处理 四.K-近邻算法API 1.步骤 2.代码 3.结果及分析 五.K-近邻总结 一.转换器和估计器 1. 转换器 想一下之前做的特征工程的步骤? 1.实例化 (实例化的是一个转换器类(Transformer)) 2.调用fit_transform(对于文档
-
python机器学习基础K近邻算法详解KNN
目录 一.k-近邻算法原理及API 1.k-近邻算法原理 2.k-近邻算法API 3.k-近邻算法特点 二.k-近邻算法案例分析案例信息概述 第一部分:处理数据 1.数据量缩小 2.处理时间 3.进一步处理时间 4.提取并构造时间特征 5.删除无用特征 6.签到数量少于3次的地点,删除 7.提取目标值y 8.数据分割 第二部分:特征工程 标准化 第三部分:进行算法流程 1.算法执行 2.预测结果 3.检验效果 一.k-近邻算法原理及API 1.k-近邻算法原理 如果一个样本在特征空间中的k个最相
-
用python实现k近邻算法的示例代码
K近邻算法(或简称kNN)是易于理解和实现的算法,而且是你解决问题的强大工具. 什么是kNN kNN算法的模型就是整个训练数据集.当需要对一个未知数据实例进行预测时,kNN算法会在训练数据集中搜寻k个最相似实例.对k个最相似实例的属性进行归纳,将其作为对未知实例的预测. 相似性度量依赖于数据类型.对于实数,可以使用欧式距离来计算.其他类型的数据,如分类数据或二进制数据,可以用汉明距离. 对于回归问题,会返回k个最相似实例属性的平均值.对于分类问题,会返回k个最相似实例属性出现最多的属性. kNN
-
python K近邻算法的kd树实现
k近邻算法的介绍 k近邻算法是一种基本的分类和回归方法,这里只实现分类的k近邻算法. k近邻算法的输入为实例的特征向量,对应特征空间的点:输出为实例的类别,可以取多类. k近邻算法不具有显式的学习过程,实际上k近邻算法是利用训练数据集对特征向量空间进行划分.将划分的空间模型作为其分类模型. k近邻算法的三要素 k值的选择:即分类决策时选择k个最近邻实例: 距离度量:即预测实例点和训练实例点间的距离,一般使用L2距离即欧氏距离: 分类决策规则. 下面对三要素进行一下说明: 1.欧氏距离即欧几里得距
-
GO语言利用K近邻算法实现小说鉴黄
Usuage: go run kNN.go --file="data.txt" 关键是向量点的选择和阈值的判定 样本数据来自国家新闻出版总署发布通知公布的<40部淫秽色情网络小说名单> package main import ( "bufio" "flag" "fmt" "io" "log" "math" "os" "pa
-
K最近邻算法(KNN)---sklearn+python实现方式
k-近邻算法概述 简单地说,k近邻算法采用测量不同特征值之间的距离方法进行分类. k-近邻算法 优点:精度高.对异常值不敏感.无数据输入假定. 缺点:计算复杂度高.空间复杂度高. 适用数据范围:数值型和标称型. k-近邻算法(kNN),它的工作原理是:存在一个样本数据集合,也称作训练样本集,并且样本集中每个数据都存在标签,即我们知道样本集中每一数据与所属分类的对应关系.输入没有标签的新数据后,将新数据的每个特征与样本集中数据对应的特征进行比较,然后算法提取样本集中特征最相似数据(最近邻)的分类标
-
K近邻法(KNN)相关知识总结以及如何用python实现
1.基本概念 K近邻法(K-nearest neighbors,KNN)既可以分类,也可以回归. KNN做回归和分类的区别在于最后预测时的决策方式. KNN做分类时,一般用多数表决法 KNN做回归时,一般用平均法. 基本概念如下:对待测实例,在训练数据集中找到与该实例最邻近的K个实例(也就是上面所说的K个邻居), 这K个实例的多数属于某个类,就把该输入实例分类到这个类中 2. KNN算法三要素 KNN算法主要考虑:k值的选取,距离度量方式,分类决策规则. 1) k值的选取.在应用中,k值一般选
-
python实现KNN近邻算法
示例:<电影类型分类> 获取数据来源 电影名称 打斗次数 接吻次数 电影类型 California Man 3 104 Romance He's Not Really into Dudes 8 95 Romance Beautiful Woman 1 81 Romance Kevin Longblade 111 15 Action Roob Slayer 3000 99 2 Action Amped II 88 10 Action Unknown 18 90 unknown 数据显示:肉眼判断
-
Python机器学习之KNN近邻算法
一.KNN概述 简单来说,K-近邻算法采用测量不同特征值之间的距离方法进行分类 优点:精度高.对异常值不敏感.无数据输入假定 缺点:计算复杂度高.空间复杂度高 适用数据范围:数值型和标称2型 工作原理:存在一个样本数据集合,也称为训练样本集,并且样本集中每个数据都存在标签,即我们知道样本集中每一个数据与所属分类的对应关系(训练集).输入没有标签的新数据之后,将新数据的每个特征与样本集中数据对应的特征进行比较,然后算法提取样本集中特征最相似数据(最近邻)的分类标签(测试集).一般来说,我们只选择样
-
python实现K近邻回归,采用等权重和不等权重的方法
如下所示: from sklearn.datasets import load_boston boston = load_boston() from sklearn.cross_validation import train_test_split import numpy as np; X = boston.data y = boston.target X_train, X_test, y_train, y_test = train_test_split(X, y, random_state =