React Diff算法不采用Vue的双端对比原因详解
目录
- 前言
- React 官方的解析
- Fiber 的结构
- Fiber 链表的生成
- React 的 Diff 算法
- 第一轮,常见情况的比对
- 第二轮,不常见的情况的比对
- 重点如何协调更新位置信息
- 小结
- 图文解释 React Diff 算法
- 最简单的 Diff 场景
- 复杂的 Diff 场景
- Vue3 的 Diff 算法
- 第一轮,常见情况的比对
- 第二轮,复杂情况的比对
- Vue2 的 Diff 算法
- 第一轮,简单情况的比对
- 第二轮,不常见的情况的比对
- React、Vue3、Vue2 的 Diff 算法对比
- 相同点
- 不同点
- 为什么 Vue 中不需要使用 Fiber
- 总结
前言
都说“双端对比算法”,那么双端对比算法,到底是怎么样的呢?跟 React 中的 Diff 算法又有什么不同呢?
要了解这些,我们先了解 React 中的 Diff 算法,然后再了解 Vue3 中的 Diff 算法,最后讲一下 Vue2 中的 Diff 算法,才能去比较一下他们的区别。
最后讲一下为什么 Vue 中不需要使用 Fiber 架构。
React 官方的解析
其实为什么 React 不采用 Vue 的双端对比算法,React 官方已经在源码的注释里已经说明了,我们来看一下 React 官方是怎么说的。
function reconcileChildrenArray(
returnFiber: Fiber,
currentFirstChild: Fiber | null,
newChildren: Array<*>,
expirationTime: ExpirationTime,
): Fiber | null {
// This algorithm can't optimize by searching from boths ends since we
// don't have backpointers on fibers. I'm trying to see how far we can get
// with that model. If it ends up not being worth the tradeoffs, we can
// add it later.
// Even with a two ended optimization, we'd want to optimize for the case
// where there are few changes and brute force the comparison instead of
// going for the Map. It'd like to explore hitting that path first in
// forward-only mode and only go for the Map once we notice that we need
// lots of look ahead. This doesn't handle reversal as well as two ended
// search but that's unusual. Besides, for the two ended optimization to
// work on Iterables, we'd need to copy the whole set.
// In this first iteration, we'll just live with hitting the bad case
// (adding everything to a Map) in for every insert/move.
// If you change this code, also update reconcileChildrenIterator() which
// uses the same algorithm.
}
大概的意思就是说:
React 不能通过双端对比进行 Diff 算法优化是因为目前 Fiber 上没有设置反向链表,而且想知道就目前这种方案能持续多久,如果目前这种模式不理想的话,那么也可以增加双端对比算法。
即使是双端对比算法,我们也要对这种情况进行优化,我们应该使用 Map 这种数据结构方案去替代原来那种几乎没有什么变化也进行暴力比较的方案。它第一次搜索循环是通过 forward-only 这种模式(就是只从左向右查找),(第一次循环可能还没有结束,还有节点没有比对的时候)如果还要继续向前循环查找那么就要通过 Map 这种数据类型了。(就目前这个单向链表的数据结构,如果采用)双端对比查找算法比较难控制它反向查找的,但它确实是一种成功的算法。此外,双端对比算法的实现也在我们的工作迭代当中。
第一次迭代,我们就先将就使用这种不好的方案吧,每次新增/移动都要添加所有的数据到一个 Map 的数据类型对象中。
“we'd need to copy the whole set”,这一句,每一个单词都懂,但就是不知道他想说什么,所以就不翻译了,有知道的大神吗?
本人水平有限,错漏难免,如有错漏,恳请各位斧正。
React 的官方虽然解析了,但我们想要彻底理解到底为什么,还是要去详细了解 React 的 Diff 算法是怎么样的。在了解 React Diff 算法之前,我们首先要了解什么是 Fiber,为什么 React 中要使用 Fiber?
Fiber 的结构
在 React15 以前 React 的组件更新创建虚拟 DOM 和 Diff 的过程是不可中断,如果需要更新组件树层级非常深的话,在 Diff 的过程会非常占用浏览器的线程,而我们都知道浏览器执行JavaScript 的线程和渲染真实 DOM 的线程是互斥的,也就是同一时间内,浏览器要么在执行 JavaScript 的代码运算,要么在渲染页面,如果 JavaScript 的代码运行时间过长则会造成页面卡顿。 基于以上原因 React 团队在 React16 之后就改写了整个架构,将原来数组结构的虚拟DOM,改成叫 Fiber 的一种数据结构,基于这种 Fiber 的数据结构可以实现由原来不可中断的更新过程变成异步的可中断的更新。
Fiber 的数据结构主要长成以下的样子,主要通过 Fiber 的一些属性去保存组件相关的信息。
function FiberNode(
tag: WorkTag,
pendingProps: mixed,
key: null | string,
mode: TypeOfMode,
) {
// 作为静态数据结构的属性
this.tag = tag;
this.key = key;
this.elementType = null;
this.type = null;
this.stateNode = null;
// 用于连接其他Fiber节点形成Fiber树
this.return = null;
this.child = null;
this.sibling = null;
this.index = 0;
this.ref = null;
// 作为动态的工作单元的属性
this.pendingProps = pendingProps;
this.memoizedProps = null;
this.updateQueue = null;
this.memoizedState = null;
this.dependencies = null;
this.mode = mode;
this.effectTag = NoEffect;
this.nextEffect = null;
this.firstEffect = null;
this.lastEffect = null;
// 调度优先级相关
this.lanes = NoLanes;
this.childLanes = NoLanes;
// 指向该fiber在另一次更新时对应的fiber
this.alternate = null;
}
Fiber 主要靠以下属性连成一棵树结构的数据的,也就是 Fiber 链表。
// 指向父级Fiber节点 this.return = null; // 指向子Fiber节点 this.child = null; // 指向右边第一个兄弟Fiber节点 this.sibling = null;
举个例子,如下的组件结构:
function App() {
return (
<div>
i am
<span>Coboy</span>
</div>
)
}
对应的 Fiber 链表结构:
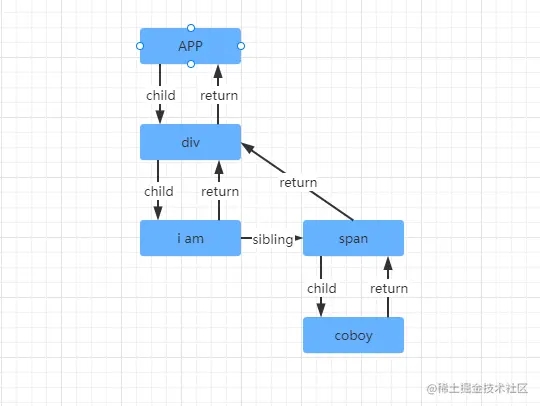
那么以上的 Fiber 链表的数据结构有什么特点,就是任何一个位置的 Fiber 节点,都可以非常容易知道它的父 Fiber, 第一个子元素的 Fiber,和它的兄弟节点 Fiber。却不容易知道它前一个 Fiber 节点是谁,这就是 React 中单向链表 Fiber 节点的特点。也正是因为这些即便在协调的过程被中断了,再恢复协调的时候,依然知道当前的 父节点和孩子节点等信息。
那么 React 是将对应组件怎么生成一个 Fiber 链表数据的呢?
Fiber 链表的生成
上面的组件在经过 JSX 的编译之后,初始化的时候会生成成一个类似于 React 15 或者 Vue 那种虚拟 DOM 的数据结构。然后创建一个叫 fiberRoot 的 Fiber 节点,然后开始从 fiberRoot 这个根 Fiber 开始进行协调,生成一棵 Fiber 树,这个棵树被称为:workInProgress Fiber 树 ,意思是正在工作的 Fiber 树,接下来我们详细了解一下具体是怎么生成一棵 Fiber 树的。要先了解 Fiber 树的生成原理才更好去理解 Fiber 树 diff 的过程。
以下是一段简单版的 Fiber 链表生成的代码片段。 这个协调子节点的函数接收两个参数,returnFiber 是父 Fiber,children 是这个节点的子元素的虚拟 DOM数据。
// 这个协调子节点的函数接收两个参数,returnFiber 是父 Fiber,children 是这个节点的子元素的虚拟 DOM数据。
export function reconcileChildren(returnFiber, children) {
// 如果是字符串或者数字则不创建 Fiber
if(isStringOrNumber(children)) {
return
}
const newChildren = isArray(children) ? children : [children]
// 上一轮的 fiber 节点
let previousNewFiber = null;
// 初次渲染(false)还是更新(true)
let shouldTrackSideEffects = !!returnFiber.alternate
// 老 Fiber 节点
let oldFiber = returnFiber.alternate && returnFiber.alternate.child
let nextOldFiber = null
// 上一次协调返回的位置
let lastPlacedIndex = 0;
// 记录每个 fiber 节点的位置
let newIdx = 0;
// 如果不存在老 Fiber 则是初始化的过程,进行 Fiber 链表的创建
if(!oldFiber) {
for (; newIdx < newChildren.length; newIdx++) {
// 获取节点元素内容
const newChild = newChildren[newIdx]
// 如果节点为 null 则不需要创建 fiber 节点
if(newChild === null) {
continue
}
// 创建新 fiber 的时候记录了关键的父 fiber 等重要信息
const newFiber = createFiber(newChild, returnFiber)
// 记录当前每一个 fiber 的位置
lastPlacedIndex = placeChild(
newFiber,
lastPlacedIndex,
newIdx,
shouldTrackSideEffects // 初次渲染(false)还是更新(true)
)
// 当上一轮的 fiber 节点为 null 的时候,这一轮的 fiber 就是头节点
if(previousNewFiber === null) {
// 父 fiber 的 child 就是第一个节点
returnFiber.child = newFiber
} else {
// 如果不是第一个节点,那么就是兄弟节点
// 上一轮 fiber 的兄弟节点是这一轮的 fiber 节点
previousNewFiber.sibling = newFiber;
}
// 记录上一轮的 fiber,既是这一轮的 fiber 便是下一轮的上一轮 fiber
previousNewFiber = newFiber
}
return
}
}
构建完的 workInProgress Fiber树 会在 commit阶段 渲染到页面。
在组件状态数据发生变更的时候,会根据最新的状态数据先会生成新的虚拟DOM,再去构建一棵新的 workInProgress Fiber 树 ,而在重新协调构建新的 Fiber 树的过程也就是 React Diff 发生的地方。接下来,我们就看看 React Diff 算法是怎么样的。
React 的 Diff 算法
深度优先,有子节点,就遍历子节点,没有子节点,就找兄弟节点,没有兄弟节点,就找叔叔节点,叔叔节点也没有的话,就继续往上找,它爷爷的兄弟,如果一直没找到,就代表所有的更新任务都更新完毕了。
重点是在更新自己的同时需要去协调子节点,也就是传说中进行 Diff 的地方。
进入协调的时候它自己就是父 Fiber,它的子节点在协调之前,是刚刚通过更新的状态数据生成的最新的虚拟DOM数据,是个数组结构的元素数据。
那么要进行更新,就肯定是以为最新的节点数据为准了,又因为最新的节点数据是一个数组,所以可以进行循环对比每一个节点,很明显这个循环是从左向右进行查找比对的。
第一轮,常见情况的比对
那么第一个节点的老 Fiber 怎么拿到呢?可以通过 父 Fiber 的 child 属性拿到,这样第一个节点的老 Fiber 就拿到了,那么第二节点的老 Fiber,很明显可以通过第一个节点的老 Fiber 节点的 sibling 属性拿到,后面的以此类推。
怎么比对呢?
在循环的新节点虚拟DOM数据的时候,拿到新节点虚拟DOM信息,然后就去和老 Fiber 节点进行比对,如果两个节点相同则创建一个新的 Fiber 节点并复用一些老 Fiber 节点的信息,比如真实 DOM,并给这个新的 Fiber 节点打上一个 Update 的标记,代表这个节点需要更新即可。
接着去更新协调位置信息。
在循环的最后进行 Fiber 链表的处理:
如果是头节点,则把新 Fiber 设置为父 Fiber 的 child 属性的值; 如果不是头节点,则把新 Fiber 设置为上一轮循环的创建的 Fiber 节点的 sibing 属性的值; 更新上一轮 Fiber 变量的值,就是把这一轮的 Fiber 设置成下一轮的 Fiber; 更新比对的老 Fiber 的值。
如果新节点都能找到能复用的节点,则判断是否还存在老节点,有则删除。
第二轮,不常见的情况的比对
如果经过第一轮比对,新节点还存在未比对的,则继续循环查找。
先将剩下未比对的老 Fiber 节点全部处理成一个 老 Fiber 的 key 或老 Fiber 的 index 为 key,Fiber 节点为 value 的 Map 中,这样就可以,以 O(1) 复杂度,通过新 Fiber 的 key 去 Map 对象中查找匹配的 Fiber,找到了,则删除 Map 对象中的老 Fiber 数据,然后复用匹配到的 Fiber 数据。
接下来,不管有没有匹配到都进行位置协调,记录最新的位置信息,新增的 Fiber 因为没有存在老 Fiber 而会被打上 Placement 的标记,在将来提交的阶段将会被进行新增操作。这个过程跟第一轮最后的处理是一样的。
在循环的最后进行 Fiber 链表的处理:
如果是头节点,则把新 Fiber 设置为父 Fiber 的 child 属性的值; 如果不是头节点,则把新 Fiber 设置为上一轮循环的创建的 Fiber 节点的 sibing 属性的值; 更新上一轮 Fiber 变量的值,就是把这一轮的 Fiber 设置成下一轮的 Fiber; 更新比对的老 Fiber 的值。
重点如何协调更新位置信息
如果是初始渲染,那么协调位置就只是记录当前元素下标的位置到 Fiber 节点上。如果是更新阶段,就先判断有没有老 Fiber 节点,如果没有老 Fiber 节点,则说明该节点需要创建,就给当前新的 Fiber 节点打上一个 Placement 的标记,如果有老 Fiber 节点,则判断老 Fiber 节点的位置是否比上一次协调的返回的位置小,如果是,则说明该节点需要移动,给新 Fiber 节点打上一个 Placement 的标记,并继续返回上一次协调返回的位置;如果老 Fiber 节点的位置大或者等于上一次协调返回的位置,则说明该节点不需要进行位置移动操作,就返回老 Fiber 的位置即可。
这里需要说明的一点,为什么移动和新增节点都是 Placement 的标记呢?
因为我们是在协调一个子节点列表,所以不管是新增还是移动都是属于位置是需要发生变化的,所以新增和移动都是同一种操作情况。
小结
总个来说,React Diff 算法分以下几个步骤:
- 第一轮,从左向右新老节点进行比对查找能复用的旧节点,如果有新老节点比对不成功的,则停止这一轮的比对,并记录了停止的位置。
- 如果第一轮比对,能把所有的新节点都比对完毕,则删除旧节点还没进行比对的节点。
- 如果第一轮的比对,没能将所有的新节点都比对完毕,则继续从第一轮比对停止的位置继续开始循环新节点,拿每一个新节点去老节点里面进行查找,有匹配成功的则复用,没匹配成功的则在协调位置的时候打上 Placement 的标记。
- 在所有新节点比对完毕之后,检查还有没有没进行复用的旧节点,如果有,则全部删除。
图文解释 React Diff 算法
接下来我们使用图文进行 React Diff 算法讲解,希望可以更进一步了解 React 的 Diff 算法。
最简单的 Diff 场景
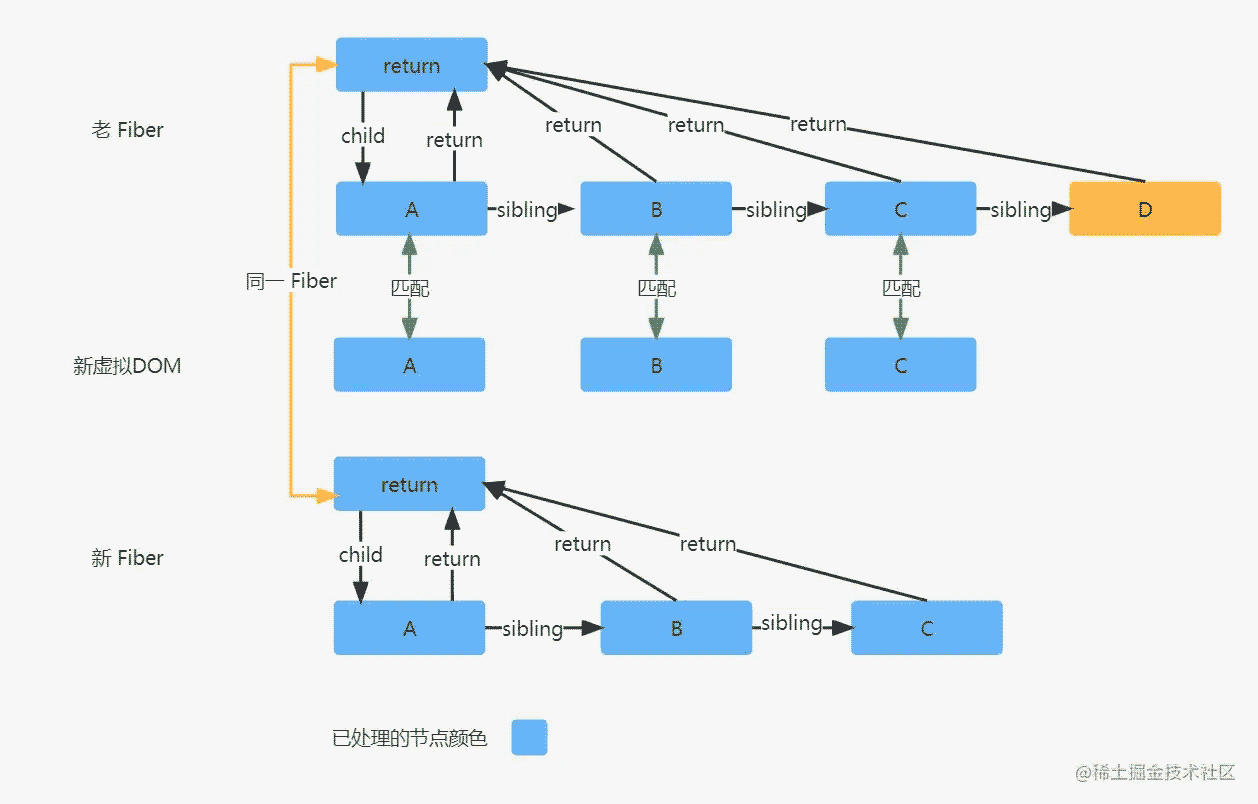
上图的 Diff 场景是最简单的一种,新虚拟DOM 从左到右都能和老 Fiber 的节点一一匹配成功,协调位置的时候,老 Fiber A 的位置是 0,默认上一次协调返回的位置也是 0,根据协调位置规则,老 Fiber 的位置不比上一次协调返回的位置小,则只需要返回老 Fiber A 的位置 0 即可;
到了 B 进行协调位置的时候,老 Fiber B 位置 1 不比上一次协调返回的位置 0 小,则只需返回老 Fiber B 的位置 1 即可;到了 C 进行协调位置的时候,老 Fiber C 位置 2 不比上一次协调返回的位置 1 小,则只需要返回老 Fiber C 的位置 2 即可;
最后全部的新虚拟DOM 比对完毕,但老 Fiber 上还存在节点信息,则需要将剩下的老 Fiber 进行删除标记。
接下来我们看看复杂的 Diff 场景。
复杂的 Diff 场景
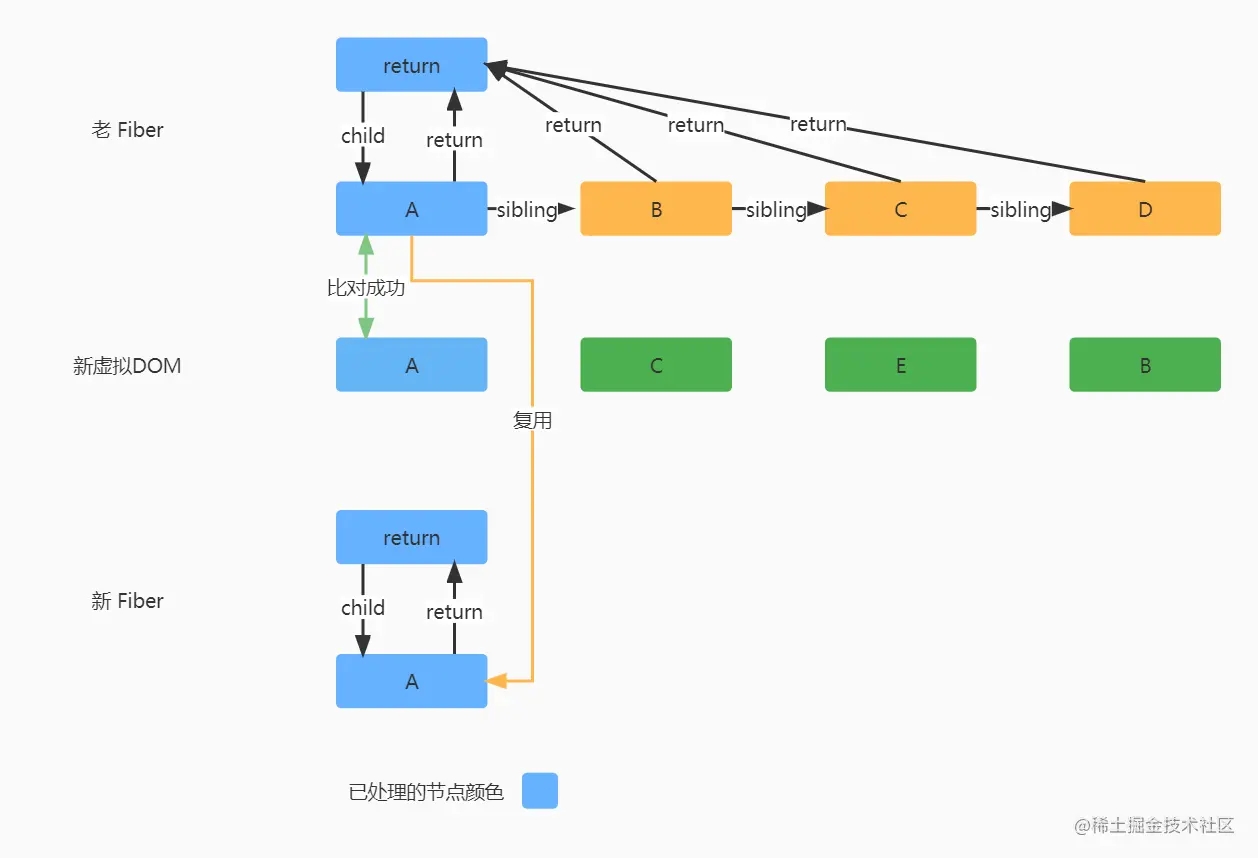
在上图中,第一轮循环比对的时候,新虚拟节点A 和第一个老 Fiber 节点是可以匹配的,所以就可以复用老 Fiber 的节点信息了,并且在协调的位置信息的时候,是存在老 Fiber 的,那么就去比较老 Fiber 的位置和上一次协调返回的位置进行比较(上一次协调返回的位置默认为 0),老 Fiber 的位置是等于新 Fiber 的位置,根据协调规则,位置不需要移动,返回老 Fiber 的位置信息即可,很明显这次返回的协调位置是 0。
到了第二个新虚拟节点 C 的时候,C 和老 Fiber 中的 B 是不匹配的,则第一轮比对结束。
第一轮比对结束之后,新虚拟DOM是还存在未比对的节点的,那么继续开始第二轮的比对。
在第二轮比对开始之前,会先将剩下未比对的老 Fiber 节点全部处理成一个 老 Fiber 的 key 或老 Fiber 的 index 为 key,Fiber 节点为 value 的 Map 中。
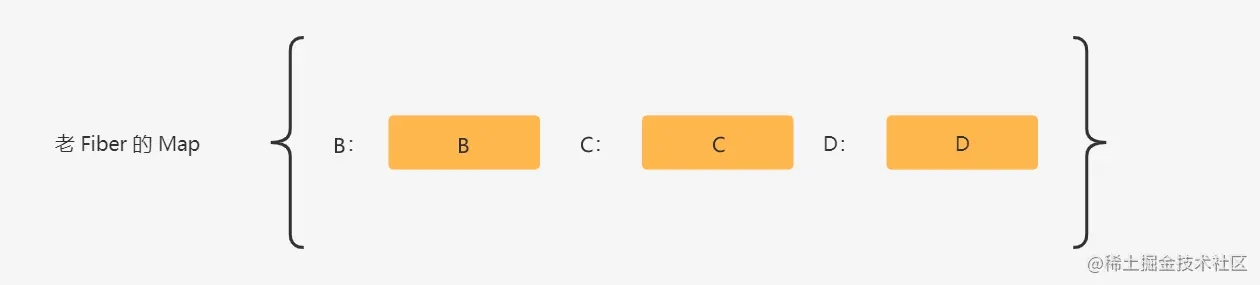
然后进行第二轮的比对。
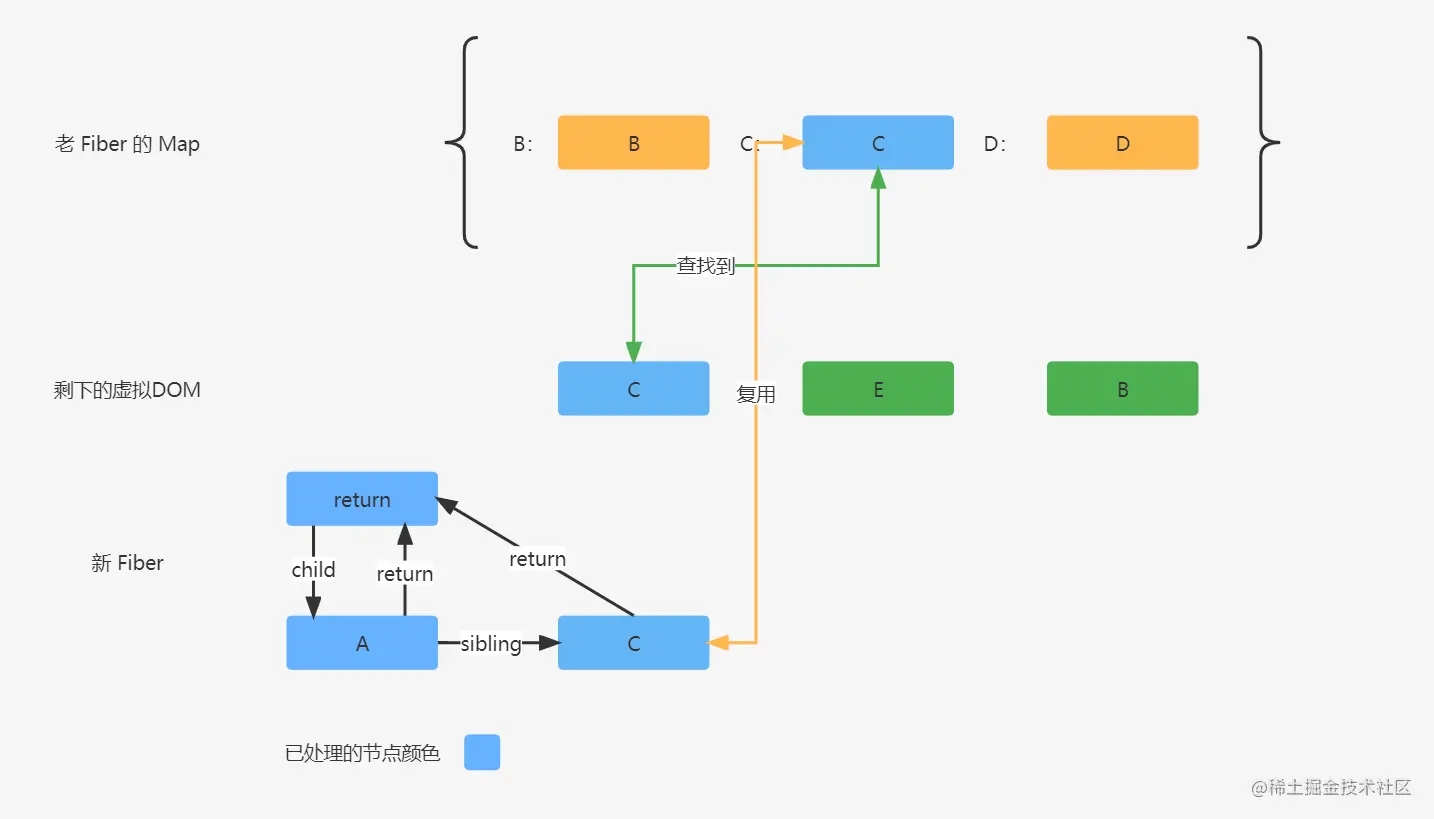
虚拟DOM C 可以通过 C 的 key 值在老 Fiber 的 Map 中找到老 Fiber C 节点,这个时候会 C 进行暂存,然后把 Map 中的 C 进行删除,再进行老 Fiber 的节点信息复用,然后去协调比对位置信息。
老 Fiber C 的位置是 2,然后上一次新 Fiber A 协调比对返回的位置信息是 0,那么这一次协调的位置是老 Fiber 的位置比上一次协调返回的位置大,那么这次协调是不用标记 Placement 标记的,直接返回老 Fiber C 的位置 2。
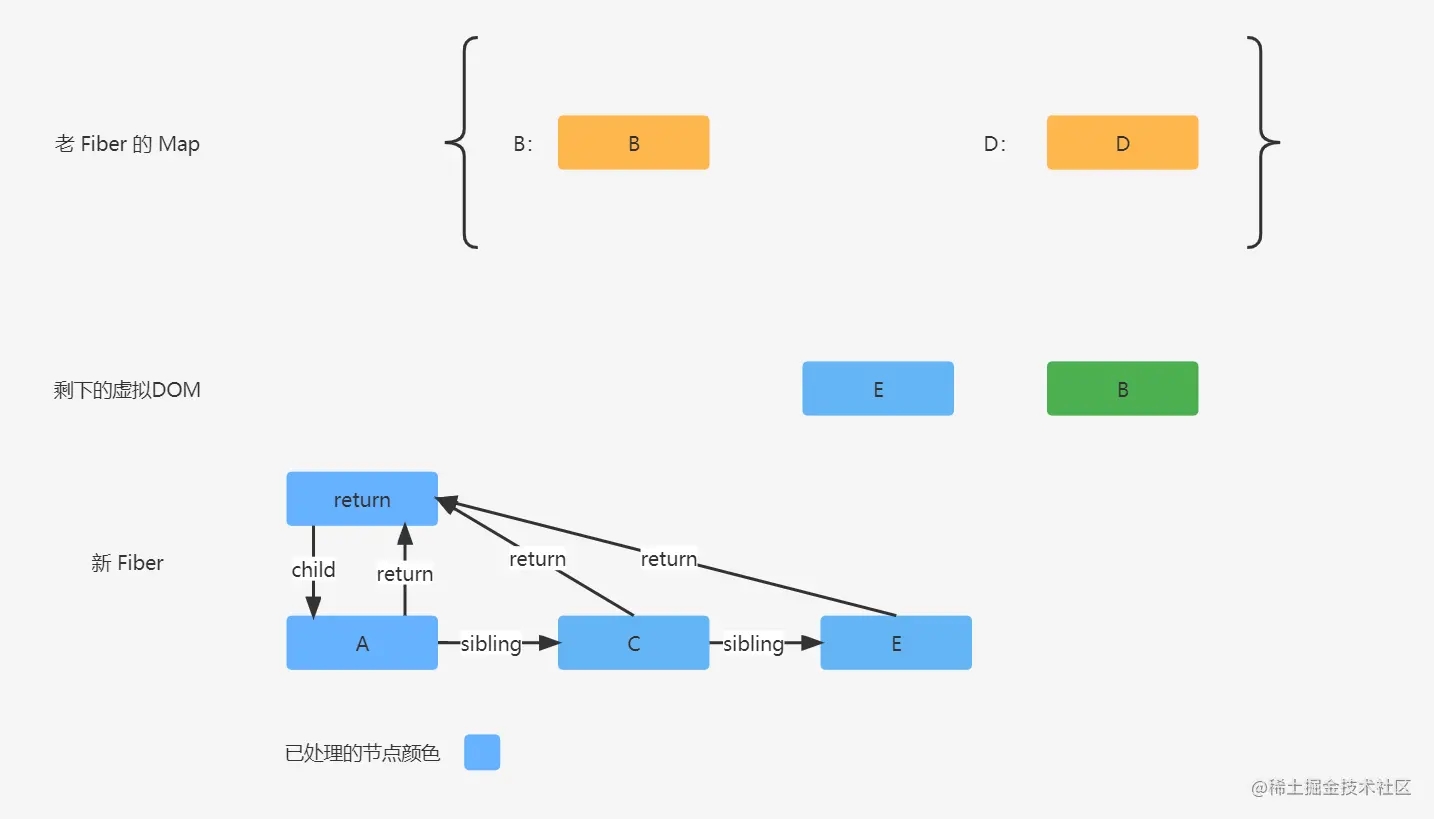
虚拟DOM E,在老 Fiber 的 Map 中是没有匹配成功的,所以在创建 Fiber E 的时候,是没有进行老 Fiber 的复用的,去协调比对位置的时候,根据协调位置规则,没有老 Fiber,就标记 Placement 并返回上一次协调返回的位置,那么上一次 C 协调位置返回的位置信息是 2,这一次 E 协调位置依然返回 2。

虚拟DOM B 也在 Fiber 的 Map 中匹配成功了,那么匹配成功之后,就对老 Fiber B 进行暂存,然后删除老 Fiber B,再进行信息复用,然后又进行位置协调,老 Fiber B 的位置是 1,上一次协调返回的位置是 2,根据协调位置规则,老 Fiber 的位置小于上一次协调返回的位置,则标记 Placement 并返回上一次协调返回的位置 2。

最后,老 Fiber 的 Map 中还存在一个 D 节点没处理,则需要对其进行删除标记操作。
最终新 Fiber 将被协调成下面的样子:

那么根据图片,我们又可以得出一个结论,匹配到的老 Fiber 如果和新 Fiber 相同或者在新 Fiber 位置的右边则不需要进行移动标记。
Vue3 的 Diff 算法
在我看来 Vue3 的 Diff 算法是 Vue2、Vue3、React 的 Diff 算法中最复杂的一种。 下面我们来简单说一下 Vue3 的 Diff 算法,只说数组和数组比对的情况。
第一轮,常见情况的比对
首先从左往右进行比对,如果是相同的就进行更新比对,如果不相同则停止比对,并且记录停止的下标。 再从右往左进行比对,如果是相同的就进行更新比对,如果不相同也停止比对,也进行记录停止的下标。 通过这样左右进行比对,最后就可以把真正复杂部分进行范围锁定了。 左右比对完之后,如果新节点已经比对完了,老节点列表还存在节点未比对,则删除老节点列表上的未比对的节点,如果老节点已经比对完了,新节点列表还存在未比对的节点则进行创建。
第二轮,复杂情况的比对
如果新节点未比对完,老节点也未比对完,则进行最后最复杂的处理。
先把剩下的新节点处理成节点的 key 为 key, 节点下标为 value 的 Map; 接着初始化一个长度为剩下未比对的新节点的长度的数组 newIndexToOldIndexMap,初始化每个数组的下标的默认值为 0。 再循环剩下的旧节点,通过旧节点的 key 去刚刚创建的 Map 中查找,看看旧节点有没有在新节点中,如果旧节点没有 key 则需要通过循环剩下的新节点进行查找。 如果旧节点在新节点中没找到,则说明该旧节点需要进行删除。 如果找到了,则把找到的新节点的下标对应存储到上述的数组 newIndexToOldIndexMap 中,然后更新比对匹配到的新老节点。
把所有的旧节点比对完成后,就会得到一个刚刚收集的新节点的下标数组,然后对这个新节点的下标数组进行进行最长递增子序列查找得到一个最长递增子序列的下标数据。 然后再进行循环左右对比完之后剩余新节点的下标,然后判断循环的下标是否被上述的数组 newIndexToOldIndexMap 进行收集了,如果没被收集到则说明这个新节点需要进行创建,如果已经被收集了则判断该循环的下标是否在上面计算得到的最长递增子序列中,如果不在则需要对该循环节点进行移动操作。
以上就是 Vue3 Diff 算法大概过程了。
更加详细的 Vue3 Diff 算法解析可以查看我这篇文章:vue3中的diff算法
Vue2 的 Diff 算法
Vue2 的 Diff 算法就是以新的虚拟DOM为准进行与老虚拟DOM的比对,继而进行各种情况的处理。大概可以分为 4 种情况:更新节点、新增节点、删除节点、移动节点位置。比对新老两个虚拟DOM,就是通过循环,每循环到一个新节点,就去老节点列表里面找到和当前新节点相同的旧节点。如果在旧节点列表中找不到,说明当前节点是需要新增的节点,我们就需要进行创建节点并插入视图的操作;如果找到了,就做更新操作;如果找到的旧节点与新节点位置不同,则需要移动节点等。
第一轮,简单情况的比对
其中为了快速查找到节点,Vue2 的 Diff 算法设置了 4 种优化策略,分别是:
- 老数组的开始与新数组的开始
- 老数组的结尾与新数组的结尾
- 老数组的开始与新数组的结尾
- 老数组的结尾与新数组的开始
通过这 4 种快捷的查找方式,我们就不需要循环来查找了,只有当以上 4 种方式都查找不到的时候,再进行循环查找。
第二轮,不常见的情况的比对
最后循环结束后需要对未处理的节点进行处理。
如果是老节点列表先循环完毕,这个时候如果新节点列表还有剩余的节点,则说明这些节点都是需要新增的节点,直接把这些节点创建并插入到 DOM 中就行了。
如果是新节点列表先循环完毕,这个时候如果老节点列表还有剩余节点,则说明这些节点都是要被废弃的节点,是应该被删除的节点,直接批量删除就可以了。
更加详细的 Vue2 diff 算法可以查看我这篇文章:Vue2 的 diff 算法详解
React、Vue3、Vue2 的 Diff 算法对比
相同点
只有使用了虚拟DOM的这些框架,在进行更新 Diff 对比的时候,都是优先处理简单的场景,再处理复杂的场景。
React 中是先处理左边部分,左边部分处理不了,再进行复杂部分的处理;Vue2 则先进行首尾、首首、尾尾部分的处理,然后再进行中间复杂部分的处理;Vue3 则先处理首尾部分,然后再处理中间复杂部分,Vue2 和 Vue3 最大的区别就是在处理中间复杂部分使用了最长递增子序列算法找出稳定序列的部分。
在处理老节点部分,都需要把节点处理 key - value 的 Map 数据结构,方便在往后的比对中可以快速通过节点的 key 取到对应的节点。同样在比对两个新老节点是否相同时,key 是否相同也是非常重要的判断标准。所以不同是 React, 还是 Vue,在写动态列表的时候,都需要设置一个唯一值 key,这样在 diff 算法处理的时候性能才最大化。
在移动或者创建节点的时候都使用了 insertBefore(newnode,existingnode) 这个 API:
- newnode 必需。需要插入的节点对象。
- existingnode 可选。在其之前插入新节点的子节点。如果未规定,则 insertBefore 方法会在结尾插入 newnode。
不同点
对静态节点的处理不一样。
由于 Vue 是通过 template 模版进行编译的,所以在编译的时候可以很好对静态节点进行分析然后进行打补丁标记,然后在 Diff 的时候,Vue2 是判断如果是静态节点则跳过过循环对比,而 Vue3 则是把整个静态节点进行提升处理,Diff 的时候是不过进入循环的,所以 Vue3 比 Vue2 的 Diff 性能更高效。而 React 因为是通过 JSX 进行编译的,是无法进行静态节点分析的,所以 React 在对静态节点处理这一块是要逊色的。
Vue2 和 Vue3 的比对和更新是同步进行的,这个跟 React15 是相同的,就是在比对的过程中,如果发现了那些节点需要移动或者更新或删除,是立即执行的,也就是 React 中常讲的不可中断的更新,如果比对量过大的话,就会造成卡顿,所以 React16 起就更改为了比对和更新是异步进行的,所以 React16 以后的 Diff 是可以中断,Diff 和任务调度都是在内存中进行的,所以即便中断了,用户也不会知道。
另外 Vue2 和 Vue3 都使用了双端对比算法,而 React 的 Fiber 由于是单向链表的结构,所以在 React 不设置由右向左的链表之前,都无法实现双端对比。那么双端对比目前 React 的 Diff 算法要好吗?接下来我们来看看一个例子,看看它分别在 React、Vue2、Vue3 中的是怎么处理的。
比如说我们现在有以下两组新老节点:
老:A, B, C, D
新:D, A, B, C
那么我们可以看到,新老两组节点唯一的不同点就是,D 节点在新的节点中跑到开头去了,像这种情况:
React 是从左向右进行比对的,在上述这种情况,React 需要把 A, B, C 三个节点分别移动到 D 节点的后面。
Vue2 在进行老节点的结尾与新节点的开始比对的时候,就发现这两个节点是相同的,所以直接把老节点结尾的 D 移动到新节点开头就行了,剩下的就只进行老节点的开始与新节点的开始进行比对,就可以发现它们的位置并没有发生变化,不需要进行移动。
Vue3 是没有了 Vue2 的新老首尾节点进行比较,只是从两组节点的开头和结尾进行比较,然后往中间靠拢,那么 Vue3 在进行新老节点的开始和结尾比对的时候,都没有比对成功,接下来就进行中间部分的比较,先把老节点处理成 key - value 的 Map 数据结构,然后又使用最长递增子序列算法找出其中的稳定序列部分,也就是:A, B, C,然再对新节点进行循环比对,然后就会发现新节点的 A, B, C 都在稳定序列部分,不需要进行移动,然就只对 D,进行移动即可。
最后上述的例子在 Vue2 和 Vue3 中都只需要移动一个节点就可以完成 Diff 算法比对,而 React 在这种极端例子中则没办法进行很好的优化,需要进行多次节点移动操作。
为什么 Vue 中不需要使用 Fiber
其实这个问题也可以叫做:为什么 Vue 不需要时间分片?对于这个问题其实尤雨溪也在英文社区里回答过,也有前端大牛翻译发布在公众号上,那么下面我也进行一下总结。
第一,首先时间分片是为了解决 CPU 进行大量计算的问题,因为 React 本身架构的问题,在默认的情况下更新会进行过多的计算,就算使用 React 提供的性能优化 API,进行设置,也会因为开发者本身的问题,依然可能存在过多计算的问题。
第二,而 Vue 通过响应式依赖跟踪,在默认的情况下可以做到只进行组件树级别的更新计算,而默认下 React 是做不到的(据说 React 已经在进行这方面的优化工作了),再者 Vue 是通过 template 进行编译的,可以在编译的时候进行非常好的性能优化,比如对静态节点进行静态节点提升的优化处理,而通过 JSX 进行编译的 React 是做不到的。
第三,React 为了解决更新的时候进行过多计算的问题引入了时间分片,但同时又带来了额外的计算开销,就是任务协调的计算,虽然 React 也使用最小堆等的算法进行优化,但相对 Vue 还是多了额外的性能开销,因为 Vue 没有时间分片,所以没有这方面的性能担忧。
第四,根据研究表明,人类的肉眼对 100 毫秒以内的时间并不敏感,所以时间分片只对于处理超过 100 毫秒以上的计算才有很好的收益,而 Vue 的更新计算是很少出现 100 毫秒以上的计算的,所以 Vue 引入时间分片的收益并不划算。
总结
我们先由 “ React 的 Diff 算法为什么不采用 Vue 的双端对比的 Diff 算法?” 这个问题引出对 React 中的一些知识点的学习理解,比如什么是 Fiber,Fiber 链表是如何生成的,然后详细解析了 React Diff 算法,还对 React Diff 算法进行图文并茂解析,让我们可以更加理解 React 的 Diff 算法。 其后,我们又简单介绍了 Vue3 和 Vue2 的 Diff 算法,之后对 React、Vue3、Vue2之间的算法的异同进行了讲解。 最后我们又总结了一下尤雨溪对 “为什么 Vue 不需要时间分片?” 这个问题的解析。
以上就是React Diff算法不采用Vue双端对比算法原因详解的详细内容,更多关于React Diff算法不采用Vue双端对比的资料请关注我们其它相关文章!
相关推荐
-

详解react应用中的DOM DIFF算法
前言 对我们搞前端的来说,目前最流行的两大前端框架毫无疑问当属React和Vue,对于这两大框架,想必大家也是再熟悉不过了.然而,这两大框架无一例外的全部放弃使用传统的DOM技术,却采用了以JS为基础的Virtual DOM技术,也可称作虚拟DOM.所以,到底什么是Virtual DOM?两大热门框架全部使用Virtual DOM的原因又是什么?接下来让我这个搞前端的人来好好地为您讲解一下DOM DIFF算法的牛逼之处. 什么是Virtual DOM? 如字面意思所说,Virtual DOM即
-
React Diff原理深入分析
在了解Diff前,先看下React的虚拟DOM的结构 这是html结构 <div id="father"> <p class="child">I am child p</p> <div class="child">I am child div</div> </div> 这是React渲染html时的js代码 自己可以在babel上试试 React.createElemen
-
react diff 算法实现思路及原理解析
目录 事例分析 diff 特点 diff 思路 实现 diff 算法 修改入口文件 实现 React.Fragment 我们需要修改 children 对比 前面几节我们学习了解了 react 的渲染机制和生命周期,本节我们正式进入基本面试必考的核心地带 -- diff 算法,了解如何优化和复用 dom 操作的,还有我们常见的 key 的作用. diff 算法使用在子都是数组的情况下,这点和 vue 是一样的.如果元素是其他类型的话直接替换就好. 事例分析 按照之前的 diff 写法,如果元素不
-
react中的虚拟dom和diff算法详解
虚拟DOM的作用 首先我们要知道虚拟dom的出现是为了解决什么问题的,他解决我们平时频繁的直接操作DOM效率低下的问题.那么为什么我们直接操作DOM效率会低下呢? 比如我们创建一个div,我们可以在控制台查看一下这个div上自带或者继承了很多属性,尤其是我们使用js操作DOM的时候,我们的DOM本身就很复杂,js的操作也会占用很多时间,但是我们控制不了DOM元素本身,因此虚拟DOM解决的是js操作DOM这一层面,其实解决的是减少了操作dom的次数 简单实现虚拟DOM 虚拟DOM,见名知意,就是假
-
react diff算法源码解析
React中Diff算法又称为调和算法,对应函数名为reconcileChildren,它的主要作用是标记更新过程中那些元素发生了变化,这些变化包括新增.移动.删除.过程发生在beginWork阶段,只有非初次渲染才会Diff. 以前看过一些文章将Diff算法表述为两颗Fiber树的比较,这是不正确的,实际的Diff过程是一组现有的Fiber节点和新的由JSX生成的ReactElement的比较,然后生成新的Fiber节点的过程,这个过程中也会尝试复用现有Fiber节点. 节点Diff又分为两种
-
深入浅析React中diff算法
React中diff算法的理解 diff算法用来计算出Virtual DOM中改变的部分,然后针对该部分进行DOM操作,而不用重新渲染整个页面,渲染整个DOM结构的过程中开销是很大的,需要浏览器对DOM结构进行重绘与回流,而diff算法能够使得操作过程中只更新修改的那部分DOM结构而不更新整个DOM,这样能够最小化操作DOM结构,能够最大程度上减少浏览器重绘与回流的规模. 虚拟DOM diff算法的基础是Virtual DOM,Virtual DOM是一棵以JavaScript对象作为基础的树,
-
React Diff算法不采用Vue的双端对比原因详解
目录 前言 React 官方的解析 Fiber 的结构 Fiber 链表的生成 React 的 Diff 算法 第一轮,常见情况的比对 第二轮,不常见的情况的比对 重点如何协调更新位置信息 小结 图文解释 React Diff 算法 最简单的 Diff 场景 复杂的 Diff 场景 Vue3 的 Diff 算法 第一轮,常见情况的比对 第二轮,复杂情况的比对 Vue2 的 Diff 算法 第一轮,简单情况的比对 第二轮,不常见的情况的比对 React.Vue3.Vue2 的 Diff 算法对比
-
一文详解Vue 的双端 diff 算法
目录 前言 diff 算法 简单 diff 双端 diff 总结 前言 Vue 和 React 都是基于 vdom 的前端框架,组件渲染会返回 vdom,渲染器再把 vdom 通过增删改的 api 同步到 dom. 当再次渲染时,会产生新的 vdom,渲染器会对比两棵 vdom 树,对有差异的部分通过增删改的 api 更新到 dom. 这里对比两棵 vdom 树,找到有差异的部分的算法,就叫做 diff 算法. diff 算法 我们知道,两棵树做 diff,复杂度是 O(n^3) 的,因为每个节
-
React diff算法原理详细分析
目录 抛砖引玉 传统diff算法 React diff原理 tree diff component diff element diff 应用实践 页面指定区域刷新 更加方便地监听props改变 react-router中Link问题 结语 抛砖引玉 React通过引入Virtual DOM的概念,极大地避免无效的Dom操作,已使我们的页面的构建效率提到了极大的提升.但是如何高效地通过对比新旧Virtual DOM来找出真正的Dom变化之处同样也决定着页面的性能,React用其特殊的diff算法解
-
vue.js+boostrap项目实践(案例详解)
一.为什么要写这篇文章 最近忙里偷闲学了一下vue.js,同时也复习了一下boostrap,发现这两种东西如果同时运用到一起,可以发挥很强大的作用,boostrap优雅的样式和丰富的组件使得页面开发变得更美观和更容易,同时vue.js又是可以绑定model和view(这个相当于MVC中的,M和V之间的关系),使得对数据变换的操作变得更加的简易,简化了很多的逻辑代码. 二.学习这篇文章需要具备的知识 1.需要有vue.js的知识 2.需要有一定的HTML.CSS.JavaScript的基础知识 3
-
再谈PHP中单双引号的区别详解
在PHP中,字符串的定义可以使用英文单引号' ',也可以使用英文双引号" ". 但是必须使用同一种单或双引号来定义字符串,如:'Hello World"和"Hello World'为非法的字符串定义. 单引号和双引号到底有啥区别呢?下面通过本文学习一下吧. 1.定义字符串 在PHP中,字符串的定义可以使用单引号,也可以使用双引号.但是必须使用同一种单或双引号来定义字符串,如:'Hello"和"Hello'为非法的字符串定义. 定义字符串时,只有一
-
vue组件三大核心概念图文详解
前言 本文主要介绍属性.事件和插槽这三个vue基础概念.使用方法及其容易被忽略的一些重要细节.如果你阅读别人写的组件,也可以从这三个部分展开,它们可以帮助你快速了解一个组件的所有功能. 本文的代码请猛戳 github博客 ,纸上得来终觉浅,大家动手多敲敲代码! 一.属性 1.自定义属性props prop 定义了这个组件有哪些可配置的属性,组件的核心功能也都是它来确定的.写通用组件时,props 最好用对象的写法,这样可以针对每个属性设置类型.默认值或自定义校验属性的值,这点在组件开发中很重要,
-
vue实现2048小游戏功能思路详解
试玩地址 项目地址 使用方法: git clone npm i npm run dev 实现思路如下: 用vue-cli搭建项目,对这个项目可能有点笨重,但是也懒的再搭一个 4X4的方格用一个二维数组存放,绑定好后只关心这个二维数组,其他事交给vue 监听键盘事件 2048的核心部分就是移动合并的算法,因为是一个4X4的矩阵,所以只要实现左移的算法,其他方向的移动只需要将矩阵旋转,移动合并,再旋转回来,渲染dom即可 绑定不同数值的样式 分值计算,以及用localstorage存放最高分 关键实
-
八个Vue中常用的v指令详解
目录 Vue中常用的8种v指令 1 v-text 指令 2 v-html 指令 3 v-on 指令 案例:计数器 4 v-show 指令 5 v-if 指令 6 v-bind 指令 7 v-for 指令 8 v-on 补充 总结 Vue中常用的8种v指令 根据官网的介绍,指令 是带有 v- 前缀的特殊属性.通过指令来操作DOM元素 指令 功能 v-text=“变量/表达式” 文本的设置字符串变量+数字可以直接写是拼接字符串如果出现要使用外部不相同的引号 v-html=“变量” 文本或者页面的设置