python中apply函数详情
函数原型:
DataFrame.apply(func, axis=0, broadcast=False, raw=False, reduce=None, args=(), **kwds)
- 1.该函数最有用的是第一个参数,这个参数是函数,相当于C/C++的函数指针。
- 2.这个函数需要自己实现,函数的传入参数根据axis来定,比如axis = 1,就会把一行数据作为Series的数据
- 结构传入给自己实现的函数中,我们在函数中实现对
Series不同属性之间的计算,返回一个结果,则apply函数 - 会自动遍历每一行
DataFrame的数据,最后将所有结果组合成一个Series数据结构 - 并返回。
- 3.apply函数常与
groupby函数一起使用,如下图所示:
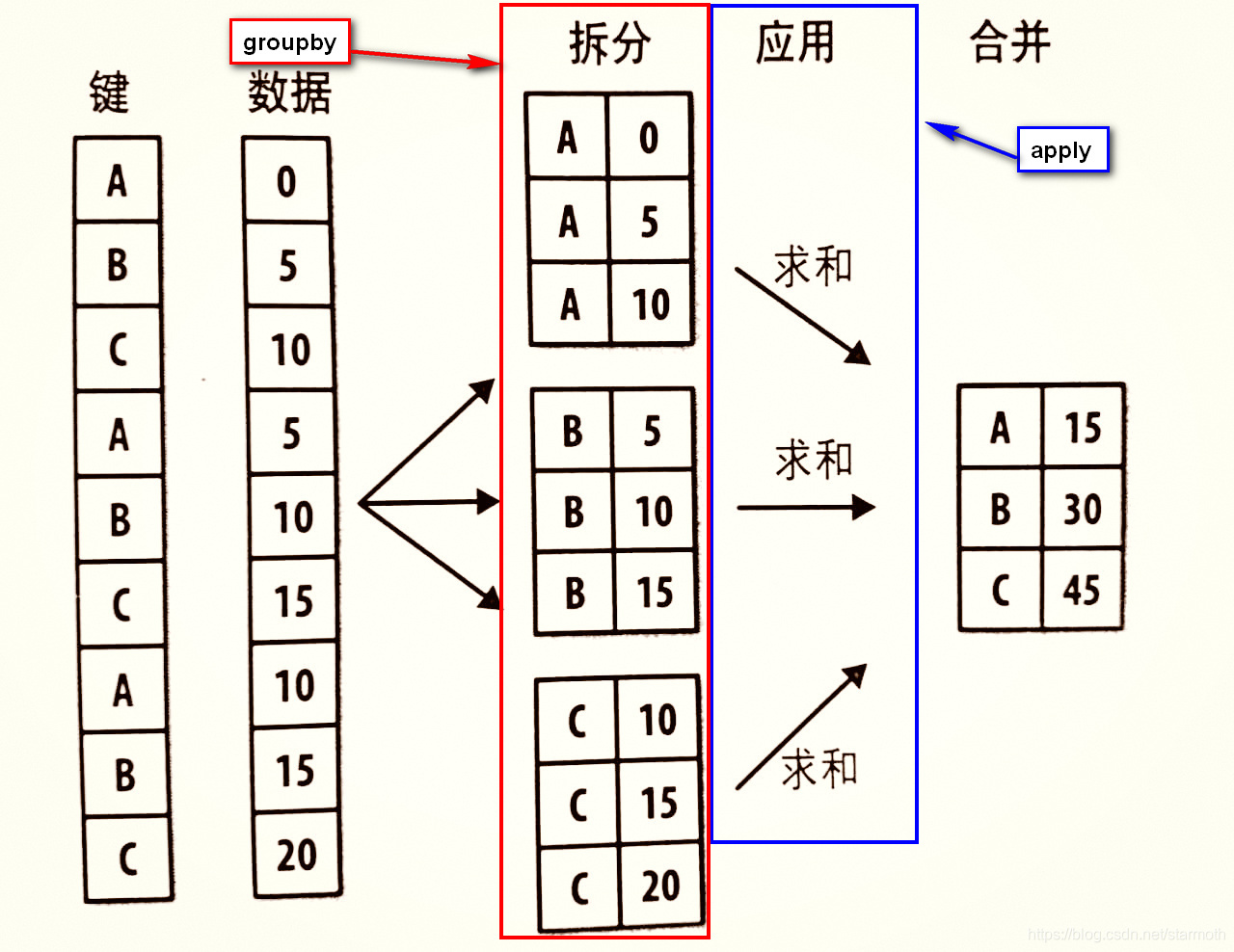
- 4.举栗子
对指定列进行操作:
data=np.arange(0,16).reshape(4,4) data=pd.DataFrame(data,columns=['0','1','2','3']) def f(x): return x-1 print(data) print(data.ix[:,['1','2']].apply(f)) 0 1 2 3 0 0 1 2 3 1 4 5 6 7 2 8 9 10 11 3 12 13 14 15 1 2 0 0 1 1 4 5 2 8 9 3 12 13
对行操作:
data=np.arange(0,16).reshape(4,4) data=pd.DataFrame(data,columns=['0','1','2','3']) def f(x): return x-1 print(data) print(data.ix[[0,1],:].apply(f)) 0 1 2 3 0 0 1 2 3 1 4 5 6 7 2 8 9 10 11 3 12 13 14 15 0 1 2 3 0 -1 0 1 2 1 3 4 5 6
整体对列操作:
data=np.arange(0,16).reshape(4,4) data=pd.DataFrame(data,columns=['0','1','2','3']) def f(x): return x.max() print(data) print(data.apply(f)) 0 1 2 3 0 0 1 2 3 1 4 5 6 7 2 8 9 10 11 3 12 13 14 15 0 12 1 13 2 14 3 15 dtype: int64
整体对行操作:
data=np.arange(0,16).reshape(4,4) data=pd.DataFrame(data,columns=['0','1','2','3']) def f(x): return x.max() print(data) print(data.apply(f,axis=1)) 0 1 2 3 0 0 1 2 3 1 4 5 6 7 2 8 9 10 11 3 12 13 14 15 0 3 1 7 2 11 3 15 dtype: int64
到此这篇关于python中apply函数详情的文章就介绍到这了,更多相关python中apply函数内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python 实现rolling和apply函数的向下取值操作
我就废话不多说了,大家还是直接看代码吧! import pandas as pd def get_under_rolling(df,window,user,name): df[name] = df[user].iloc[::-1].rolling(window=window).apply(lambda x:x[0]).iloc[::-1] return df if __name__ == '__main__': df = pd.DataFrame({'a':[1,2,3,4,5], 'b':[2
-
Python函数中apply、map、applymap的区别
目录 一.总结 二.实操对比 一.总结 apply -- 应用在 dataFrame 上,用于对 row 或者 column 进行计算 applymap -- 应用在 dataFrame 上,元素级别的操作 map -- python 系统自带函数,应用在 series 上, 元素级别的操作 二.实操对比 构建测试数据框: import pandas as pd import numpy as np df = pd.DataFrame(np.random.randint(0, 10, (4, 3
-
python通过apply使用元祖和列表调用函数实例
本文实例讲述了python通过apply使用元祖和列表调用函数的方法.分享给大家供大家参考.具体实现方法如下: def my_fuc(a, b): print a, b atuple=(30,10) alist= ['Hello','World!'] apply(my_fuc,atuple) apply(my_fuc,alist) 运行结果如下: 30 10 Hello World! 希望本文所述对大家的Python程序设计有所帮助.
-
Python中apply函数的用法实例教程
一.概述: python apply函数的具体含义如下: apply(func [, args [, kwargs ]]) 函数用于当函数参数已经存在于一个元组或字典中时,间接地调用函数.args是一个包含将要提供给函数的按位置传递的参数的元组.如果省略了args,任何参数都不会被传递,kwargs是一个包含关键字参数的字典. apply()的返回值就是func()的返回值,apply()的元素参数是有序的,元素的顺序必须和func()形式参数的顺序一致 二.使用示例: 下面给几个例子来
-

python中apply函数详情
函数原型: DataFrame.apply(func, axis=0, broadcast=False, raw=False, reduce=None, args=(), **kwds) 1.该函数最有用的是第一个参数,这个参数是函数,相当于C/C++的函数指针. 2.这个函数需要自己实现,函数的传入参数根据axis来定,比如axis = 1,就会把一行数据作为Series的数据 结构传入给自己实现的函数中,我们在函数中实现对Series不同属性之间的计算,返回一个结果,则apply函数 会自动
-
python3中apply函数和lambda函数的使用详解
目录 lambda函数 lambda是什么 lambda用法详解 lambda+map lambda+ filter lambda+ reduce 避免过度使用lambda 适合lambda的场景 总结 apply函数 lambda函数 lambda是什么 大家好,今天给大家带来的是有关于Python里面的lambda表达式详细解析.lambda在Python里面的用处很广,但说实话,我个人认为有关于lambda的讨论不是如何使用的问题,而是该不该用的问题.接下来还是通过大量实例和大家分享我的学
-
Python中print()函数的用法详情
Python中print()函数的方法是打印指定的内容.在交互环境中输入“help(print)”指令,可以显示print()函数的使用方法, 如图1所示: 图1 print()函数的使用方法 1 常用方法 1.1 打印单个内容 从图1中可以看出,print()函数的第一个参数是value,即要打印的内容.通过print()打印单个内容的方法 如图2所示: 图2 打印单个内容 1.2 打印多个内容 从图1中可以看出,print()函数的第二个参数是...,表示print()函数要打印的多个参数,
-
Python pandas中apply函数简介以及用法详解
目录 1.基本信息 2.语法结构 3.使用案例 3.1 DataFrame使用apply 3.2 Series使用apply 3.3 其他案例 4.总结 参考链接: 1.基本信息 Pandas 的 apply() 方法是用来调用一个函数(Python method),让此函数对数据对象进行批量处理.Pandas 的很多对象都可以使用 apply() 来调用函数,如 Dataframe.Series.分组对象.各种时间序列等. 2.语法结构 apply() 使用时,通常放入一个 lambd
-
Python中zip()函数用法实例教程
本文实例讲述了Python中zip()函数的定义及用法,相信对于Python初学者有一定的借鉴价值.详情如下: 一.定义: zip([iterable, ...]) zip()是Python的一个内建函数,它接受一系列可迭代的对象作为参数,将对象中对应的元素打包成一个个tuple(元组),然后返回由这些tuples组成的list(列表).若传入参数的长度不等,则返回list的长度和参数中长度最短的对象相同.利用*号操作符,可以将list unzip(解压). 二.用法示例: 读者看看下面的例子,
-
详解python中groupby函数通俗易懂
一.groupby 能做什么? python中groupby函数主要的作用是进行数据的分组以及分组后地组内运算! 对于数据的分组和分组运算主要是指groupby函数的应用,具体函数的规则如下: df[](指输出数据的结果属性名称).groupby([df[属性],df[属性])(指分类的属性,数据的限定定语,可以有多个).mean()(对于数据的计算方式--函数名称) 举例如下: print(df["评分"].groupby([df["地区"],df["类
-
Python 中 Shutil 模块详情
一.什么是shutil shutil可以简单地理解为sh + util ,shell工具的意思.shutil模块是对os模块的补充,主要针对文件的拷贝.删除.移动.压缩和解压操作. 二.shutil模块的主要方法 1. shutil.copyfileobj(fsrc, fdst[, length=16*1024]) copy文件内容到另一个文件,可以copy指定大小的内容.这个方法是shutil模块中其它拷贝方法的基础,其它方法在本质上都是调用这个方法. 让我们看一下它的源码: def copy
-
python中分组函数groupby和分组运算函数agg的使用
目录 groupby: agg: 今天来介绍pandas中一个很有用的函数groupby,其实和hive中的groupby的效果是一样的,区别在于两种语言的写法问题.groupby在Python中的分组统计中很有用~ groupby: 首先创建数据: import pandas as pd import numpy as np df = pd.DataFrame({'A': ['a', 'b', 'a', 'c', 'a', 'c', 'b', 'c'], 'B': [2, 7, 1, 3, 3
-
python中__init__()方法详情
目录 python类中定义的函数称为方法, init ()方法本质也是一个函数.这个函数的作用是初始化实例后的对象. 具体如下例: init()方法的作用是初始化实例后的对象cqueue. class CQueue: 类中的函数称为方法 ,这里的__init__()方法在类实例化是被自动调用.若类定义了__init__()方法,类的实例化操作会自动调用__init__方法. __init__方法可以有参数,参数通过__init__()传递到类的实例化操作上.self代表的是类的实例,而非类. 类