C语言数据结构中堆排序的分析总结
目录
- 一、本章重点
- 二、堆
- 2.1堆的介绍(三点)
- 2.2向上调整
- 2.3向下调整
- 2.4建堆(两种方式)
- 三、堆排序
一、本章重点
- 堆
- 向上调整
- 向下调整
- 堆排序
二、堆
2.1堆的介绍(三点)
1.物理结构是数组
2.逻辑结构是完全二叉树
3.大堆:所有的父亲节点都大于等于孩子节点,小堆:所有的父亲节点都小于等于孩子节点。
2.2向上调整
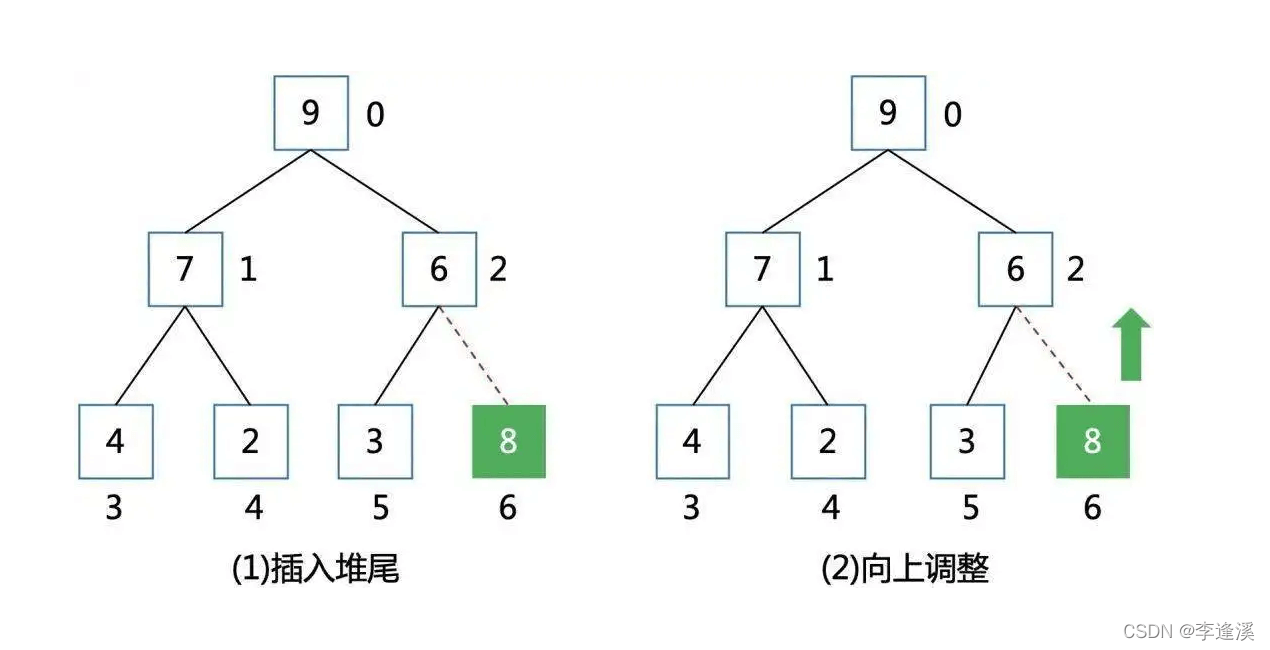
概念:有一个小/大堆,在数组最后插入一个元素,通过向上调整,使得该堆还是小/大堆。
使用条件:数组前n-1个元素构成一个堆。
以大堆为例:
逻辑实现:
将新插入的最后一个元素看做孩子,让它与父亲相比,如果孩子大于父亲,则将它们交换,将父亲看做孩子,在依次比较,直到孩子等于0结束调整·。
如果中途孩子小于父亲,则跳出循环,结束调整。
参考代码:
void AdjustUp(HPDataType* a, int child)
{
int parent = (child - 1) / 2;
while (child > 0)
{
if (a[child] > a[parent])//如果孩子大于父亲,则将它们交换。
{
Swap(&a[child], &a[parent]);
//迭代过程:
child = parent;
parent = (child - 1) / 2;
}
else
{
//如果孩子小于父亲,结束调整
break;
}
}
}
向上调整应用
给大\小堆加入新的元素之后仍使得大\小堆还是大\小堆。
2.3向下调整
概念:根节点的左右子树都是大\小堆,通过向下调整,使得整个完全二叉树都是大\小堆。
使用条件:根节点的左右子树都是大\小堆。
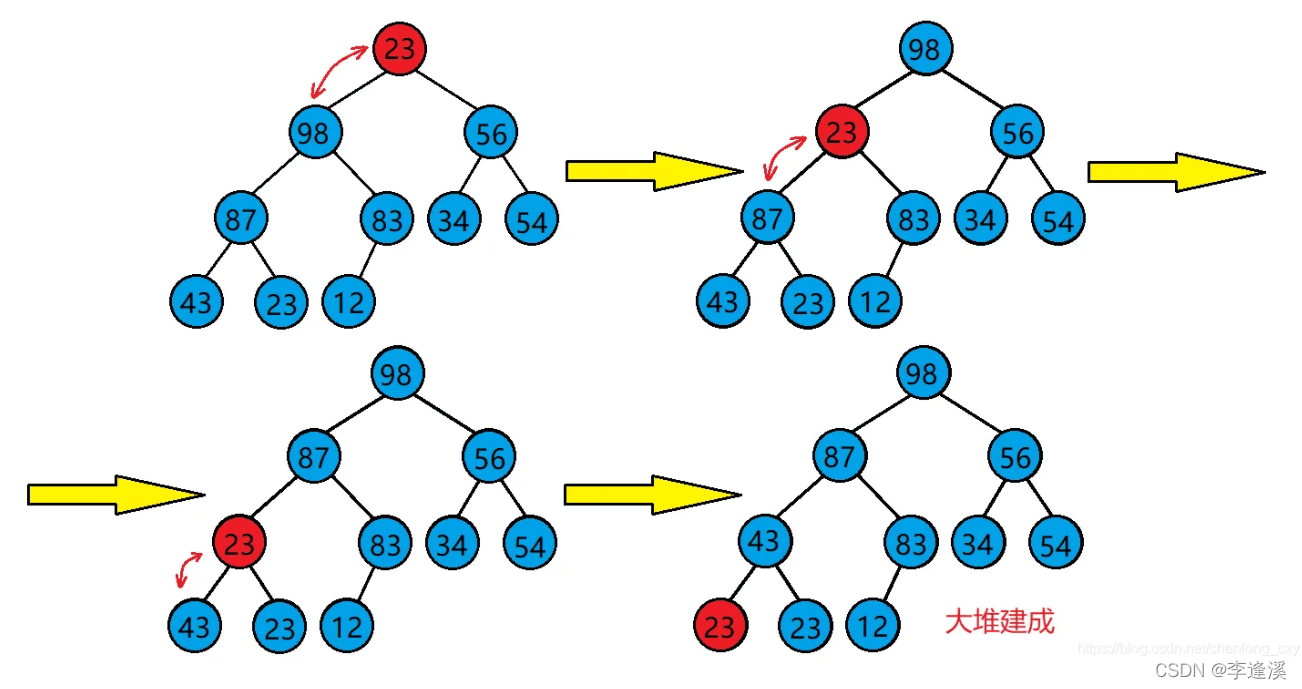
如图根为23,它的左右子树都是大堆,但整颗完全二叉树不是堆,通过向下调整可以使得整颗完全二叉树是堆。
逻辑实现:
选出根的左右孩子较大的那个孩子,然后与根比较,如果比根大,则交换,否则结束调整。
参考代码:
void AdjustDown(HPDataType* a, int size, int root)
{
int parent = root;
int child = parent * 2 + 1;//左孩子
while (child < size)
{
if (child + 1 < size && a[child] < a[child + 1])//如果左孩子小于右孩子,则选右孩子
{
//务必加上child+1,因为当child=size-1时,右孩子下标是size,对其接引用会越界访问。
child++;//右孩子的下标等于左孩子+1
}
if (a[child] > a[parent])//让较大的孩子与父亲比较,如果孩子大于父亲,则将它们交换。
{
Swap(&a[child], &a[parent]);
//迭代过程
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}
2.4建堆(两种方式)
第一种:向上调整建堆(时间复杂度是O(N*logN),空间复杂度O(1))
思路是:从第二个数组元素开始到最后一个数组元素依次进行向上调整。
参考代码:
for (int i = 1; i < n; i++)
{
AdjustUp(a, i);
}
时间复杂度计算:
以满二叉树进行计算
最坏情况执行步数为:T=(2^1)*1+(2^2)*2+(2^3)*3+....+2^(h-1)*(h-1)
最后化简得:T=2^h*(h-2)+2
又因为(2^h)-1=N
所以h=log(N+1)
带入后得T=(N+1)*(logN-1)+2
因此它的时间复杂度是:O(N*logN)
第二种:向下调整建堆(时间复杂度是O(N),空间复杂度是O(1))
从最后一个非叶子节点(最后一个数组元素的父亲)开始到第一个数组元素依次进行向下调整。
参考代码:
//n代表数组元素个数,j的初始值代表最后一个元素的父亲下标
for (int j = (n - 1 - 1) / 2; j >= 0; j--)
{
AdjustDown(a, n, j);
}
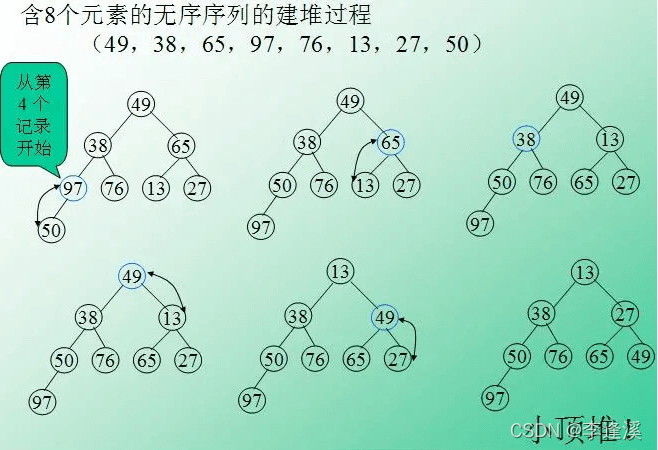
时间复杂度计算:
以满二叉树进行计算
最坏执行次数:
T=2^(h-2)*1+2^(h-3)*2+2^(h-4)*3+.....+2^3*(h-4)+2^2*(h-3)+2^1*(h-2)+2^0*(h-1)
联立2^h-1=N
化简得T=N-log(N+1)
当N很大时,log(N+1)可以忽略。
因此它的时间复杂度是O(N)。
因此我们一般建堆采用向下调整的建堆方式。
三、堆排序
目前最好的排序算法时间复杂度是O(N*logN)
堆排序的时间复杂度是O(N*logN)
堆排序是对堆进行排序,因此当我们对某个数组进行排序时,我们要先将这个数组建成堆,然后进行排序。
首先需要知道的是:
对数组升序,需要将数组建成大堆。
对数组降序,需要将数组建成小堆。
这是为什么呢?
这需要明白大堆和小堆的区别,大堆堆顶是最大数,小堆堆顶是最小数。
当我们首次建堆时,建大堆能够得到第一个最大数,然后可以将它与数组最后的元素进行交换,下一次我们只需要将堆顶的数再次进行向下调整,可以再次将数组变成大堆,然后与数组的倒数第二个元素进行交换,自此已经排好了两个元素,使得它们存储在需要的地方,然后依次进行取数,调整。
而如果是小堆,首次建堆时,我们能够得到最小的数,然后将它放在数组第一个位置,然后你要保持它还是小堆,该怎么办呢?只能从第二个元素开始从下建堆,而建堆的时间复杂度是O(N),你需要不断重建堆,最终堆排序的时间复杂度是O(N*N),这是不明智的。
或者建好小堆后,你这样做:
在开一个n个数组的空间,选出第一个最小数就将它放在新开辟的数组空间中保存,然后删除堆顶数,再通过向下调整堆顶的数,再将新堆顶数放在新数组的第二个位置.......。
虽然这样的时间复杂度是O(N*logN)。
但这样的空间复杂度是O(N)。
也不是最优的堆排序方法。
而建大堆的好处就在它把选出的数放在最后,这样我们就可以对堆顶进行向下调整,使得它还是大堆,而向下调整的时间复杂度是O(logN),最终堆排序的时间复杂度是O(N*logN)。
堆排序的核心要义:
通过建大堆或者小堆的方式,选出堆中最大或者最小的数,从后往前放。
参考代码:
int end = n - 1;//n代表数组元素的个数
while (end > 0)
{
Swap(&a[0], &a[end]);
AdjustDown(a, end, 0);
end--;
}
整个堆排序的代码:
void Swap(int* a, int* b)
{
int temp = *a;
*a = *b;
*b = temp;
}
void AdjustUp(int* a, int child)
{
int parent = (child - 1) / 2;
while (child > 0)
{
if (a[child] > a[parent])
{
Swap(&a[child], &a[parent]);
child = parent;
parent = (child - 1) / 2;
}
else
{
break;
}
}
}
void AdjustDown(int* a, int n, int root)
{
int child = 2 * root + 1;
while (child < n)
{
if (child + 1 < n && a[child] < a[child+1])
{
child++;
}
if (a[child] > a[root])
{
Swap(&a[child], &a[root]);
root = child;
child = 2 * root + 1;
}
else
{
break;
}
}
}
void HeapSort(int* a, int n)
{
//建大堆(向上调整)
//for (int i = 1; i < n; i++)
//{
// AdjustUp(a, i);
//}
//建大堆(向下调整)
for (int j = (n - 1 - 1) / 2; j >= 0; j--)
{
AdjustDown(a, n, j);
}
//升序
int end = n - 1;
while (end > 0)
{
Swap(&a[0], &a[end]);
AdjustDown(a, end, 0);
end--;
}
}
void printarr(int* a, int n)
{
for (int i = 0; i < n; i++)
{
printf("%d ", a[i]);
}
printf("\n");
}
int main()
{
int arr[10] = { 9,2,4,8,6,3,5,1,10 };
int size = sizeof(arr) / sizeof(arr[0]);
HeapSort(arr, size);
printarr(arr, size);
return 0;
}
到此这篇关于C语言数据结构中堆排序的分析总结的文章就介绍到这了,更多相关C语言 堆排序内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
C语言实现基于最大堆和最小堆的堆排序算法示例
堆定义 堆实际上是一棵完全二叉树,其任何一非叶节点满足性质: Key[i]<=key[2i+1]&&Key[i]<=key[2i+2](小顶堆)或者:Key[i]>=Key[2i+1]&&key>=key[2i+2](大顶堆) 即任何一非叶节点的关键字不大于或者不小于其左右孩子节点的关键字. 堆排序的思想 利用大顶堆(小顶堆)堆顶记录的是最大关键字(最小关键字)这一特性,使得每次从无序中选择最大记录(最小记录)变得简单. 最大堆:所有节点的子节点比其
-

C语言数据结构之堆排序源代码
本文实例为大家分享了C语言堆排序源代码,供大家参考,具体内容如下 1. 堆排序 堆排序的定义及思想可以参考百度百科: 用一句概括,堆排序就是一种改进的选择排序,改进的地方在于,每次做选择的时候,不单单把最大的数字选择出来,而且把排序过程中的一些操作进行了记录,这样在后续排序中可以利用,并且有分组的思想在里面,从而提高了排序效率,其效率为O(n*logn). 2. 源代码 堆排序中有两个核心的操作,一个是创建大顶堆(或者小顶堆,这里用的是大顶堆),再一个就是对堆进行调整.这里需要注意的是,并没有真
-
C语言数据结构之堆排序详解
目录 1.堆的概念及结构 2.堆的实现 2.1堆的向下调整算法 2.2堆的向上调整算法 2.3建堆(数组) 2.4堆排序 2.5堆排序的时间复杂度 1.堆的概念及结构 如果有一个关键码的集合K = {k0,k1, k2,…,kn-1},把它的所有元素按完全二叉树(二叉树具体概念参见——二叉树详解)的顺序存储方式存储在一个一维数组中,并满足:Ki <= K2i+1 且 Ki<= K2i+2 (Ki >= K2i+1 且 Ki >= K2i+2) i = 0,1,2…,则称为小堆(或大
-
C语言八大排序之堆排序
目录 前言 一.堆排序的概念 二.堆排序的实现 第一步:构建堆 第二步:排序 三.完整代码 四.证明建堆的时间复杂度 前言 本章我们来讲解八大排序之堆排序.2022,地球Online新赛季开始了!让我们一起努力内卷吧! 一.堆排序的概念 堆排序(Heapsort):利用堆积树(堆)这种数据结构所设计的一种排序算法,它是选择排序的一种.通过堆来进行选择数据,需要注意的是 排升序要建大堆,排降序建小堆. 堆排序使用堆来选数,效率就高了很多. 时间复杂度: 空间复杂度: 稳定性:不稳定 二.堆排序的实
-
C语言实现堆排序的简单实例
本文通过一个C语言实现堆排序的简单实例,帮助大家抛开复杂的概念,更好的理解堆排序. 实例代码如下: void FindMaxInHeap(int arr[], const int size) { for (int j = size - 1; j > 0; --j) { int parent = j / 2; int child = j; if (j < size - 1 && arr[j] < arr[j+1]) { ++child; } if (arr[child] &
-
C语言对堆排序一个算法思路和实现代码
算法思想简单描述: 堆排序是一种树形选择排序,是对直接选择排序的有效改进. 堆的定义如下:具有n个元素的序列(h1,h2,...,hn),当且仅当满足(hi>=h2i,hi>=2i+1)或(hi<=h2i,hi<=2i+1)(i=1,2,...,n/2)时称之为堆.在这里只讨论满足前者条件的堆. 由堆的定义可以看出,堆顶元素(即第一个元素)必为最大项.完全二叉树可以很直观地表示堆的结构.堆顶为根,其它为左子树.右子树. 初始时把要排序的数的序列看作是一棵顺序存储的二叉树,调整它们的
-
C语言 数据结构堆排序顺序存储(升序)
堆排序顺序存储(升序) 一: 完全二叉树的概念:前h-1层为满二叉树,最后一层连续缺失右结点! 二:首先堆是一棵全完二叉树: a:构建一个堆分为两步:⑴创建一棵完全二叉树 ⑵调整为一个堆 (标注:大根堆为升序,小根堆为降序) b:算法描述:①创建一棵完全二叉树 ②while(有双亲){ A:调整为大根堆: B:交换根和叶子结点: C:砍掉叶子结点: } c:时间复杂度为 O(nlogn) ,空间复杂度为 O(1), 是不稳定排序! 代码实现: /*堆排序思想:[完全二叉树的定义:前
-
C语言数据结构中堆排序的分析总结
目录 一.本章重点 二.堆 2.1堆的介绍(三点) 2.2向上调整 2.3向下调整 2.4建堆(两种方式) 三.堆排序 一.本章重点 堆 向上调整 向下调整 堆排序 二.堆 2.1堆的介绍(三点) 1.物理结构是数组 2.逻辑结构是完全二叉树 3.大堆:所有的父亲节点都大于等于孩子节点,小堆:所有的父亲节点都小于等于孩子节点. 2.2向上调整 概念:有一个小/大堆,在数组最后插入一个元素,通过向上调整,使得该堆还是小/大堆. 使用条件:数组前n-1个元素构成一个堆. 以大堆为例: 逻辑实现: 将
-
C语言数据结构中二分查找递归非递归实现并分析
C语言数据结构中二分查找递归非递归实现并分析 前言: 二分查找在有序数列的查找过程中算法复杂度低,并且效率很高.因此较为受我们追捧.其实二分查找算法,是一个很经典的算法.但是呢,又容易写错.因为总是考虑不全边界问题. 用非递归简单分析一下,在编写过程中,如果编写的是以下的代码: #include<iostream> #include<assert.h> using namespace std; int binaty_search(int* arr, size_t n, int x)
-
C语言 数据结构中求解迷宫问题实现方法
C语言 数据结构中求解迷宫问题实现方法 在学习数据结构栈的这一节遇到了求迷宫这个问题,拿来分享一下~ 首先求迷宫问题通常用的是"穷举求解" 即从入口出发,顺某一方向试探,若能走通,则继续往前走,否则原路返回,换另一个方向继续试探,直至走出去. 我们可以先建立一个8*8的迷宫其中最外侧为1的是墙 int mg[M+2][N+2]={ {1,1,1,1,1,1,1,1,1,1}, {1,0,0,1,0,0,0,1,0,1}, {1,0,0,1,0,0,0,1,0,1}, {1,0,0,0,
-
C语言数据结构中串的模式匹配
C语言数据结构中串的模式匹配 串的模式匹配问题:朴素算法与KMP算法 #include<stdio.h> #include<string.h> int Index(char *S,char *T,int pos){ //返回字串T在主串S中第pos个字符之后的位置.若不存在,则函数值为0. //其中,T非空,1<=pos<=StrLength(s). int i=pos; int j=1; while(i<=S[0]&&j<=T[0]){ i
-
C语言数据结构中数制转换实例代码
C语言数据结构中数制转换实例代码 数制转换是严蔚敏的数据结构那本书中的例子,但是那本书中的例子大都是用伪代码的形式写的,不是很容易理解和实现,对初学者造成了不小的困扰,在这里我们将其详尽的实现出来,以便初学者调试和运行,并从中有所收获. #include <stdlib.h> #include <stdio.h> #include<malloc.h> #define STACK_INIT_SIZE 10 //定义最初申请的内存的大小 #define STACK_INCR
-
C语言数据的存储专项分析
目录 数据的类型介绍 类型的基本归类 整形在内存中的存储 源码.反码.补码 关于大小端的概念 浮点型在内存中的存储 数据的类型介绍 类型的基本归类 在写数据类型的介绍之前,我们首先来简单介绍下 release版本与debug版本之间的在内存上的区别: 我们先将下面的一段代码在VS中运行一下,得到的结果是截然不同的 int i = 0; int arr[] = { 1,2,3,4,5,6,7,8,9,10 }; for (i = 0; i <= 12; i++) { arr[i] = 0; pri
-
C语言数据结构中约瑟夫环问题探究
目录 问题描述 基本要求 测试数据 实现思路1 实现思路2 结果 数据结构开讲啦!!! 本专栏包括: 抽象数据类型 线性表及其应用 栈和队列及其应用 串及其应用 数组和广义表 树.图及其应用 存储管理.查找和排序 将从简单的抽象数据类型出发,深入浅出地讲解复数 到第二讲线性表及其应用中会讲解,运动会分数统计,约瑟夫环,集合的并.交和差运算,一元稀疏多项式计算器 到最后一步一步学会利用数据结构和算法知识独立完成校园导航咨询的程序. 希望我们在学习的过程中一起见证彼此的成长. 问题描述 约瑟夫环问题
-
C语言数据结构中树与森林专项详解
目录 树的存储结构 树的逻辑结构 双亲表示法(顺序存储) 孩字表示法(顺序+链式存储) 孩子兄弟表示法(链式存储) 森林 树的遍历 树的先根遍历(深度优先遍历) 树的后根遍历(树的深度优先遍历) 树的层序遍历(广度优先遍历) 森林的遍历 先序遍历森林 中序遍历森林 树的存储结构 树的逻辑结构 树是n(n≥0)个结点的有限集合,n=0时,称为空树,这是一种特殊情况.在任意--棵非空树中应满足: 1)有且仅有一个特定的称为根的结点. 2)当n>1时,其余结点可分为m(m>0)个互不相交的有限集合T
-
C语言数据结构中定位函数Index的使用方法
数据结构中定位函数Index的使用方法 实现代码: #include<stdio.h> #include<string.h> #include<stdlib.h> #define OK 1 #define ERROR 0 #define TRUE 1 #define FALSE 0 #define MAXSIZE 40 //最大字符串 typedef int Status; typedef char SString[MAXSIZE+1]; //此处声明的SString[
-
C语言 数据结构中栈的实现代码
数据结构中的栈是什么 举一个简单的例子:在往箱子里面放衣物的时候,放在最上面的衣物总是我们最后放上去的:而当我们从箱子里取出衣物的时候,总是最先拿出上面的.这就是现实生活中的栈. 准确的讲,栈就是一种可以实现"先进后出(或者叫后进先出)"的存储结构. 学过数据结构的人都知道:栈可以用两种方式来实现,一种方法是用数组实现栈,这种栈成为静态栈:另外一种方法是用链表实现栈,这种栈叫做动态栈. 栈中通常存放着程序的局部变量等.栈通常有出栈和入栈操作. 栈的结构 空栈的结构:[其实就是栈顶和栈顶