Python处理PDF与CDF实例
在拿到数据后,最需要做的工作之一就是查看一下自己的数据分布情况。而针对数据的分布,又包括pdf和cdf两类。
下面介绍使用python生成pdf的方法:
使用matplotlib的画图接口hist(),直接画出pdf分布;
使用numpy的数据处理函数histogram(),可以生成pdf分布数据,方便进行后续的数据处理,比如进一步生成cdf;
使用seaborn的distplot(),好处是可以进行pdf分布的拟合,查看自己数据的分布类型;
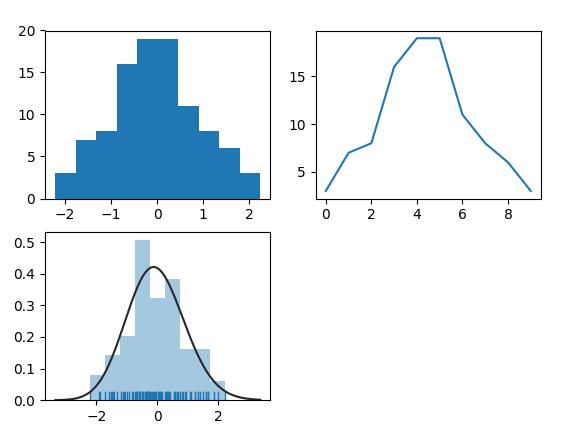
上图所示为采用3种算法生成的pdf图。下面是源代码。
from scipy import stats import matplotlib.pyplot as plt import numpy as np import seaborn as sns arr = np.random.normal(size=100) # plot histogram plt.subplot(221) plt.hist(arr) # obtain histogram data plt.subplot(222) hist, bin_edges = np.histogram(arr) plt.plot(hist) # fit histogram curve plt.subplot(223) sns.distplot(arr, kde=False, fit=stats.gamma, rug=True) plt.show()
下面介绍使用python生成cdf的方法:
使用numpy的数据处理函数histogram(),生成pdf分布数据,进一步生成cdf;
使用seaborn的cumfreq(),直接画出cdf;
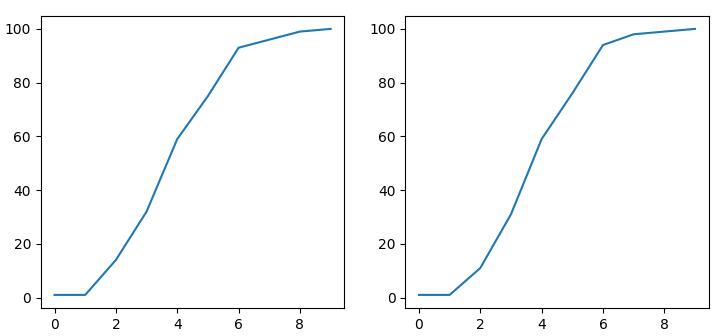
上图所示为采用2种算法生成的cdf图。下面是源代码。
from scipy import stats import matplotlib.pyplot as plt import numpy as np import seaborn as sns arr = np.random.normal(size=100) plt.subplot(121) hist, bin_edges = np.histogram(arr) cdf = np.cumsum(hist) plt.plot(cdf) plt.subplot(122) cdf = stats.cumfreq(arr) plt.plot(cdf[0]) plt.show()
在更多时候,需要把pdf和cdf放在一起,可以更好的显示数据分布。这个实现需要把pdf和cdf分别进行归一化。
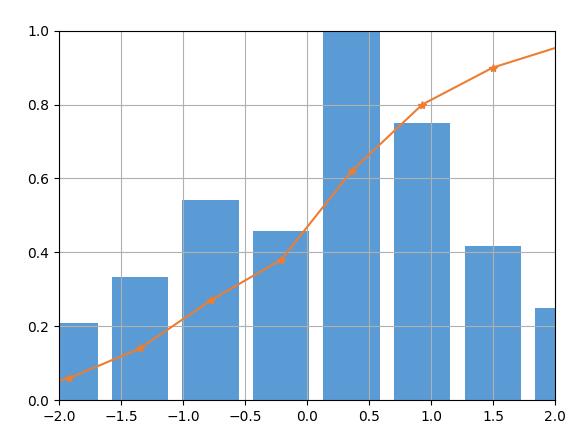
上图所示为归一化的pdf和cdf。下面是源代码。
from scipy import stats import matplotlib.pyplot as plt import numpy as np import seaborn as sns arr = np.random.normal(size=100) hist, bin_edges = np.histogram(arr) width = (bin_edges[1] - bin_edges[0]) * 0.8 plt.bar(bin_edges[1:], hist/max(hist), width=width, color='#5B9BD5') cdf = np.cumsum(hist/sum(hist)) plt.plot(bin_edges[1:], cdf, '-*', color='#ED7D31') plt.xlim([-2, 2]) plt.ylim([0, 1]) plt.grid() plt.show()
以上这篇Python处理PDF与CDF实例就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
使用python绘制cdf的多种实现方法
首先我们先用随机函数编造一个包含1000个数值的一维numpy数组,如下: // An highlighted block rng = np.random.RandomState(seed=12345) samples = stats.norm.rvs(size=1000, random_state=rng) 接下来我们将使用各种方法画出以上数据的累积分布图 1.matplotlib.pyplot.hist() def hist(self, x, bins=None, range=None, d
-
python读取与处理netcdf数据方式
netcdf是气候数据中的主流格式,当涉及到大范围的全球数万个格网点数据时,使用python脚本可以较快地读取与处理. import netCDF4 from netCDF4 import Dataset import numpy as np import sys import os #计算日期数 import datetime d1=datetime.date(1900,1,1) d3 = d1 + datetime.timedelta(days =100) print (d3) #查看nc数
-
Python处理PDF与CDF实例
在拿到数据后,最需要做的工作之一就是查看一下自己的数据分布情况.而针对数据的分布,又包括pdf和cdf两类. 下面介绍使用python生成pdf的方法: 使用matplotlib的画图接口hist(),直接画出pdf分布: 使用numpy的数据处理函数histogram(),可以生成pdf分布数据,方便进行后续的数据处理,比如进一步生成cdf: 使用seaborn的distplot(),好处是可以进行pdf分布的拟合,查看自己数据的分布类型: 上图所示为采用3种算法生成的pdf图.下面是源代码.
-
利用python将pdf输出为txt的实例讲解
一个礼拜前一个同学问我这个事情,由于之前在参加华为的比赛,所以赛后看了一下,据说需要用到pdfminer这个包.于是安装了一下,安装过程很简单: sudo pip install pdfminer; 中间也没有任何的报错.至于如何调用,本人也没有很好的研究过pdfminer这个库,于是开始了百度-- 官方文档:http://www.unixuser.org/~euske/python/pdfminer/index.html 完全使用python编写. (适用于2.4或更新版本) 解析,分析,并转
-
python输出pdf文档的实例
python导出pdf,参考诸多资料,发现pdfkit是效果比较好的. 故下载后进行了实现,多次失败后终于成功了,现将其中经验总结如下: """ 需要安装pdfkit,另外需要安装可执行文件wkhtmltopdf.exe, pdfkit核心命令是调用wkhtmltopdf.exe实现转pdf 有三个接口: pdfkit.from_url pdfkit.from_string pdfkit.from_file 需要注意的是,pdfkit主要是用来将html转pdf,所以文件也是
-

利用Python提取PDF文本的简单方法实例
目录 第一步,安装工具库 第二步,编写代码 第三步,执行 最后的话 你好,一般情况下,Ctrl+C 是最简单的方法,当无法 Ctrl+C 时,我们借助于 Python,以下是具体步骤: 第一步,安装工具库 1.tika — 用于从各种文件格式中进行文档类型检测和内容提取 2.wand — 基于 ctypes 的简单 ImageMagick 绑定 3.pytesseract — OCR 识别工具 创建一个虚拟环境,安装这些工具 python -m venv venv source venv/bin
-
Python生成pdf文件的方法
本文实例演示了Python生成pdf文件的方法,是比较实用的功能,主要包含2个文件.具体实现方法如下: pdf.py文件如下: #!/usr/bin/python from reportlab.pdfgen import canvas def hello(): c = canvas.Canvas("helloworld.pdf") c.drawString(100,100,"Hello,World") c.showPage() c.save() hello() di
-
Python实现pdf文档转txt的方法示例
本文实例讲述了Python实现pdf文档转txt的方法.分享给大家供大家参考,具体如下: 首先,这是一个比较粗糙的版本,因为已经够用了,而且对pdf的格式不熟悉,所以暂时没有进一步优化. 还有,这是转成txt的,所以如果是有图片的pdf是无法保存图片的. 至于本来就是图片的文本,这里是无法分析出来的.那些图片的pdf,估计要用图形匹配的方式来处理,类似于超速拍摄的车牌识别. 不过这样的程度,已经不是文本处理了.扯远了... 转出来的文字,好像按照pdf里面的所展示的来换行了,看不到有什么规则还原
-
python实现pdf转换成word/txt纯文本文件
本文实例为大家分享了python实现pdf转word/txt,供大家参考,具体内容如下 依赖包:pdfminer3k 可以通过pip安装:也可以到官网下载,解压,进入文件夹,输入命令setup.py install安装软件. 源代码: #!/usr/bin/python # -*- coding: utf-8 -*- import sys import importlib importlib.reload(sys) from pdfminer.pdfparser import PDFParser
-
python实现PDF中表格转化为Excel的方法
这几天想统计一下<中国人文社会科学期刊 AMI 综合评价报告(2018 年):A 刊评价报告>中的期刊,但是只找到了该报告的PDF版,对于表格的编辑不太方便,于是想到用Python将表格转成Excel格式. 看过别人写的博客,发现Python解析PDF有以下四种方式: -pdfminer:擅长文字的解析,把表格解析成普通的文本,没有格式: -pdf2html:把pdf解析成html,但html的标签并没有规律,解析一个表格还可以,多个表格的话不太好提取: -tabula:对于简单的表格,即单元
-
python从PDF中提取数据的示例
01 前言 数据是数据科学中任何分析的关键,大多数分析中最常用的数据集类型是存储在逗号分隔值(csv)表中的干净数据.然而,由于可移植文档格式(pdf)文件是最常用的文件格式之一,因此每个数据科学家都应该了解如何从pdf文件中提取数据,并将数据转换为诸如"csv"之类的格式,以便用于分析或构建模型. 在本文中,我们将重点讨论如何从pdf文件中提取数据表.类似的分析可以用于从pdf文件中提取其他类型的数据,如文本或图像.我们将说明如何从pdf文件中提取数据表,然后将其转换为适合于进一步分
-
python字典的元素访问实例详解
说明 1.字典中没有下标的概念,使用key值访问字典中对应的value值.当访问的key值不存在时,代码会报错. 2.get('key'):直接将key值传入函数,当查询到相应的value值时,返回相应的值,当key值不存在时,返回None,代码不会出错. 3.get(key,数据):当查询相应的value值时,返回相应的值,当没有key值时,返回自定义的数据值. 实例 # 定义一个字典 dic = {'Name': '张三', 'Age': 20} # 使用 key 值访问元素 print(d