R语言行筛选的方法之filter函数详解
目录
- 1. 数据
- 2. 生成ID列和类型
- 3. 提取effect大于0.1的行
- 4. 提取加性效应,且effect小于0的行
- 5. 根据部分行名删选
- 6. 固定字符特征进行行筛选
- 总结
下面介绍一下R语言中行筛选的方法,主要介绍filter函数
1. 数据
这里,使用asreml分析中的BLUP值为例,相关的模型为:
m1 = asreml(Phen ~ G , random = ~ vm(Progeny,ainv) + vm(Dam,ainv) + vm(Progeny,dinv),
workspace = "10Gb", residual = ~ idv(units),data = dat)
summary(m1)$varcomp

计算育种值:
blup = coef(m1)$random head(blup) tail(blup)

数据特点:
- 没有ID列,rownames的前缀为类型,比如
vm(Progeny, ainv)为加性效应的BLUP值,vm(Progeny,dinv)为显性效应的BLUP值。
提取目的:
- 提取加性效应的BLUP值,显性效应的BLUP值和母体效应的BLUP
- 值提取BLUP值大于0.1的个体
2. 生成ID列和类型
首先,把rowname提取,作为新的一列
blup1 = blup %>% as.data.frame() %>% mutate(ID = rownames(.)) head(blup1)

根据下划线,进行分列:
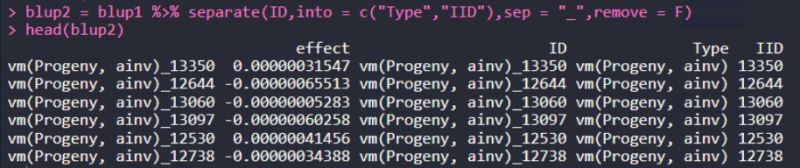
blup2 = blup1 %>% separate(ID,into = c("Type","IID"),sep = "_",remove = F)
head(blup2)
3. 提取effect大于0.1的行
re1 = blup2 %>% filter(effect>0.1) head(re1)

4. 提取加性效应,且effect小于0的行
这里,条件之间,默认是并集,如果想用交集,用|间隔。
re2 = blup2 %>% filter(Type == "vm(Progeny, ainv)",effect <0) head(re2)

5. 根据部分行名删选
select函数,可以根据开头,中间,结尾,进行列的删选。
filter结合其它函数,也可以进行行的筛选。
如果想对ID中,包含ainv的行,进行筛选,可以这样操作:
re3 = blup2 %>% filter(str_detect(ID,"ainv")) %>% arrange(-effect) head(re3)

注意,这里str_detect的pattern是正则表达式。如果直接用原始的字符:
re3 = blup2 %>% filter(str_detect(ID,"vm(Progeny, ainv)")) %>% arrange(-effect) head(re3)
可以看到,报错,如果想要支持,需要对括号用两个反斜线进行转义。

转义后的代码:
re3 = blup2 %>% filter(str_detect(ID,"vm\\(Progeny, ainv\\)")) %>% arrange(-effect) head(re3)

6. 固定字符特征进行行筛选
str_detect没有fixed = T的选项,如果想固定字符匹配,可以用fixed()函数:
re3 = blup2 %>% filter(str_detect(ID,fixed("vm(Progeny, ainv)"))) %>% arrange(-effect)
head(re3)

总结
到此这篇关于R语言行筛选的方法之filter函数详解的文章就介绍到这了,更多相关R语言行筛选filter函数内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

R语言dplyr包之高效数据处理函数(filter、group_by、mutate、summarise)详解
R语言dplyr包的数据整理.分析函数用法文章连载NO.01 在日常数据处理过程中难免会遇到些难处理的,选取更适合的函数分割.筛选.合并等实在是大快人心! 利用dplyr包中的函数更高效的数据清洗.数据分析,及为后续数据建模创造环境:本篇涉及到的函数为filter.filter_all().filter_if().filter_at().mutate.group_by.select.summarise. 1.数据筛选函数: #可使用filter()函数筛选/查找特定条件的行或者样本 #filte
-
R语言:数据筛选match的使用详解
数据筛选是在分析中最常用的步骤,如微生物组分析中,你的OTU表.实验设计.物种注释之间都要不断筛选,来进行数据对齐,或局部分析. 今天来详解一下此函数的用法. match match:匹配两个向量,返回x中存在的返回索引或TRUE.FALSE match函数使用格式有如下两种: 第一种方便设置参数,返回x中元素在table中的位置 match(x, table, nomatch = NA_integer_, incomparables = NULL) 第二种简洁,返回x中每个元素在table中是
-
R语言行筛选的方法之filter函数详解
目录 1. 数据 2. 生成ID列和类型 3. 提取effect大于0.1的行 4. 提取加性效应,且effect小于0的行 5. 根据部分行名删选 6. 固定字符特征进行行筛选 总结 下面介绍一下R语言中行筛选的方法,主要介绍filter函数 1. 数据 这里,使用asreml分析中的BLUP值为例,相关的模型为: m1 = asreml(Phen ~ G , random = ~ vm(Progeny,ainv) + vm(Dam,ainv) + vm(Progeny,dinv), work
-
R语言列筛选的方法select实例详解
目录 前言 1. 数据描述 2. 使用R语言默认的方法:列选择 3. tidyverse的rename函数 4. tidyverse的select函数 5. select函数注意事项 5.1 绝对引用函数 5.2 放到环境变量中 6. 提取h开头的列 7. 提取因子和数字的列 总结 前言 我们知道,R语言学习,80%的时间都是在清洗数据,而选择合适的数据进行分析和处理也至关重要,如何选择合适的列进行分析,你知道几种方法? 如何优雅高效的选择合适的列,让我们一起来看一下吧. 1. 数据描述 数据来
-
R语言使用cgdsr包获取TCGA数据示例详解
目录 TCGA数据源 TCGA数据库探索工具 查看任意数据集的样本列表方式 选定数据形式及样本列表后获取感兴趣基因的信息,下载mRNA数据 选定样本列表获取临床信息 综合性获取 下载mRNA数据 获取病例列表的临床数据 从cBioPortal下载点突变信息 从cBioPortal下载拷贝数变异数据 把拷贝数及点突变信息结合画热图 TCGA数据源 众所周知,TCGA数据库是目前最综合全面的癌症病人相关组学数据库,包括的测序数据有: DNA Sequencing miRNA Sequencing P
-
R语言刷题检验数据缺失类型过程详解
目录 题目 解答 下面考虑三种情况: 1. a = 0, b = 0 2. a = 2, b = 0 3. a = 0, b = 2 题目 解答 由于题目要求需要重复三次类似的操作,故首先载入所需要的包,构造生成数据的函数以及绘图的函数: library(tidyr) # 绘图所需 library(ggplot2) # 绘图所需 # 生成数据 GenerateData <- function(a = 0, b = 0, seed = 2018) { set.seed(seed) z1 <- r
-
C语言头文件<string.h>函数详解
目录 1. strlen —— 求字符串长度 1.1 strlen 的声明与用处 1.2 strlen 的用法 1.3 strlen 的模拟实现 2. strcpy —— 字符串拷贝 2.1 strcpy 的声明与用处 2.2 strcpy 的用法 2.3 strcpy 的模拟实现 3. strcmp —— 字符串比较 3.1 strcmp 的声明与用处 3.2 strcmp 的用法 3.3 strcmp 的模拟实现 4. strcat —— 字符串追加 4.1 strcat 的声明与用处 4.
-
JavaScript中Array的filter函数详解
目录 描述 理解 示例 原生实现 描述 filter为数组中的每个元素调用一次callback函数,并利用所有使得callback返回 true 或等价于 true 的值的元素创建一个新数组.callback只会在已经赋值的索引上被调用,对于那些已经被删除或者从未被赋值的索引不会被调用.那些没有通过callback 测试的元素会被跳过,不会被包含在新数组中. 理解 filter不会改变原数组,它返回过滤后的新数组. filter遍历的元素范围在第一次调用callback之前就已经确定了.在调用f
-
R语言数据可视化学习之图形参数修改详解
1.图形参数的修改par()函数 我们可以通过使用par()函数来修改图形的参数,其调用格式为par(optionname=name, optionname=name,-).当par()不加参数时,返回当前图形参数设置的列表:par(no.readonly=T)将生成一个可以修改当前参数设置的列表.注意以这种方式修改参数设置,除非参数再次被修改,否则一直执行此参数设置. 例如现在想画出mtcars数据集中mpg的折线图,并用虚线代替实线,并将两幅图排列在同一幅图里,代码及图形如下: > opar
-
python3 map函数和filter函数详解
map()函数可以对一个数据进行同等迭代操作.例如: def f(x): return x * x r = map(f, [1, 2, 3, 4, 5, 6, 7, 8, 9]) print(list(r)) map函数传入的第一个参数就是函数本身,即f.第二个参数是要操作的数据 map() 作为高阶函数,事实上它把运算规则抽象了,因此,我们不但可以计算简单的 f(x)=x 2 ,还可以计算任意复杂的函数,比如,把这个list 所有数字转为字符串: print(list(map(str, [1,
-
R语言matrix生成矩阵的方法
主要介绍一下利用matrix函数和rep生成矩阵 在R语言中可以使用matrix()函数来创建矩阵,其语法格式如下: matrix(data=NA, nrow = 1, ncol = 1, byrow = FALSE, dimnames = NULL) 参数含义如下: data:矩阵的元素,默认为NA,即未给出元素值的话,各项为NA nrow:矩阵的行数,默认为1: ncol:矩阵的列数,默认为1: byrow:元素是否按行填充,默认按列: dimnames:以字符型向量表示的行名及列名. re
-
使用R语言填补缺失值的方法
使用R语言填补缺失值 数据处理过程中,往往会存在缺失值,对于缺失值的处理,目前各大统计书提出的方法有剔除,用均数填补,用众数填补,采用其他自变量进行回归,推算缺失值进行填补等.在R语言中如何按要求进行填补?下面将介绍如何进行缺失值填补的各种方法 用某特定值替换缺失值 下面这段代码表示使用0填补缺失值,x是需要填补的数据框的某行或某列,如果是其他值,将0改成需要的值即可. FillNA <- function(x){ x[is.na(x )]<- 0; x } 使用均值,众数,中位数进行填补 该