MySQL之高可用架构详解
目录
- 引言
- MySQL高可用
- 一主一备:
- MySQL主从同步的几种模式:
- 总结
引言
“高可用”是互联网一个永恒的话题,先避开MySQL不谈,为了保证各种服务的高可用有几种常用的解决方案。
服务冗余:把服务部署多份,当某个节点不可用时,切换到其他节点。服务冗余对于无状态的服务是相对容易的。
服务备份:有些服务是无法同时存在多个运行时的,比如说:Nginx的反向代理,一些集群的leader节点。这时可以存在一个备份服务,处于随时待命状态。
自动切换:服务冗余之后,当某个节点不可用时,要做到快速切换。
总结起来就是 冗余+故障转移 。
MySQL高可用
MySQL的高可用也是同样的思路,首先要有多个MySQL实例提供服务,其次就是当某个实例挂掉时,可以自动切换流量。同时MySQL作为存储,节点之间数据同步也是一个难题(换句话说,有状态的服务都面临这个问题)。
一主一备:
MySQL的各种高可用架构,都脱离不了MySQL实例之间的数据同步,因此,我们先介绍下最简单的一主一备架构下MySQL的数据同步流程。

上图是主从数据同步的一个示意图。
Master节点有Dump进程把binlog中的数据发送到Slave节点,
Slave节点有IO进程接收数据写入relay log,
Slave节点的SQL进程根据relay log写入数据。
这里还要延伸一点,binlog存在三种形式:Statement、Row、Mixed。
Statement:就是把每一条SQL记录到binlog中。
Row:是把每一行修改的具体数据记录到binlog中。
Mixed:MySQL会灵活的区分,需要记录sql还是具体修改的记录。
只记录SQL的话binlog会比较小,但是有些SQL语句在主从同步数据的时候,可能会因为选择不同的索引在数据同步过程中出现数据不一致。记录Row的话就可以保证主从同步不会存在SQL语意偏差的问题,同时Row类型的日志在做数据恢复的时候也比较容易,但是Row会导致binlog过大。
MySQL主从同步的几种模式:
异步模式:
在这种同步策略下,主库按照自己的流程处理完数据,会直接返回结果,不会等待主库和从库之间的数据同步。 优点:效率高。 缺点:Master节点挂掉之后,Slave节点会丢失数据。全同步模式: 主库会等待所有从库都执行完sql语句并ACK完成,才返回成功。 优点:有很好的数据一致性保障。 缺点:会造成数据操作延迟,降低了MySQL的吞吐量。半同步模式:主库会等待至少有一个从库把数据写入relay log并ACK完成,才成功返回结果。 半同步模式介于异步和全同步之间。
半同步的复制方案是在MySQL5.5开始引入的,普通的半同步复制方案步骤如下图:
Master节点写数据到Binlog,并且执行Sync操作。Master发送数据给Slave节点,同时commit主库的事务。收到ACK后Master节点把数据返回给客户端。
这种数据提交模式叫: after_commit
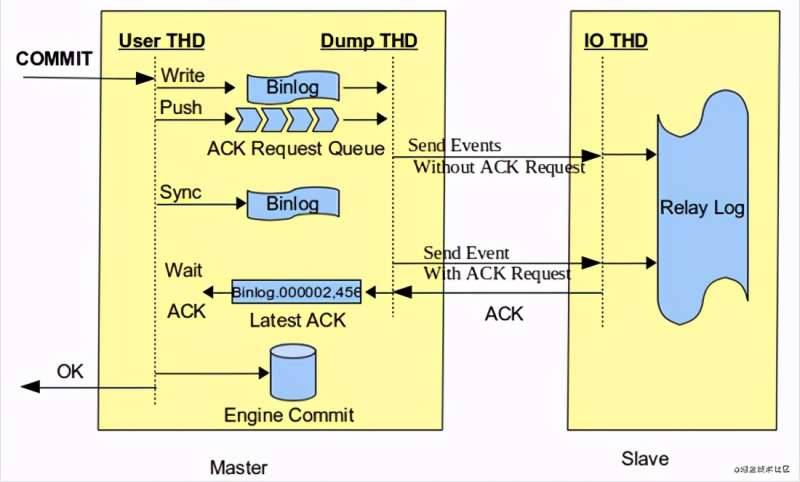
after_commit 模式存在问题: 主库等待ACK时,事务已经commit,主库的其他事务可以读到commit的数据,这个时候如果Master崩溃,slave数据丢失,发生主从切换,会导致出现幻读。 为了解决这个问题MySQL5.7提出了新的半同步复制模式: after_sync
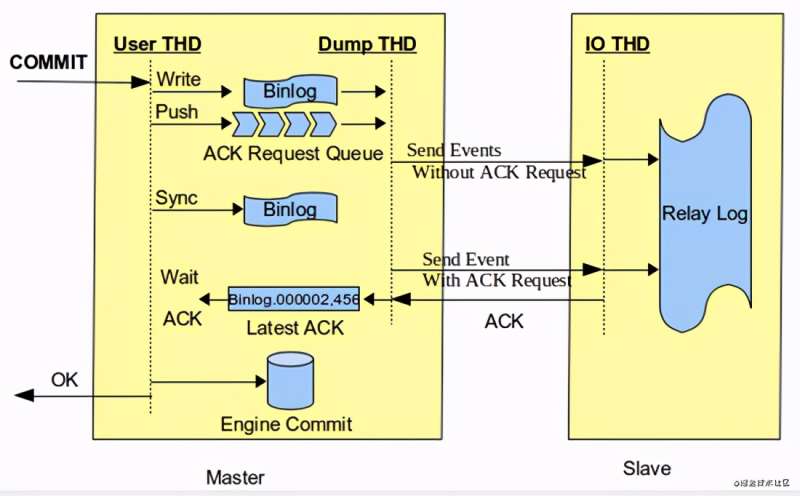
把主库的事务提交放到了ACK之后,避免了上述问题。 MySQL5.7还引入了 enhanced multi-threaded slave (简称MTS)模式, 当slave配置 slave_parallel_workers >0并且
global.slave_parallel_type =‘LOGICAL_CLOCK',可支持一个schema下,slave_parallel_workers个worker线程并发执行relay log中主库提交的事务,极大地提高了主从复制的效率。 MySQL5.7半同步功能可以通过
rpl_semi_sync_master_wait_slave_count 参数配置slave节点ACK的个数,认为主从同步完成。
基于MySQL主从同步数据越来越完善,效率越来越高,也就引出了第一种MySQL的高可用架构: 基于MySQL自身的主从同步方案,常用的一种部署架构是: 用户通过VIP访问Master和Slave节点,每个节点采用keepalved探索。配置主从关系,进行数据同步。

基于MHA的高可用架构: 部署一份MHA的Manager节点,在MySQL各个实例部署MHA Node节点。MHA可以实现秒级的故障自动转移。 当然MySQL节点之间的数据同步还要依赖MySQL自身的数据同步方式。

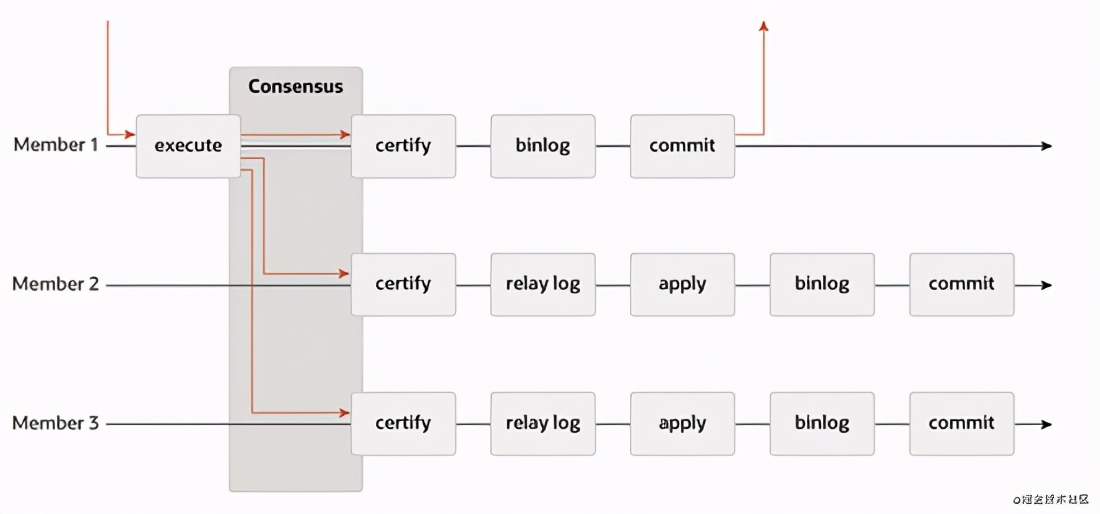
MGR(MySQL Group Replication)模式: 感觉MySQL官方更看好MGR集群方案,但是目前我还不知道国内有哪一家公司在使用。 MGR集群是由所有的MySQL Server共同组成的,每个Server都有完整的副本数据,副本之间基于Row格式的日志和GTID来做副本之前的数据同步,采用Paxos算法实现数据的一致性保障。 MGR架构要比前面讲述的半同步和异步同步数据的方式要复杂,具体可以参照 官网
总结
MySQL的高可用架构没有银弹,了解其原理,选择符合自己业务场景的部署架构就可以了。
到此这篇关于MySQL之高可用架构详解的文章就介绍到这了,更多相关MySQL高可用架构内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

MySQL高可用架构之MHA架构全解
目录 一.介绍 二.组成 三.工作过程 四.架构 五.实例展示 MHA(Master HA)是一款开源的 MySQL 的高可用程序,它为 MySQL 主从复制架构提供了 automating master failover 功能.MHA 在监控到 master 节点故障时,会提升其中拥有最新数据的 slave 节点成为新的master 节点,在此期间,MHA 会通过于其它从节点获取额外信息来避免一致性方面的问题.MHA 还提供了 master 节点的在线切换功能,即按需切换 master/sla
-
构建双vip的高可用MySQL集群
目录 一. 项目描述: 二.项目环境: 二.项目步骤: 三.项目概念图: 四.部署zabbix监控系统 4.1 准备: 4.2 步骤: 五.项目心得: 一. 项目描述: 本项目的目的是: 构建一个高可用的能实现读写分离的高效的MySQL集群 确保业务的稳定,能沟通方便的监控整个集群 同时能批量的去部署和管理整个集群. 二.项目环境: 8台服务器(2G,2核),centos7.8 mysql5.7.30 mysqlrouter8.0.21 keepalived2.0.10 zabbix a
-
如何搭建 MySQL 高可用高性能集群
目录 MySQL NDB Cluster 是什么 搭建集群的前置工作 开始部署集群 部署管理服务器 部署数据服务器 部署 SQL 服务 所有集群服务部署完毕,我们来测试一下集群是否真的部署成功 数据库集群部署成功了,总结一下集群的注意事项 MySQL NDB Cluster 是什么 MySQL NDB Cluster 是 MySQL 的一个高可用.高冗余版本,适用于分布式计算环境. 文档链接 搭建集群的前置工作 至少准备 3 台服务器,一台作为管理服务器,两台作为数据服务器和 SQL 服务器,当
-
MySQL之高可用架构详解
目录 引言 MySQL高可用 一主一备: MySQL主从同步的几种模式: 总结 引言 "高可用"是互联网一个永恒的话题,先避开MySQL不谈,为了保证各种服务的高可用有几种常用的解决方案. 服务冗余:把服务部署多份,当某个节点不可用时,切换到其他节点.服务冗余对于无状态的服务是相对容易的. 服务备份:有些服务是无法同时存在多个运行时的,比如说:Nginx的反向代理,一些集群的leader节点.这时可以存在一个备份服务,处于随时待命状态. 自动切换:服务冗余之后,当某个节点不可用时,要做
-
java开发RocketMQ生产者高可用示例详解
目录 引言 1 消息 1.1 topic 1.2 Body 1.3 tag 1.4 key 1.5 延迟级别 2 生产者高可用 2.1 客户端保证生产者高可用 2.1.1 重试机制 2.1.2 客户端容错 2.2 Broker端保证生产者高可用 引言 前边两章说了点基础的,从这章开始,我们挖挖源码.看看RocketMQ是怎么工作的. 首先呢,这个生产者就是送孩子去码头的家长,孩子们呢,就是消息了. 我们看看消息孩子们都长啥样. 1 消息 public class Message implemen
-
keeplive+mysql+drbd高可用架构安装步骤
DRBD(DistributedReplicatedBlockDevice)是一个基于块设备级别在远程服务器直接同步和镜像数据的开源软件,类似于RAID1数据镜像,通常配合keepalived.heartbeat等HA软件来实现高可用性. DRBD是一种块设备,可以被用于高可用(HA)之中.它类似于一个网络RAID-1功能,当你将数据写入本地文件系统时,数据还将会被发送到网络中另一台主机上.以相同的形式记录在一个文件系统中. 本地(master)与远程主机(backup)的保证实时同步,如果本地
-
docker的高可用配置详解
Docker Compose Docker Compose 将所管理的容器分为三层,工程(project),服务(service)以及容器(contaienr).Docker Compose 运行的目录下的所有文件(docker-compose.yml, extends 文件或环境变量文件等)组成一个工程,若无特殊指定工程名即为当前目录名.一个工程当中可包含多个服务,每个服务中定义了容器运行的镜像,参数,依赖.一个服务当中可包括多个容器实例,Docker Compose 并没有解决负载均衡的问题
-
MySQL数据库实现高可用架构之MHA的实战
目录 一.MySQLMHA介绍 1.1什么是MHA? 1.2MHA的组成 1.3MHA的特点 二.MySQLMHA搭建 1.MHA架构部分 2.故障模拟部分 3.实验环境 三.实验步骤 1.关闭防火墙和SElinux 2.Master.Slave1.Slave2节点上安装mysql5.7 3.修改Master.Slave1.Slave2节点的主机名 4.修改Master.Slave1.Slave2节点的Mysql主配置文件/etc/my.cnf 5.在Master.Slave1.Slave2节点
-
MYSQL大量写入问题优化详解
摘要:大家提到Mysql的性能优化都是注重于优化sql以及索引来提升查询性能,大多数产品或者网站面临的更多的高并发数据读取问题.然而在大量写入数据场景该如何优化呢? 今天这里主要给大家介绍,在有大量写入的场景,进行优化的方案. 总的来说MYSQL数据库写入性能主要受限于数据库自身的配置,以及操作系统的性能,磁盘IO的性能.主要的优化手段包括以下几点: 1.调整数据库参数 (1) innodb_flush_log_at_trx_commit 默认为1,这是数据库的事务提交设置参数,可选值如下: 0
-
MYSQL中Truncate的用法详解
本文导读:删除表中的数据的方法有delete,truncate, 其中TRUNCATE TABLE用于删除表中的所有行,而不记录单个行删除操作.TRUNCATE TABLE 与没有 WHERE 子句的 DELETE 语句类似:但是,TRUNCATE TABLE 速度更快,使用的系统资源和事务日志资源更少.下面介绍SQL中Truncate的用法 当你不再需要该表时, 用 drop:当你仍要保留该表,但要删除所有记录时, 用 truncate:当你要删除部分记录时(always with a WHE
-
Tomcat核心组件及应用架构详解
Web 容器是什么? 让我们先来简单回顾一下 Web 技术的发展历史,可以帮助你理解 Web 容器的由来. 早期的 Web 应用主要用于浏览新闻等静态页面,HTTP 服务器(比如 Apache.Nginx)向浏览器返回静态 HTML,浏览器负责解析 HTML,将结果呈现给用户. 随着互联网的发展,我们已经不满足于仅仅浏览静态页面,还希望通过一些交互操作,来获取动态结果,因此也就需要一些扩展机制能够让 HTTP 服务器调用服务端程序. 于是 Sun 公司推出了 Servlet 技术.你可以把 Se
-
Mysql的并发参数调整详解
目录 查询缓存优化 概述 查询流程 查询缓存配置 查询缓存失效的情况 内存管理优化 内存优化原则 MyISAM内存优化 InnoDB内存优化 连接优化 max_connection back_log table_open_cache thread_cache_size innodb_lock_wait_timeout 日志 log_bin binlog_do_db binlog_ignore_db sync_binlog general_log=1 general_log_filefile_na