Pandas按周/月/年统计数据介绍
Pandas 按周、月、年、统计数据
介绍
将日期转为时间格式 并设置为索引
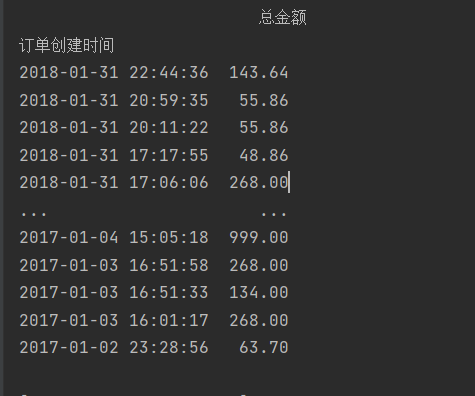
import pandas as pd
data=pd.read_excel('5\TB201812.xls',usecols=['订单创建时间','总金额'])
print(data)
data['订单创建时间']=pd.to_datetime(data['订单创建时间'])
data=data.set_index('订单创建时间')
print(data)
按周、月、季度、年统计数据
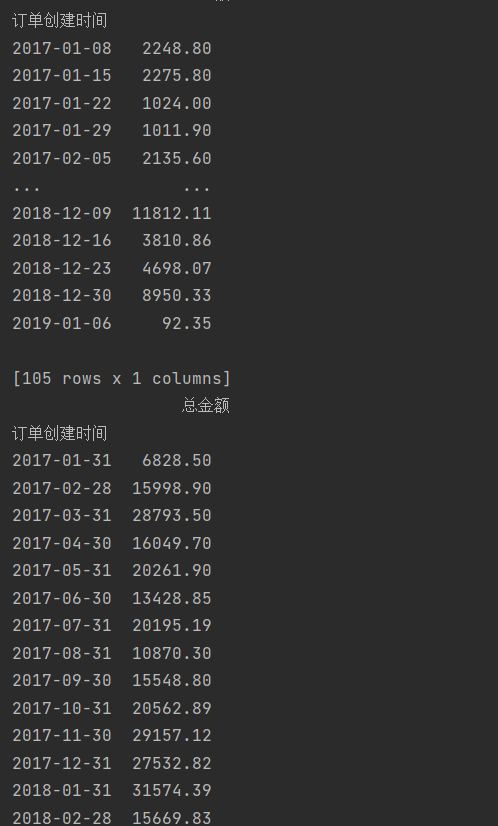
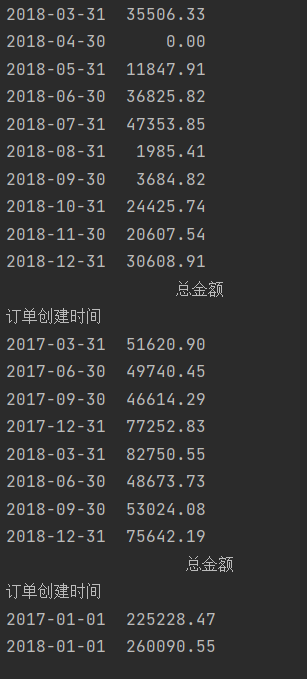
import pandas as pd
data=pd.read_excel('5\TB201812.xls',usecols=['订单创建时间','总金额'])
data['订单创建时间']=pd.to_datetime(data['订单创建时间'])
data=data.set_index('订单创建时间')
print(data.resample('w').sum())
print(data.resample('m').sum())
print(data.resample('Q').sum())
print(data.resample('AS').sum())
使用to_period()方法 优化
按月、季度和年显示数据(不统计数据)
import pandas as pd
data=pd.read_excel('5\TB201812.xls',usecols=['订单创建时间','总金额'])
data['订单创建时间']=pd.to_datetime(data['订单创建时间'])
data=data.set_index('订单创建时间')
print(data.resample('w').sum().to_period('w'))
print(data.resample('m').sum().to_period('m'))
print(data.resample('q').sum().to_period('q'))
print(data.resample('as').sum().to_period('a'))

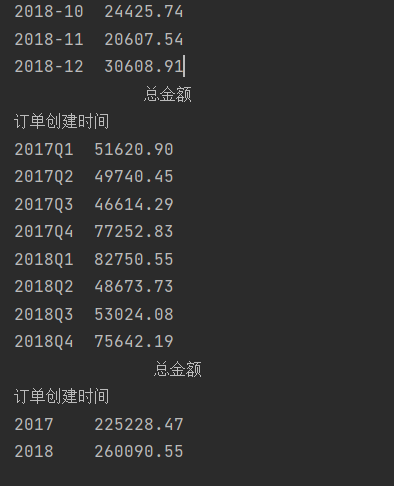
与之前相比 日期的显示方式发生了改变
到此这篇关于Pandas按周/月/年统计数据介绍的文章就介绍到这了,更多相关Pandas统计数据内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
详解python pandas 分组统计的方法
首先,看看本文所面向的应用场景:我们有一个数据集df,现在想统计数据中某一列每个元素的出现次数.这个在我们前面文章<如何画直方图>中已经介绍了方法,利用value_counts()就可以实现(具体回看文章) 但是,现在,我们考虑另外一个场景,我们假如要想统计其中两列元素出现次数呢?举个栗子: 在df数据集中,如果我们想统计A.B两列的元素的出现情况,也就是说,得到如下表. 从上面的最后一列可以看到,在A.B两列中,1 2 出现了2次,1 4 出现1次 ,1 6出现1次,2 3出现了2次, 2
-
基于Python数据分析之pandas统计分析
pandas模块为我们提供了非常多的描述性统计分析的指标函数,如总和.均值.最小值.最大值等,我们来具体看看这些函数: 1.随机生成三组数据 import numpy as np import pandas as pd np.random.seed(1234) d1 = pd.Series(2*np.random.normal(size = 100)+3) d2 = np.random.f(2,4,size = 100) d3 = np.random.randint(1,100,size = 1
-

Pandas按周/月/年统计数据介绍
Pandas 按周.月.年.统计数据 介绍 将日期转为时间格式 并设置为索引 import pandas as pd data=pd.read_excel('5\TB201812.xls',usecols=['订单创建时间','总金额']) print(data) data['订单创建时间']=pd.to_datetime(data['订单创建时间']) data=data.set_index('订单创建时间') print(data) 按周.月.季度.年统计数据 import pandas a
-
MySql按时,天,周,月进行数据统计
目录 前言 1. 时间取整方式 2. data_format方式 前言 最近遇到一个统计的需求场景,针对db中的数据,看一下每天的数据量情况,由于DB中时间字段采用的是int存的时间戳,所以最开始想到的是直接对时间进行按天取整,然后再Group统计数据: 除此之外,使用DATE_FORMAT函数来处理可能是更简洁的方法了,下面分别介绍下两种方式 1. 时间取整方式 假设现在有一个user表,其中create_time 为 int类型的时间戳,此时我们需要统计每天的新增用户数,第一种方式就是将cr
-
SQL按照日、周、月、年统计数据的方法分享
--按日 select sum(consume),day([date]) from consume_record where year([date]) = '2006' group by day([date]) --按周quarter select sum(consume),datename(week,[date]) from consume_record where year([date]) = '2006' group by datename(week,[date]) --按月 select
-
Pandas如何对Categorical类型字段数据统计实战案例
目录 一.Pandas如何对Categorical类型字段数据统计 1.1主要知识点 1.2创建 python 文件 1.3运行结果 二.Pandas如何从股票数据找出收盘价最低行 2.1主要知识点 2.2创建 python 文件 2.3运行结果 三.Pandas如何给股票数据新增年份和月份 3.1主要知识点 3.2创建 python 文件 3.3运行结果 四.Pandas如何获取表格的信息和基本数据统计 4.1主要知识点 4.2创建 python 文件 4.3运行结果 五.Pandas如何使用
-
yii 框架实现按天,月,年,自定义时间段统计数据的方法分析
本文实例讲述了yii 框架实现按天,月,年,自定义时间段统计数据的方法.分享给大家供大家参考,具体如下: 天(day): 格式Y-m-d 月(month):格式Y-m 年(year):格式Y 时间段(range): 格式Y-m-d 首先计算时间 天0-23小时 $rangeTime = range(0, 23); 月:1-月底 // $days = cal_days_in_month(CAL_GREGORIAN, $month, $year); $days = date("t",str
-
详解mysql 获取某个时间段每一天、每一个小时的统计数据
获取每一天的统计数据 做项目的时候需要统对项目日志做分析,其中有一个需求是获取某个给定的时间段内,每一天的日志数据,比如说要获取从2018-02-02 09:18:36到2018-03-05 23:18:36这个时间段内,统计出每一天的日志数据,一般情况下,看到这种需求都是考虑使用函数来搞定,直接上sql语句 SELECT DATE_FORMAT(trigger_time, '%Y-%m-%d') triggerDay, COUNT(id) triggerCount FROM `job_qrtz
-
mysql聚合统计数据查询缓慢的优化方法
写在前面 在我们日常操作数据库的时候,比如订单表.访问记录表.商品表的时候. 经常会处理计算数据列总和.数据行数等统计问题. 随着业务发展,这些表会越来越大,如果处理不当,查询统计的速度也会越来越慢,直到业务无法再容忍. 所以,我们需要先了解.思考这些场景知识点,在设计之初,便预留一些优化空间支撑业务发展. sql聚合函数 在mysql等数据中,都会支持聚合函数,方便我们计算数据. 常见的有以下方法 取平均值 AVG() 求和 SUM() 最大值 MAX() 最小值 MIN() 行数 COUNT
-
Python利用pandas计算多个CSV文件数据值的实例
功能:扫描当前目录下所有CSV文件并对其中文件进行统计,输出统计值到CSV文件 pip install pandas import pandas as pd import glob,os,sys input_path='./' output_fiel='pandas_union_concat.csv' all_files=glob.glob(os.path.join(input_path,'sales_*')) all_data_frames=[] for file in all_files:
-
MySQL按时间统计数据的方法总结
在做数据库的统计时,经常会需要根据年.月.日来统计数据,然后配合echarts来制作可视化效果. 数据库:MySQL 思路 按照时间维度进行统计的前提是需要数据库中有保留时间信息,建议是使用MySQL自带的datetime类型来记录时间. `timestamp` datetime DEFAULT NULL, 在MySQL中对于时间日期的处理的函数主要是DATE_FORMAT(date,format).可用的参数如下 格式 描述 %a 缩写星期名 %b 缩写月名 %c 月,数值 %D 带有英文前缀
-
Pandas使用stack和pivot实现数据透视的方法
目录 前言 一.经过统计得到多维度指标数据 二.使用unstack实现数据的二维透视 三.使用pivot简化透视 四.stack.unstack.pivot的语法 1.stack 2.unstack 3.pivot 总结 前言 笔者最近正在学习Pandas数据分析,将自己的学习笔记做成一套系列文章.本节主要记录Pandas中使用stack和pivot实现数据透视. 一.经过统计得到多维度指标数据 非常场景的统计场景,指定多个维度,计算聚合后的指标 实例:统计得到"电影评分数据集",每个