python利用Excel读取和存储测试数据完成接口自动化教程
http_request2.py用于发起http请求
#读取多条测试用例
#1、导入requests模块
import requests
#从 class_12_19.do_excel1导入read_data函数
from do_excel2 import read_data
from do_excel2 import write_data
from do_excel2 import count_case
#定义http请求函数
COOKIE=None
def http_request2(method,url,data):
if method=='get':
print('发起一个get请求')
result=requests.get(url,data,cookies=COOKIE)
else:
print('发起一个post请求')
result=requests.post(url,data,cookies=COOKIE)
return result #返回响应体
# return result.json() #返回响应结果:结果是字典类型:{'status': 1, 'code': '10001', 'data': None, 'msg': '登录成功'}
#从Excel读取到多条测试数据
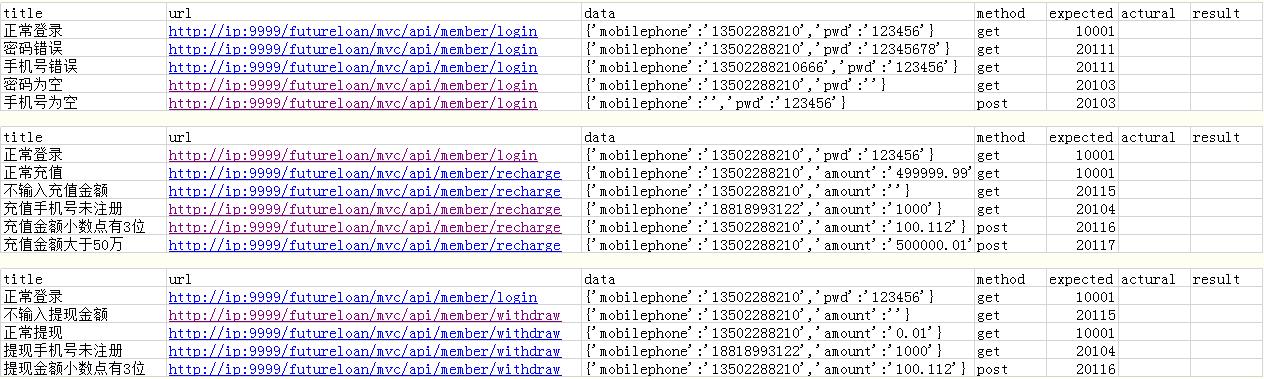
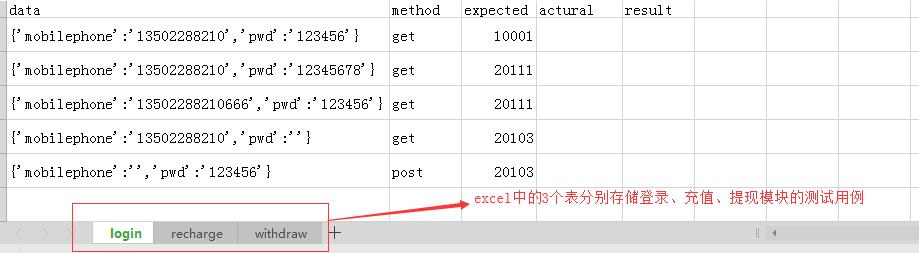
sheets=['login','recharge','withdraw']
for sheet1 in sheets:
max_row=count_case(sheet1)
print(max_row)
for case_id in range(1,max_row):
data=read_data(sheet1,case_id)
print('读取到第{}条测试用例:'.format(data[0]))
print('测试数据 ',data)
#print(type(data[2]))
#调用函数发起http请求
result=http_request2(data[4],data[2],eval(data[3]))
print('响应结果为 ',result.json())
if result.cookies:
COOKIE=result.cookies
#将测试实际结果写入excel
#write_data(case_id+1,6,result['code'])
write_data(sheet1,case_id+1,7,str(result.json()))
#对比测试结果和期望结果
if result.json()['code']==str(data[5]):
print('测试通过')
#将用例执行结果写入Excel
write_data(sheet1,case_id+1,8,'Pass')
else:
write_data(sheet1,case_id+1,8,'Fail')
print('测试失败')
do_excel2.py完成对excel中用例的读、写、统计
# 导入load_workbook
from openpyxl import load_workbook
#读取测试数据
#将excel中每一条测试用例读取到一个列表中
#读取一条测试用例——写到一个函数中
def read_data(sheet_name,case_id):
# 打开excel
workbook1=load_workbook('test_case2.xlsx')
# 定位表单(test_data)
sheet1=workbook1[sheet_name]
print(sheet1)
test_case=[] #用来存储每一行数据,也就是一条测试用例
test_case.append(sheet1.cell(case_id+1,1).value)
test_case.append(sheet1.cell(case_id+1,2).value)
test_case.append(sheet1.cell(case_id+1,3).value)
test_case.append(sheet1.cell(case_id+1,4).value)
test_case.append(sheet1.cell(case_id+1,5).value)
test_case.append(sheet1.cell(case_id+1,6).value)
return test_case #将读取到的用例返回
#调用函数读取第1条测试用例,并将返回结果保存在data中
# data=read_data(1)
# print(data)
#将测试结果写会excel
def write_data(sheet_name,row,col,value):
workbook1=load_workbook('test_case2.xlsx')
sheet=workbook1[sheet_name]
sheet.cell(row,col).value=value
workbook1.save('test_case2.xlsx')
#统计测试用例的行数
def count_case(sheet_name):
workbook1=load_workbook('test_case2.xlsx')
sheet=workbook1[sheet_name]
max_row=sheet.max_row #统计测试用例的行数
return max_row
test_case2.xlsx存储测试用例
补充知识:python用unittest+HTMLTestRunner+csv的框架测试并生成测试报告
直接贴代码:
import csv # 导入scv库,可以读取csv文件
from selenium import webdriver
import unittest
from time import sleep
import time
import os
import HTMLTestRunner
import codecs
import sys
dr = webdriver.Chrome()
class testLo(unittest.TestCase):
def setUp(self):
pass
def test_login(self):
'''登陆测试'''
path = 'F:\\Python_test\\'
# 要读取的scv文件路径
my_file = 'F:\\pythonproject\\interfaceTest\\testFile\\ss.csv'
# csv.reader()读取csv文件,
# Python3.X用open,Python2.X用file,'r'为读取
# open(file,'r')中'r'为读取权限,w为写入,还有rb,wd等涉及到编码的读写属性
#data = csv.reader(codecs.open(my_file, 'r', encoding='UTF-8',errors= 'ignore'))
with codecs.open(my_file, 'r', encoding='UTF-8',errors= 'ignore') as f:
data=csv.reader((line.replace('\x00','') for line in f))
# for循环将读取到的csv文件的内容一行行循环,这里定义了user变量(可自定义)
# user[0]表示csv文件的第一列,user[1]表示第二列,user[N]表示第N列
# for循环有个缺点,就是一旦遇到错误,循环就停止,所以用try,except保证循环执行完
print(my_file)
for user in data:
print(user)
dr.get('https://passport.cnblogs.com/user/signin')
# dr.find_element_by_id('input1').clear()
dr.find_element_by_id('input1').send_keys(user[0])
# dr.find_element_by_id('input2').clear()
dr.find_element_by_id('input2').send_keys(user[1])
dr.find_element_by_id('signin').click()
sleep(1)
print('\n' + '测试项:' + user[2])
dr.get_screenshot_as_file(path + user[3] + ".jpg")
try:
assert dr.find_element_by_id(user[4]).text
try:
error_message = dr.find_element_by_id(user[4]).text
self.assertEqual(error_message, user[5])
print('提示信息正确!预期值与实际值一致:')
print('预期值:' + user[5])
print('实际值:' + error_message)
except:
print('提示信息错误!预期值与实际值不符:')
print('预期值:' + user[5])
print('实际值:' + error_message)
except:
print('提示信息类型错误,请确认元素名称是否正确!')
def tearDown(self):
dr.refresh()
# 关闭浏览器
dr.quit()
if __name__ == "__main__":
# 定义脚本标题,加u为了防止中文乱码
report_title = u'登陆模块测试报告'
# 定义脚本内容,加u为了防止中文乱码
desc = u'登陆模块测试报告详情:'
# 定义date为日期,time为时间
date = time.strftime("%Y%m%d")
time = time.strftime("%Y%m%d%H%M%S")
# 定义path为文件路径,目录级别,可根据实际情况自定义修改
path = 'F:\\Python_test\\' + date + "\\login\\" + time + "\\"
# 定义报告文件路径和名字,路径为前面定义的path,名字为report(可自定义),格式为.html
report_path = path + "report.html"
# 判断是否定义的路径目录存在,不能存在则创建
if not os.path.exists(path):
os.makedirs(path)
else:
pass
# 定义一个测试容器
testsuite = unittest.TestSuite()
# 将测试用例添加到容器
testsuite.addTest(testLo("test_login"))
# 将运行结果保存到report,名字为定义的路径和文件名,运行脚本
report = open(report_path, 'wb')
#with open(report_path, 'wb') as report:
runner = HTMLTestRunner.HTMLTestRunner(stream=report, title=report_title, description=desc)
runner.run(testsuite)
# 关闭report,脚本结束
report.close()
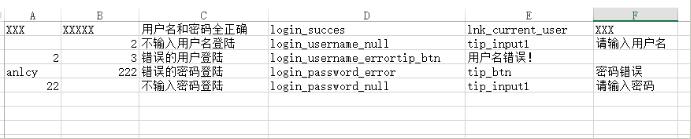
csv文件格式:
备注:
使用python处理中文csv文件,并让execl正确显示中文(避免乱码)设施编码格式为:utf_8_sig,示例:
'''''
将结果导出到result.csv中,以UTF_8 with BOM编码(微软产品能正确识别UTF_8 with BOM存储的中文文件)存储
'''
#data.to_csv('result_utf8_no_bom.csv',encoding='utf_8')#导出的结果不能别excel正确识别
data.to_csv('result_utf8_with_bom.csv',encoding='utf_8_sig')
以上这篇python利用Excel读取和存储测试数据完成接口自动化教程就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-

python http接口自动化脚本详解
今天给大家分享一个简单的python脚本,使用python进行http的接口测试,脚本很简单,逻辑是:读取excel写好的测试用例,然后根据excel中的用例内容进行调用,判断预期结果中的返回值是否和返回报文中的值一致,如果不一致则根据用例标题把bug提交到bug管理系统,这里使用的bug管理系统是bugfree. 实现步骤: 1.读取excel,保存测试用例中的内容: 2.根据excel中的请求url和参数拼接请求报文,调用接口,并保存返回报文: 3.读取返回报文,和预期结果对比,不一致的往b
-
Python3+Requests+Excel完整接口自动化测试框架的实现
框架整体使用Python3+Requests+Excel:包含对实时token的获取 1.------base -------runmethond.py runmethond:对不同的请求方式进行封装 import json import requests requests.packages.urllib3.disable_warnings() class RunMethod: def post_main(self, url, data, header=None): res = None if
-
PYTHON如何读取和写入EXCEL里面的数据
好久没写了,今天来说说python读取excel的常见方法.首先需要用到xlrd模块,pip install xlrd 安装模块. 首先打开excel文件: xl = xlrd.open_workbook(r'D:\file\data.xlsx') 传文件路径 通过索引获取要操作的工作表 table = xl.sheets()[0] 有些人不知道啥是工作表,下图这个: 获取第一行的内容,索引从0开始 row = table.row_values(0) 获取第一列的整列的内容 col = tabl
-
利用Python如何实现数据驱动的接口自动化测试
前言 大家在接口测试的过程中,很多时候会用到对CSV的读取操作,本文主要说明Python3对CSV的写入和读取.下面话不多说了,来一起看看详细的介绍吧. 1.需求 某API,GET方法,token,mobile,email三个参数 token为必填项 mobile,email 必填其中1项 mobile为手机号,email为email格式 2.方案 针对上面的API,在做接口测试时,需要的测试用例动辄会多达10+, 这个时候采用数据驱动的方式将共性的内容写入配置文件或许会更合适. 这里考虑把AP
-
python利用Excel读取和存储测试数据完成接口自动化教程
http_request2.py用于发起http请求 #读取多条测试用例 #1.导入requests模块 import requests #从 class_12_19.do_excel1导入read_data函数 from do_excel2 import read_data from do_excel2 import write_data from do_excel2 import count_case #定义http请求函数 COOKIE=None def http_request2(met
-
Python利用VideoCapture读取视频或摄像头并进行保存
目录 一.语法:cap = cv2.VideoCapture(0) 二.语法:cap.isOpened() 三.语法:ret,frame = cap.read() 四.语法:key = cv2.waitKey(1) 五.读取摄像头并保存为视频代码演示 六.读取视频并按帧进行保存代码演示: 一.语法:cap = cv2.VideoCapture(0) 说明:参数0表示默认为笔记本的内置第一个摄像头,如果需要读取已有的视频则参数改为视频所在路径路径,例如:cap=cv2.VideoCapture('
-
python 利用openpyxl读取Excel表格中指定的行或列教程
Worksheet 对象的 rows 属性和 columns 属性得到的是一 Generator 对象,不能用中括号取索引. 可先用列表推导式生成包含每一列中所有单元格的元组的列表,在对列表取索引. Worksheet 的 rows 属性亦可用相同的方法处理. 补充:python之表格数据读取 python 操作excel主要用到xlrd,xlwt这两个库,xlrd,是读取excel表,xlwt是写入表格 1.打开表格 table = xlrd.open("path_to_your_excel&
-
python利用faker库批量生成测试数据
安装 pip install faker 使用 简单使用 本库可生成姓名.地址.电话.邮箱.公司等等一系列数据.首先导入库,实例化: from faker import Faker fake = Faker() 先看看正面生成一个人的姓名地址吧: for _ in range(10): print(fake.name()) rs. Elizabeth Carter MD Mark Obrien Madeline Oliver Ruth Newman Lori Bennett Victor Nol
-
在Python的框架中为MySQL实现restful接口的教程
最近在做游戏服务分层的时候,一直想把mysql的访问独立成一个单独的服务DBGate,原因如下: 请求收拢到DBGate,可以使DBGate变为无状态的,方便横向扩展 当请求量或者存储量变大时,mysql需要做分库分表,DBGate可以内部直接处理,外界无感知 通过restful限制对数据请求的形式,仅支持简单的get/post/patch/put 进行增删改查,并不支持复杂查询.这个也是和游戏业务的特性有关,如果网站等需要复杂查询的业务,对此并不适合 DBGate使用多进程模式,方便控制与my
-
如何在Python对Excel进行读取
在python自动化中,经常会遇到对数据文件的操作,比如添加多名员工,但是直接将员工数据写在python文件中,不但工作量大,要是以后再次遇到类似批量数据操作还会写在python文件中吗? 应对这一问题,可以将数据写excel文件,针对excel 文件进行操作,完美解决. 本文仅介绍python对excel的操作 安装xlrd 库 xlrd库 官方地址:https://pypi.org/project/xlrd/ pip install xlrd 笔者在安装时使用了 pip3 install x
-
Python利用pdfplumber实现读取PDF写入Excel
目录 一.Python操作PDF 13大库对比 二.pdfplumber模块 1.安装 2. 加载PDF 3. pdfplumber.PDF类 4. pdfplumber.Page类 三.实战操作 1. 提取单个PDF全部页数 2. 批量提取多个PDF文件 一.Python操作PDF 13大库对比 PDF(Portable Document Format)是一种便携文档格式,便于跨操作系统传播文档.PDF文档遵循标准格式,因此存在很多可以操作PDF文档的工具,Python自然也不例外. Pyth
-
Python利用pandas处理Excel数据的应用详解
最近迷上了高效处理数据的pandas,其实这个是用来做数据分析的,如果你是做大数据分析和测试的,那么这个是非常的有用的!!但是其实我们平时在做自动化测试的时候,如果涉及到数据的读取和存储,那么而利用pandas就会非常高效,基本上3行代码可以搞定你20行代码的操作!该教程仅仅限于结合柠檬班的全栈自动化测试课程来讲解下pandas在项目中的应用,这仅仅只是冰山一角,希望大家可以踊跃的去尝试和探索! 一.安装环境: 1:pandas依赖处理Excel的xlrd模块,所以我们需要提前安装这个,安装命令
-
利用python在excel中画图的实现方法
一.前言 以前大学时候,学EXCEL看到N多大神利用excel画图,觉得很不可思议.今个学了一个来月python,膨胀了就想用excel画图.当然,其实用画图这个词不甚严谨,实际上是利用opencv遍历每一个像素的rgb值,再将其转化为16进制,最后调用openpyxl进行填充即可. 1.1.实现效果 效果如下图 1.2.需要用到的库的安装 需要用到库如下: import cv2 #导入OpenCV库 import xlsxwriter #利用这个调整行高列宽 import openpyxl #
-
python 使用openpyxl读取excel数据
openpyxl介绍 openpyxl是一个开源项目,它是一个用于读取/写入Excel 2010文档(如xlsx .xlsm .xltx .xltm文件 )的Python库,如果要处理更早格式的Excel文档(xls),需要用到其它库(如:xlrd.xlwt等),这是openpyxl比较其他模块的不足之处.openpyxl是一款比较综合的工具,不仅能够同时读取和修改Excel文档,而且可以对Excel文件内单元格进行详细设置,包括单元格样式等内容,甚至还支持图表插入.打印设置等内容. p