基于python爬取梨视频实现过程解析
目标网址:梨视频
然后我们找到科技这一页:https://www.pearvideo.com/category_8。其实你要哪一页都行,你喜欢就行。嘿嘿…
这是动态网站,所以咱们直奔network 然后去到XHR:
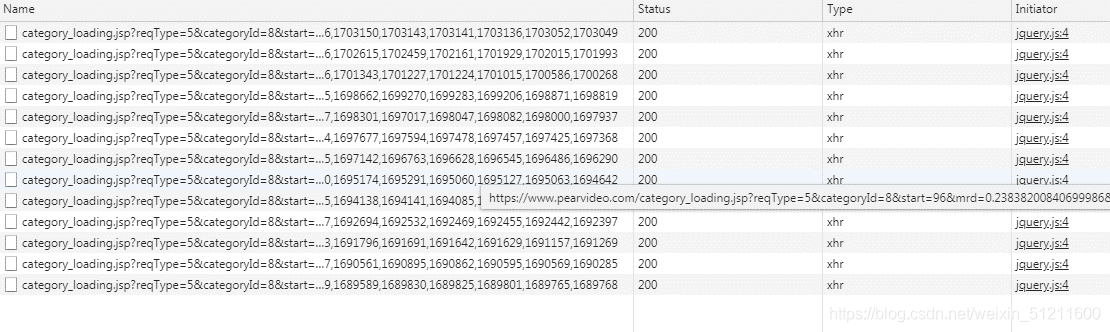
找规律,这个应该不难,我就直接贴网址上来咯,想要锻炼的可以找找看哈:
https://www.pearvideo.com/category_loading.jsp?reqType=5&categoryId=8&start=0
这个就是我们要找的目标网址啦,后面的0就代表页数,让打开这个网页发现是静态网页,这最好搞啦,直接上:

代码如下:
import requests
import parsel,re
import os
target = "https://www.pearvideo.com/videoStatus.jsp?contId="
url = "https://www.pearvideo.com/category_loading.jsp?reqType=5&categoryId=9&start=0"
res = requests.get(url)
res.encoding="utf-8"
html = parsel.Selector(res.text)
lists = html.xpath('/html/body/li/div/a/@href').getall()
for each in lists:
print("https://www.pearvideo.com/"+each)
output;
https://www.pearvideo.com/video_1703486
https://www.pearvideo.com/video_1703189
https://www.pearvideo.com/video_1703161
https://www.pearvideo.com/video_1702880
https://www.pearvideo.com/video_1702773
...
顺利拿到,然后进入播放页面,却发现找不到MP4视频,怎么办?经过我一番努力(扯掉了几十根头发后)发现,它在另外一个网址里面
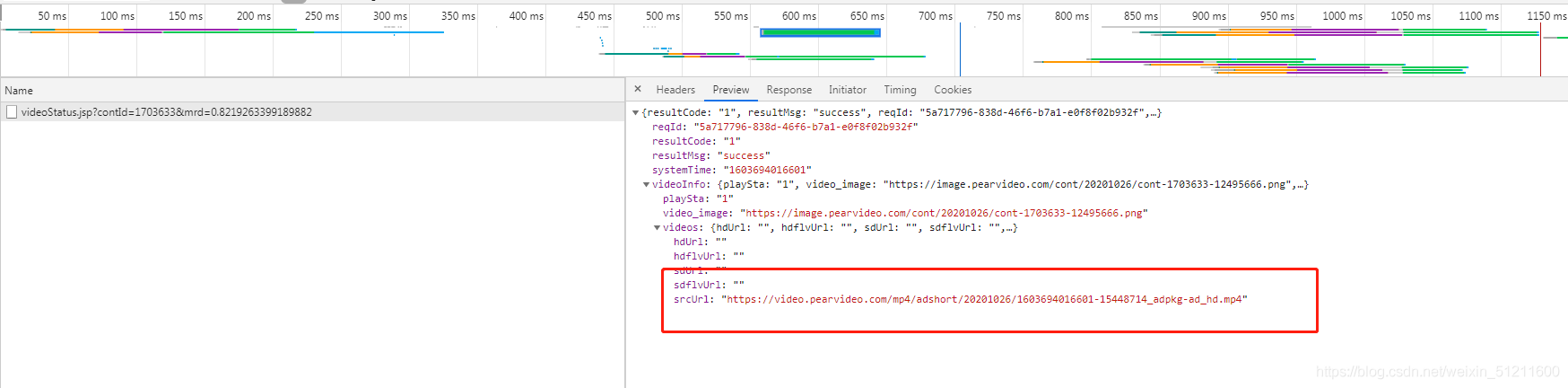
咋办?当然要想办法把这个网址搞到手啦,仔细分析下,发现这个网址非常陌生呀,唯一稍微熟悉点的就是那串数字了,前面我们拿到播放页的网址后面那串数字和这个对比,完全是一模一样的,这样的话那就好搞了,咱们直接用拼接的方式把它接上去就可以了,看代码:
for each in lists:
url_num = each.replace('video_',"")
urls = target+url_num
print(urls)
``
```python
output:
https://www.pearvideo.com/videoStatus.jsp?contId=1703486
https://www.pearvideo.com/videoStatus.jsp?contId=1703189
https://www.pearvideo.com/videoStatus.jsp?contId=1703161
https://www.pearvideo.com/videoStatus.jsp?contId=1702880
https://www.pearvideo.com/videoStatus.jsp?contId=1702773
https://www.pearvideo.com/videoStatus.jsp?contId=1702633
...
出来了,好像稍微有点不一样,后面那啥&mrd=***************** 没有,怎么办?没有就不要呗,看过我发的百度图片那篇的朋友都懂,网址里面有些东西是不需要的,纯粹是搞咱们这些玩爬虫的,恶心咱们。不过没办法,毕竟是咱们要去爬人家的数据的。
网址问题解决了,但是点进去一看,发现这东东:

恩,很明显,是遇到反爬机制了,这个好搞,要什么给什么就行,代码如下:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.111 Safari/537.36',
'Referer': 'https://www.pearvideo.com/video_'+ str(url_num)
}
html = requests.get(urls,headers=headers).text
print(html)
搞定!!
最后我们看一下MP4能不能播放:
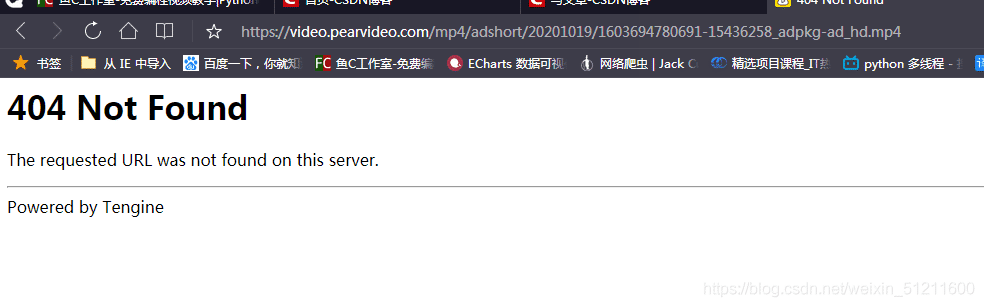
西八!404!!恩,这里就稍微有点麻烦了,还得找数据,把里面的时间戳改成 ‘cont-数字‘,感觉写了好多,手都有点累了,我就直接上代码了:
import requests
import parsel,re
import os
target = "https://www.pearvideo.com/videoStatus.jsp?contId="
url = "https://www.pearvideo.com/category_loading.jsp?reqType=5&categoryId=9&start=0"
res = requests.get(url)
res.encoding="utf-8"
html = parsel.Selector(res.text)
lists = html.xpath('/html/body/li/div/a/@href').getall()
# print(lists[2:])
# 提取视频后面的数字,数字是最重要的,需要传给 Referer 和 urls
for each in lists:
url_num = each.replace('video_',"")
urls = target+url_num
# print(urls)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.111 Safari/537.36',
'Referer': 'https://www.pearvideo.com/video_'+ str(url_num)
}
html = requests.get(urls,headers=headers).text
cont = 'cont-' + str(url_num)
# 提取 mp4 视频
srcUrl = re.findall(f'"srcUrl":"(.*?)"',html)[0]
# 替换视频里面的时间戳,改为可以真正播放的数据
new_url = srcUrl.replace(srcUrl.split("-")[0].split("/")[-1],cont)
print(new_url)
# 使用视频后缀当视频名称
filename = srcUrl.split("/")[-1]
# 保存到本地
with open("./images/"+filename,"wb") as f:
f.write(requests.get(new_url).content)

以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
Python爬取视频(其实是一篇福利)过程解析
窗外下着小雨,作为单身程序员的我逛着逛着发现一篇好东西,来自知乎 你都用 Python 来做什么?的第一个高亮答案. 到上面去看了看,地址都是明文的,得,赶紧开始吧. 下载流式文件,requests库中请求的stream设为True就可以啦,文档在此. 先找一个视频地址试验一下: # -*- coding: utf-8 -*- import requests def download_file(url, path): with requests.get(url, stream=True) as
-
Python爬取腾讯视频评论的思路详解
一.前提条件 安装了Fiddler了(用于抓包分析) 谷歌或火狐浏览器 如果是谷歌浏览器,还需要给谷歌浏览器安装一个SwitchyOmega插件,用于代理服务器 有Python的编译环境,一般选择Python3.0及以上 声明:本次爬取腾讯视频里 <最美公里>纪录片的评论.本次爬取使用的浏览器是谷歌浏览器 二.分析思路 1.分析评论页面 根据上图,我们可以知道:评论使用了Ajax异步刷新技术.这样就不能使用以前分析当前页面找出规律的手段了.因为展示的页面只有部分评论,还有大量的评论没有被刷新出
-
Python如何实现爬取B站视频
5月3日晚,央视在<新闻联播>前播放了B站青年宣言片<后浪>,这是B站首次登陆央视黄金时段,今天在朋友圈陆续看到相关的视频.最早用B站的同学都知道,B站是和A站以异曲同工的鬼畜视频及动漫,进入到大众视野的非主流视频网站.哔哩哔哩现为国内领先的年轻人娱乐.文化社区,该网站于2009年6月26日创建,被粉丝们亲切的称为"B站". B站之所以火,是因为趣味与知识并存.它是一个重度宅腐二次元集结地.B站包含动漫.漫画.游戏,也有很多由繁到简.五花八门的视频,很多冷门的软
-
python爬取m3u8连接的视频
本文为大家分享了python爬取m3u8连接的视频方法,供大家参考,具体内容如下 要求:输入m3u8所在url,且ts视频与其在同一路径下 #!/usr/bin/env/python #_*_coding:utf-8_*_ #Data:17-10-08 #Auther:苏莫 #Link:http://blog.csdn.net/lingluofengzang #PythonVersion:python2.7 #filename:download_movie.py import os import
-
Python如何爬取b站热门视频并导入Excel
代码如下 #encoding:utf-8 import requests from lxml import etree import xlwt import os # 爬取b站热门视频信息 def spider(): video_list = [] url = "https://www.bilibili.com/ranking?spm_id_from=333.851.b_7072696d61727950616765546162.3" html = requests.get(url, h
-

Python爬虫 批量爬取下载抖音视频代码实例
这篇文章主要为大家详细介绍了python批量爬取下载抖音视频,具有一定的参考价值,感兴趣的小伙伴们可以参考一下 项目源码展示: ''' 在学习过程中有什么不懂得可以加我的 python学习交流扣扣qun,934109170 群里有不错的学习教程.开发工具与电子书籍. 与你分享python企业当下人才需求及怎么从零基础学习好python,和学习什么内容. ''' # -*- coding:utf-8 -*- from contextlib import closing import request
-
python 爬取B站原视频的实例代码
B站原视频爬取,我就不多说直接上代码.直接运行就好. B站是把视频和音频分开.要把2个合并起来使用.这个需要分析才能看出来.然后就是登陆这块是比较难的. import os import re import argparse import subprocess import prettytable from DecryptLogin import login '''B站类''' class Bilibili(): def __init__(self, username, password, **
-
以视频爬取实例讲解Python爬虫神器Beautiful Soup用法
1.安装BeautifulSoup4 easy_install安装方式,easy_install需要提前安装 easy_install beautifulsoup4 pip安装方式,pip也需要提前安装.此外PyPi中还有一个名字是 BeautifulSoup 的包,那是 Beautiful Soup3 的发布版本.在这里不建议安装. pip install beautifulsoup4 Debain或ubuntu安装方式 apt-get install Python-bs4 你也可以通过源码安
-
基于python爬取梨视频实现过程解析
目标网址:梨视频 然后我们找到科技这一页:https://www.pearvideo.com/category_8.其实你要哪一页都行,你喜欢就行.嘿嘿- 这是动态网站,所以咱们直奔network 然后去到XHR: 找规律,这个应该不难,我就直接贴网址上来咯,想要锻炼的可以找找看哈: https://www.pearvideo.com/category_loading.jsp?reqType=5&categoryId=8&start=0 这个就是我们要找的目标网址啦,后面的0就代表页数,让
-
Python爬取梨视频的示例
爬取流程(美食区最热标签下的三个视频) 在首页获取视频的编号和名字 拼接成正确的url 保存视频 思路 1.从网页中获取视频的url 发现视频的url在id为"JprismPlayer"的div标签下的video标签src属性中,xpath解析网页 video_url = tree.xpath("//div[@id='JprismPlayer']/video/@src") 但得到的返回值为空,也就是说这个video标签在原网页中并不存在,很可能是动态加载出来的 2.
-
python爬取梨视频生活板块最热视频
完整代码如下: import requests from lxml import etree import random import os from multiprocessing.dummy import Pool if not os.path.exists('./视频'): os.mkdir('./视频') urls=[] url='https://www.pearvideo.com/category_5' headers={'user-agent':'Mozilla/5.0 (Windo
-
Python爬取豆瓣数据实现过程解析
代码如下 from bs4 import BeautifulSoup #网页解析,获取数据 import sys #正则表达式,进行文字匹配 import re import urllib.request,urllib.error #指定url,获取网页数据 import xlwt #使用表格 import sqlite3 import lxml 以上是引用的库,引用库的方法很简单,直接上图: 上面第一步算有了,下面分模块来,步骤算第二步来: 这个放在开头 def main(): baseurl
-
基于python爬取有道翻译过程图解
1.准备工作 先来到有道在线翻译的界面http://fanyi.youdao.com/ F12 审查元素 ->选Network一栏,然后F5刷新 (如果看不到Method一栏,右键Name栏,选中Method) 输入文字自动翻译后发现Method一栏有GET还有POST:GET是指从服务器请求和获得数据,POST是向指定服务器提交被处理的数据. 随便打开一个POST,找到preview可以看到我们输入的"我爱你一生一世"数据,可以证明post的提交数据的 下面分析一下Header
-
python爬取youtube视频的示例代码
这几天正在追剧,原名<大秦帝国之天下>的<大秦赋>,看着看着又想把前几部刷一遍了,但第一部<裂变>自己没有高清资源,搜了一波发现youtube上有个48集版的高清资源,有删减就有删减吧,就想着写个脚本批量下载一下,记录一下过程,主要是youtube1080p及以上的分辨率做了音视频分离,下载后需要用ffmpeg做一次音视频融合.参考了pytube模块. 1.下载音视频数据 pytube可以通过pip安装 $pip install pytube from pytube
-
Python爬取豆瓣视频信息代码实例
这篇文章主要介绍了Python爬取豆瓣视频信息代码实例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 这里是爬取豆瓣视频信息,用pyquery库(jquery的python库). 一:代码 from urllib.request import quotefrom pyquery import PyQuery as pqimport requestsimport pandas as pddef get_text_page (movie_name)
-
Python scrapy增量爬取实例及实现过程解析
这篇文章主要介绍了Python scrapy增量爬取实例及实现过程解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 开始接触爬虫的时候还是初学Python的那会,用的还是request.bs4.pandas,再后面接触scrapy做个一两个爬虫,觉得还是框架好,可惜都没有记录都忘记了,现在做推荐系统需要爬取一定的文章,所以又把scrapy捡起来.趁着这次机会做一个记录. 目录如下: 环境 本地窗口调试命令 工程目录 xpath选择器 一个简单
-
基于Python爬取51cto博客页面信息过程解析
介绍 提到爬虫,互联网的朋友应该都不陌生,现在使用Python爬取网站数据是非常常见的手段,好多朋友都是爬取豆瓣信息为案例,我不想重复,就使用了爬取51cto博客网站信息为案例,这里以我的博客页面为教程,编写的Python代码! 实验环境 1.安装Python 3.7 2.安装requests, bs4模块 实验步骤 1.安装Python3.7环境 2.安装requests,bs4 模块 打开cmd,输入:pip install requests -i https://pypi.tuna.tsi
-
基于Python爬取爱奇艺资源过程解析
像iqiyi这种视频网站,现在下载视频都需要下载相应的客户端.那么如何不用下载客户端,直接下载非vip视频? 选择你想要爬取的内容 该安装的程序以及运行环境都配置好 下面这段代码就是我在爱奇艺里搜素"英文名",然后出来的视频,共有20页,那么我们便从第一页开始,解析网页,然后分析 分析每一页网址,找出规律就可以直接得到所有页面 然后根据每一个视频的URL的标签,如'class' 'div' 'href'......通过bs4库进行爬取 而其他的信息则是直接循环所爬取到的URL,在每一个