深入解析opencv骨架提取的算法步骤
目录
- 前言
- 一.算法步骤
- 1.算法步骤
- 2.分析
- 二.代码实现
- 1.预处理
- 2. 骨架提取实现
前言
个人感觉骨架提取提取的就是开运算过程的不可逆。
一.算法步骤
1.算法步骤
首先上一下比较官方的算法步骤:
1.获得原图像的首地址及图像的宽和高,并设置循环标志1
2.用结构元素腐蚀原图像,并保存腐蚀结果
3.设置循环标志为0,如果腐蚀结果中有一个点为255,即原图像尚未被完全腐蚀成空集,则将循环标志设为1.
4.用结构元素对腐蚀后的图像进行开运算(消除小的白色区域),并求取腐蚀运算与开运算的差(得到消除的白色区域)
5.用[4]中求得的结果与之前求得的骨架进行并集运算,以获得本次循环求得的骨架
6.把本次循环中保存的腐蚀结果赋值给原图像
7.重复步骤[2]-[6],直到将原图像腐蚀成空集为止。
最终求得的骨架就是结果。
2.分析
作者的理解是这样的:
输入:img(二值图)
输出:out(和img一样shape的图像,初始化是全0)
while img中有像素值为255(在这个循环里面,一直腐蚀我们的二值图,直到全部为黑色):
腐蚀img图像
对img开运算
img2=开运算前的图像减去开运算后的图像
out+=img2
输出out
首先说一下开运算,就是对图像先做腐蚀再做膨胀。上面一个核心点就是这一步(img2=开运算前的图像减去开运算后的图像),在这里为什么说个人感觉骨架提取提取的就是开运算过程的不可逆呢?我们对这个开运算过程分析一下:
1.假如开运算后的图像和开运算前的图像不一样,比如下面这张图片:
可以看到这张图片中白色的大部分都比较细小,我们对这张图片做开运算的时候,我们先腐蚀,很容易就让一部分的白色的部分消失掉,那么这个白色的部分消失掉之后对腐蚀后的图片做膨胀消失的白色部分是膨胀不回来的。这些消失的部分就是开运算过程中的不可逆的部分了。
然后我们在后面(img2=开运算前的图像减去开运算后的图像),这一步当中就是得到了开运算中消失的那些白色部分了,这一部分就是开运算过程中的不可逆的部分,然后将它叠加到out上。
然后我们通过对图像不断的腐蚀,开运算,得到了所有这些图像中在开运算中不可逆的部分,就得到了我们的骨架了。
2.假如开运算后的图像和开运算前的图像不一样,那这样的话我们在这一步(img2=开运算前的图像减去开运算后的图像)得到img2中的每一个元素就为0了,那在后面out+=img2这一步的时候就out相当于不变,进入下一步循环在继续把白色部分腐蚀地更小,直到得到开运算中出现了不可逆地部分再叠加到out上。
所以粗暴地来说,骨架提取就是对我们地前景区域,不断地腐蚀,细化前景,直到将前景压缩到细地不能再细了。我们的骨架提取提取的就是这一部分。
二.代码实现
1.预处理
这里我们的图片是以灰度图片方式读取进来的,然后需要阈值处理转换到二值图。
然后我们的图片可能会有一些其他的较大的噪声的影响,我们首先对图像先进行腐蚀操作,手动过滤掉一些滤波可能无法过滤的较大噪声。
'''
用于挑选一个好的二值图
'''
import cv2
import numpy as np
import os
def refine(img_path):
img = cv2.imread(img_path, cv2.IMREAD_GRAYSCALE)
# thresh, img = cv2.threshold(img, 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU)
thresh, img = cv2.threshold(img, 50, 255, cv2.THRESH_BINARY)
h, w = img.shape[0:2]
#前景背景反转
for i in range(h):
for j in range(w):
if img[i, j] == 255:
img[i, j] = 0
else:
img[i, j] = 255
cv2.namedWindow("binary", 0)
cv2.resizeWindow("binary", 640, 480)
cv2.imshow('binary', img)
dst = img.copy()
num_erode = 0
while (True):
if np.sum(dst) == 0:
break
kernel = cv2.getStructuringElement(cv2.MORPH_CROSS, (3, 3))
dst = cv2.erode(dst, kernel)
cv2.namedWindow("z", 0)
cv2.resizeWindow("z", 640, 480)
cv2.imshow('z', dst)
c = cv2.waitKey(0)
if c == ord("q"):
print("保存")
cv2.imwrite("./refine.png", dst)
break
num_erode = num_erode + 1
if __name__ == '__main__':
refine("input.png")
在这里需要注意的是我们对图像进行二值化可能会将我们的背景和前景反转,在这里我们需要反转回来。否则的话把反转的代码注释掉即可。
我的原图如下:

然后经过腐蚀的图片如下:

2. 骨架提取实现
然后下面就是骨架提取的代码了:
'''
骨架提取
'''
import cv2
import numpy as np
#由于我们经过之前的代码转换到了二值图,所以这里不需要转换
img = cv2.imread('refine.png', cv2.IMREAD_GRAYSCALE)
dst = img.copy()
skeleton = np.zeros(dst.shape, np.uint8)
while (True):
if np.sum(dst) == 0:
break
kernel = cv2.getStructuringElement(cv2.MORPH_CROSS, (7, 7))
dst = cv2.erode(dst, kernel, None, None, 1)
open_dst = cv2.morphologyEx(dst, cv2.MORPH_OPEN, kernel)
result = dst - open_dst
skeleton = skeleton + result
cv2.waitKey(1)
cv2.namedWindow("result",0)
cv2.resizeWindow("result",640,480)
cv2.imshow('result', skeleton)
cv2.imwrite("output.png",skeleton)
cv2.waitKey(0)
cv2.destroyAllWindows()
在这里我们可以通过开运算的结果元大小来稍微调整一下提取的骨架粗细。
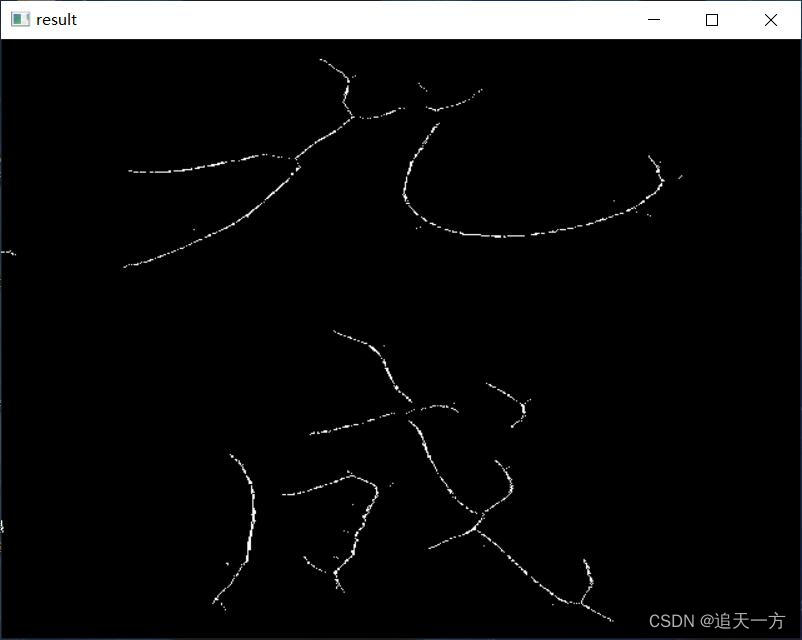
77开运算结构元提取的骨架如下:

55开运算结构元提取的骨架如下:
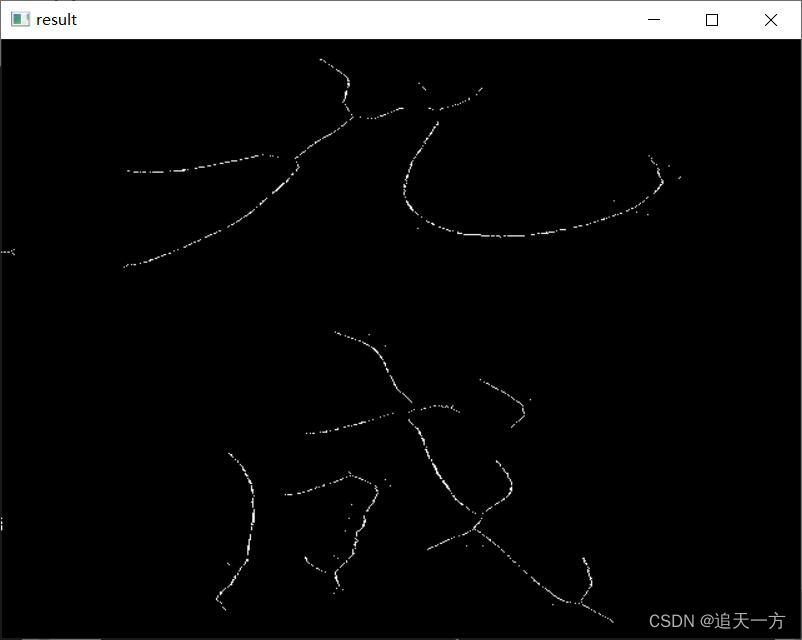
到此这篇关于深入解析opencv骨架提取的算法步骤的文章就介绍到这了,更多相关opencv骨架提取内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

基于Python的OpenCV骨架化图像并显示(skeletonize)
1. 效果图 自己画一张图,原图 VS 骨架效果图如下: opencv logo原图 VS 骨架化效果图如下: 2. 源码 # 图像骨架化~ import cv2 import imutils import numpy as np img = np.zeros((390, 390, 3), dtype="uint8") cv2.putText(img, "Beautiful Girl.....", (50, 190), cv2.FONT_HERSHEY_SIMPLE
-
深入解析opencv骨架提取的算法步骤
目录 前言 一.算法步骤 1.算法步骤 2.分析 二.代码实现 1.预处理 2. 骨架提取实现 前言 个人感觉骨架提取提取的就是开运算过程的不可逆. 一.算法步骤 1.算法步骤 首先上一下比较官方的算法步骤: 1.获得原图像的首地址及图像的宽和高,并设置循环标志1 2.用结构元素腐蚀原图像,并保存腐蚀结果 3.设置循环标志为0,如果腐蚀结果中有一个点为255,即原图像尚未被完全腐蚀成空集,则将循环标志设为1. 4.用结构元素对腐蚀后的图像进行开运算(消除小的白色区域),并求取腐蚀运算与开运算的差
-
python数字图像处理之骨架提取与分水岭算法
骨架提取与分水岭算法也属于形态学处理范畴,都放在morphology子模块内. 1.骨架提取 骨架提取,也叫二值图像细化.这种算法能将一个连通区域细化成一个像素的宽度,用于特征提取和目标拓扑表示. morphology子模块提供了两个函数用于骨架提取,分别是Skeletonize()函数和medial_axis()函数.我们先来看Skeletonize()函数. 格式为:skimage.morphology.skeletonize(image) 输入和输出都是一幅二值图像. 例1: from s
-
OpenCV实现无缝克隆算法的步骤详解
目录 一.概述 二.函数原型 三.OpenCV源码 1.源码路径 2.源码代码 四.效果图像示例 一.概述 借助无缝克隆算法,您可以从一张图像中复制一个对象,然后将其粘贴到另一张图像中,从而形成一个看起来无缝且自然的构图. 二.函数原型 给定一个原始彩色图像,可以无缝混合该图像的两个不同颜色版本. void cv::colorChange (InputArray src, InputArray mask, OutputArray dst, float red_mul=1.0f, float gr
-
Python+OpenCV实现分水岭分割算法的示例代码
目录 前言 1.使用分水岭算法进行分割 2.Watershed与random walker分割对比 前言 分水岭算法是用于分割的经典算法,在提取图像中粘连或重叠的对象时特别有用,例如下图中的硬币. 使用传统的图像处理方法,如阈值和轮廓检测,我们将无法从图像中提取每一个硬币,但通过利用分水岭算法,我们能够检测和提取每一个硬币. 在使用分水岭算法时,我们必须从用户定义的标记开始.这些标记可以通过点击手动定义,或者我们可以使用阈值和/或形态学操作等方法自动或启发式定义它们. 基于这些标记,分水岭算法将
-
OpenCV识别提取图像中的水平线与垂直线
本文实例为大家分享了OpenCV识别提取图像中的水平线与垂直线,供大家参考,具体内容如下 1).原理 图像形态学操作时候,可以通过自定义的结构元素实现结构元素 对输入图像一些对象敏感.另外一些对象不敏感,这样就会让敏感的对象改变而不敏感的对象保留输出.通过使用两个最基本的形态学操作 – 膨胀与腐蚀,使用不同的结构元素实现对输入图像的操作.得到想要的结果. -膨胀,输出的像素值是结构元素覆盖下输入图像的最大像素值 -腐蚀,输出的像素值是结构元素覆盖下输入图像的最小像素值 常见的形状:矩形.园.直线
-
利用OpenCV实现质心跟踪算法
目录 质心跟踪算法步骤 项目结构 使用 OpenCV 实现质心跟踪 实现对象跟踪驱动程序脚本 限制和缺点 目标跟踪的过程: 1.获取对象检测的初始集 2.为每个初始检测创建唯一的ID 3.然后在视频帧中跟踪每个对象的移动,保持唯一ID的分配 本文使用OpenCV实现质心跟踪,这是一种易于理解但高效的跟踪算法. 质心跟踪算法步骤 步骤1:接受边界框坐标并计算质心 质心跟踪算法假设我们为每一帧中的每个检测到的对象传入一组边界框 (x, y) 坐标. 这些边界框可以由任何类型的对象检测器(颜色阈值 +
-
OpenCV实现图像细化算法
目录 1.基础概念 2.细化过程 3.代码实现 4.实验结果 1.基础概念 图像细化(Image Thinning),一般指二值图像的骨架化(Image Skeletonization)的一种操作运算.细化是将图像的线条从多像素宽度减少到单位像素宽度过程的简称,一些文章经常将细化结果描述为“骨架化”.“中轴转换”和“对称轴转换”. 细化技术的一个主要应用领域是位图矢量化的预处理阶段,相关研究表明,利用细化技术生成的位图的骨架质量受到多种因素的影响,其中包括图像自身的噪声.线条粗细不均匀.端点的确
-
vs2019永久配置opencv开发环境的方法步骤
有很多同学肯定想学习opencv相关的知识,但是有些情况下每建一次项目都要重新引入下各种文件是不是很苦恼,所以我也面临了这个问题,在网上看到很多的同学的方法,有的也都是很一样的,将什么.dll加入环境变量,然后设置项目配置文件什么的,这些东西我也尝试过,但是很容易忘记,我也特意写了一些笔记,但是有时还是会忘记.恰巧我也升级了vs2019,所以也打算更新下方法,做到一劳永逸.下面是教程部分.首先我们要安装好我们的opencv,然后我们安装以后会看到生成的文件夹.如图 这一切就是基础文件,所以这个务
-
C++中实现OpenCV图像分割与分水岭算法
分水岭算法是一种图像区域分割法,在分割的过程中,它会把跟临近像素间的相似性作为重要的参考依据,从而将在空间位置上相近并且灰度值相近的像素点互相连接起来构成一个封闭的轮廓,封闭性是分水岭算法的一个重要特征. API介绍 void watershed( InputArray image, InputOutputArray markers ); 参数说明: image: 必须是一个8bit 3通道彩色图像矩阵序列 markers: 在执行分水岭函数watershed之前,必须对第二个参数markers
-
Python使用OPENCV的目标跟踪算法实现自动视频标注效果
先上效果 1.首先,要使用opencv的目标跟踪算法,必须要有opencv环境 使用:opencv==4.4.0 和 opencv-contrib-python==4.4.0.46,lxml 这三个环境包. 也可以使用以下方法进行下载 : pip install opencv-python==4.4.0 pip install opencv-contrib-python==4.4.0.4 pip install lxml 2.使用方法: (1):英文状态下的 "s" 是进行标注 (