Java数据结构与算法入门实例详解
第一部分:Java数据结构
要理解Java数据结构,必须能清楚何为数据结构?
数据结构:
- Data_Structure,它是储存数据的一种结构体,在此结构中储存一些数据,而这些数据之间有一定的关系。
- 而各数据元素之间的相互关系,又包括三个组成成分,数据的逻辑结构,数据的存储结构和数据运算结构。
- 而一个数据结构的设计过程分成抽象层、数据结构层和实现层。
数据结构在Java的语言体系中按逻辑结构可以分为两大类:线性数据结构和非线性数据结构。
一、Java数据结构之:线性数据结构
线性数据结构:常见的有一维数组,线性表,栈,队列,双队列,串。
1:一维数组
在Java里面常用的util有:String [],int [],ArrayList,Vector,CopyOnWriteArrayList等。及可以同过一维数组[]自己实现不同逻辑结构的Util类。而ArrayList封装了一些[]的基本操作方法。ArrayList和Vector的区别是:Vector是线程安全的,方法同步。CopyOnWriteArrayList也是线程安全的但效率要比Vector高很多。(PS:如果不懂出门右拐看另一篇chat)。
数组这种数据结构典型的操作方法,是根据下标进行操作的,所以insert的的时候可以根据下标插入到具体的某个位置,但是这个时候它后面的元素都得往后面移动一位。所以插入效率比较低,更新,删除效率也比较低,而查询效率非常高,查询效率时间复杂度是1。
2: 线性表
线性表是有序的储存结构、链式的储存结构。链表的物理储存空间是不连续的,链表的每一个节点都知道上一个节点、或者下一个节点是谁,通常用Node表示。常见的有顺序链表(LinkedList、Linked***),单项链表(里面只有Node类),双向链表(两个Node类),循环链表(多个Node类)等。
操作方法:插入效率比较高,插入的时候只需要改变节点的前后节点的连接即可。而查询效率就比较低了,如果实现的不好,需要整个链路找下去才能找到应该找的元素。所以常见的方法有:add(index,element),addFirst(element),addLast(element)。getFirst(),getLast(),get(element)等。
常见的Uitil有:LinkedList,LinkedMap等,而这两个JDK底层也做了N多优化,可以有效避免查询效率低的问题。当自己实现的时候需要注意。其实树形结构可以说是非线性的链式储存结构。
3: 栈Stack
栈,最主要的是要实现先进后出,后进先出的逻辑结构。来实现一些场景对逻辑顺序的要求。所以常用的方法有push(element)压栈,pop()出栈。
java.util.Stack。就实现了这用逻辑。而Java的Jvm里面也用的到了此种数据结构,就是线程栈,来保证当前线程的执行顺序。
4:队列
队列,队列是一种特殊的线性数据结构,队列只能允许在队头,队尾进行添加和查询等相关操作。队列又有单项有序队列,双向队列,阻塞队列等。
Queue这种数据结构注定了基本操作方法有:add(E e)加入队列,remove(),poll()等方法。
队列在Java语言环境中是使用频率相当高的数据结构,所有其实现的类也很多来满足不同场景。
使用场景也非常多,如线程池,mq,连接池等。
5:串
串:也称字符串,是由N个字符组成的优先序列。在Java里面就是指String,而String里面是由chat[]来进行储存。
KMP算法: 这个算法一定要牢记,Java数据结构这本书里面针对字符串的查找匹配算法也只介绍了一种。关键点就是:在字符串比对的时候,主串的比较位置不需要回退的问题。
二、Java数据结构之:非线性数据结构
非线性数据结构:常见的有:多维数组,集合,树,图,散列表(hash).
1:多维数组
一维数组前面咱也提到了,多维数组无非就是String [][],int[][]等。Java里面很少提供这样的工具类,而java里面tree和图底层的native方法用了多维数组来储存。
2:集合
由一个或多个确定的元素所构成的整体叫做集合。在Java里面可以去广义的去理解为实现了Collection接口的类都叫集合。
3:树
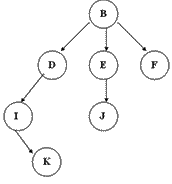
树形结构,作者觉得它是一种特殊的链形数据结构。最少有一个根节点组成,可以有多个子节点。树,显然是由递归算法组成。
树的特点:
在一个树结构中,有且仅有一个结点没有直接父节点,它就是根节点。除了根节点,其他结点有且只有一个直接父节点每个结点可以有任意多个直接子节点。
树的数据结构又分如下几种:
1) 自由树/普通树:对子节点没有任何约束。
2) 二叉树:每个节点最多含有两个子节点的树称为二叉树。
2.1) 一般二叉树:每个子节点的父亲节点不一定有两个子节点的二叉树成为一般二叉树。
2.2) 完全二叉树:对于一颗二叉树,假设其深度为d(d>1)。除了第d层外,其它各层的节点数目均已达最大值,且第d层所有节点从左向右连续地紧密排列,这样的二叉树被称为完全二叉树;
2.3) 满二叉树:所有的节点都是二叉的二叉树成为满二叉树。
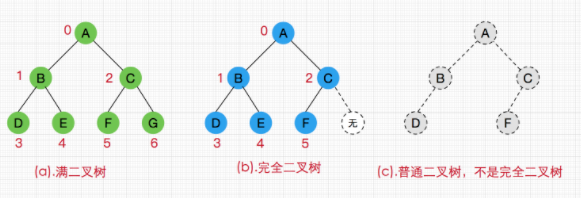
3) 二叉搜索树/BST:binary search tree,又称二叉排序树、二叉查找树。是有序的。要点:如果不为空,那么其左子树节点的值都小于根节点的值;右子树节点的值都大于根节点的值。
3.1) 二叉平衡树:二叉搜索树,是有序的排序树,但左右两边包括子节点不一定平衡,而二叉平衡树是排序树的一种,并且加点条件,就是任意一个节点的两个叉的深度差不多(比如差值的绝对值小于某个常数,或者一个不能比另一个深出去一倍之类的)。这样的树可以保证二分搜索任意元素都是O(log n)的,一般还附带带有插入或者删除某个元素也是O(log n)的的性质。
为了实现,二叉平衡树又延伸出来了一些算法,业界常见的有AVL、和红黑算法,所以又有以下两种树:
3.1.1) AVL树:最早的平衡二叉树之一。应用相对其他数据结构比较少。windows对进程地址空间的管理用到了AVL树。
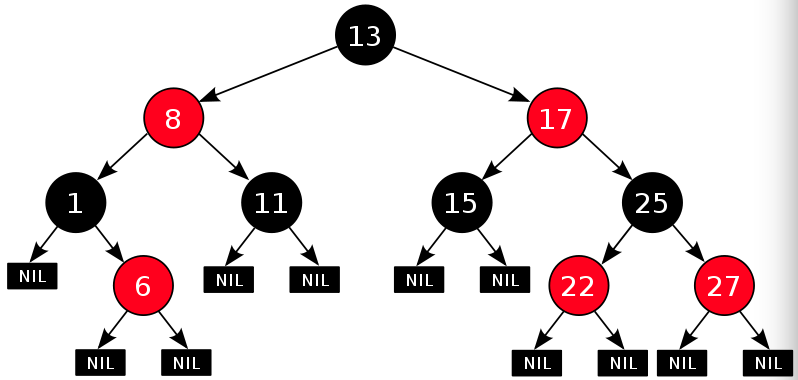
3.1.2) 红黑树:通过制定了一些红黑标记和左右旋转规则来保证二叉树平衡。
红黑树的5条性质:
每个结点要么是红的,要么是黑的。根结点是黑的。每个叶结点(叶结点即指树尾端NIL指针或NULL结点)是黑的。如果一个结点是红的,那么它的俩个儿子都是黑的。对于任一结点而言,其到叶结点树尾端NIL指针的每一条路径都包含相同数目的黑结点。
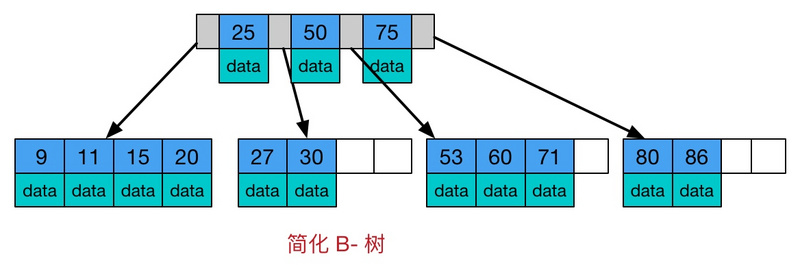
4) B-tree:又称B树、B-树。又叫平衡(balance)多路查找树。树中每个结点最多含有m个孩子(m>=2)。它类似普通的平衡二叉树,不同的一点是B-树允许每个节点有更多的子节点。
4) B+tree:又称B+。是B-树的变体,也是一种多路搜索树。
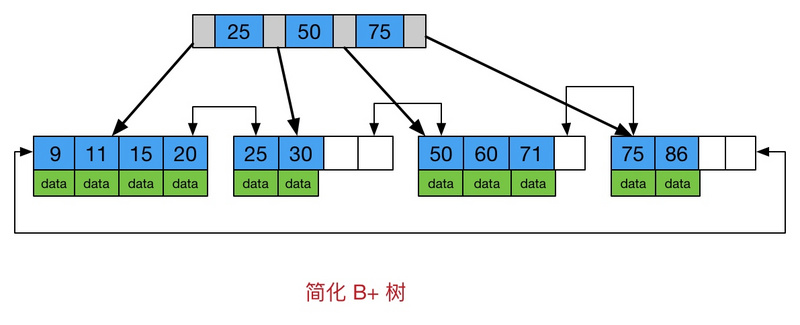
树总结:
树在Java里面应用的也比较多。非排序树,主要用来做数据储存和展示。而排序树,主要用来做算法和运算,HashMap里面的TreeNode就用到了红黑树算法。而B+树在数据库的索引原理里面有典型的应用。
4:Hash
Hash概念:
Hash,一般翻译做“散列”,也有直接音译为“哈希”的,就是把任意长度的输入(又叫做预映射, pre-image),变换成固定长度的输出,该输出就是散列值。一般通过Hash算法实现。
所谓的Hash算法都是散列算法,把任意长度的输入,变换成固定长度的输出,该输出就是散列值.(如:MD5,SHA1,加解密算法等)
简单的说就是一种将任意长度的消息压缩到某一固定长度的消息摘要的函数。
Java中的hashCode:
我们都知道所有的class都是Object的子类,既所有的class都会有默认Object.java里面的hashCode的方法,如果自己没有重写,默认情况就是native方法通过对象的内存的+对象的值然后通过hash散列算法计算出来个int的数字。
最大的特性是:不同的对象,不同的值有可能计算出来的hashCode可能是一样的。
Hash表:
Java中数据存储方式最底层的两种结构,一种是数组,另一种就是链表。而Hash表就是综合了这两种数据结构。
如:HashTable,HashMap。这个时候就得提一下HashMap的原理了,默认16个数组储存,通过Hash值取模放到不同的桶里面去。(注意:JDK1.8此处算法又做了改进,数组里面的值会演变成树形结构。)
哈希表具有较快(常量级)的查询速度,及相对较快的增删速度,所以很适合在海量数据的环境中使用。一般实现哈希表的方法采用“拉链法”,我们可以理解为“链表的数组”。

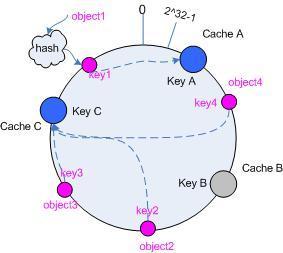
一致性Hash:
我们查看一下HashMap的原理,其实发现Hash很好的解决了单体应用情况下的数据查找和插入的速度问题。但是毕竟单体应用的储存空间是有限的,所有在分布式环境下,应运而生了一致性Hash算法。
用意和hashCode的用意一样,只不过它是取模放在不同的IP机器上而已。具体算法可以找一下相关资料。
而一致性Hash需要注意的就是默认分配的桶比较多些,而当其中一台机器挂了,影响的面比较小一些。
需要注意的是,相同的内容算出来的hash一定是一样的。既:幂等性。
第二部分:Java基本算法
理解了Java数据结构,还必须要掌握一些常见的基本算法。 理解算法之前必须要先理解的几个算法的概念:
空间复杂度:一句来理解就是,此算法在规模为n的情况下额外消耗的储存空间。
时间复杂度:一句来理解就是,此算法在规模为n的情况下,一个算法中的语句执行次数称为语句频度或时间频度。
稳定性:主要是来描述算法,每次执行完,得到的结果都是一样的,但是可以不同的顺序输入,可能消耗的时间复杂度和空间复杂度不一样。
一、二分查找算法
二分查找又称折半查找,优点是比较次数少,查找速度快,平均性能好,占用系统内存较少;其缺点是要求待查表为有序表,且插入删除困难。这个是基础,最简单的查找算法了。
public static void main(String[] args) {
int srcArray[] = {3,5,11,17,21,23,28,30,32,50,64,78,81,95,101};
System.out.println(binSearch(srcArray, 28));
}
/**
* 二分查找普通循环实现
*
* @param srcArray 有序数组
* @param key 查找元素
* @return
*/
public static int binSearch(int srcArray[], int key) {
int mid = srcArray.length / 2;
// System.out.println("=:"+mid);
if (key == srcArray[mid]) {
return mid;
}
//二分核心逻辑
int start = 0;
int end = srcArray.length - 1;
while (start <= end) {
// System.out.println(start+"="+end);
mid = (end - start) / 2 + start;
if (key < srcArray[mid]) {
end = mid - 1;
} else if (key > srcArray[mid]) {
start = mid + 1;
} else {
return mid;
}
}
return -1;
}
二分查找算法如果没有用到递归方法的话,只会影响CPU。对内存模型来说影响不大。时间复杂度log2n,2的开方。空间复杂度是2。一定要牢记这个算法。应用的地方也是非常广泛,平衡树里面大量采用。
二、递归算法
递归简单理解就是方法自身调用自身。
public static void main(String[] args) {
int srcArray[] = {3,5,11,17,21,23,28,30,32,50,64,78,81,95,101};
System.out.println(binSearch(srcArray, 0,15,28));
}
/**
* 二分查找递归实现
*
* @param srcArray 有序数组
* @param start 数组低地址下标
* @param end 数组高地址下标
* @param key 查找元素
* @return 查找元素不存在返回-1
*/
public static int binSearch(int srcArray[], int start, int end, int key) {
int mid = (end - start) / 2 + start;
if (srcArray[mid] == key) {
return mid;
}
if (start >= end) {
return -1;
} else if (key > srcArray[mid]) {
return binSearch(srcArray, mid + 1, end, key);
} else if (key < srcArray[mid]) {
return binSearch(srcArray, start, mid - 1, key);
}
return -1;
}
递归几乎会经常用到,需要注意的一点是:递归不光影响的CPU。JVM里面的线程栈空间也会变大。所以当递归的调用链长的时候需要-Xss设置线程栈的大小。
三、八大排序算法
一、直接插入排序(Insertion Sort)
二、希尔排序(Shell Sort)
三、选择排序(Selection Sort)
四、堆排序(Heap Sort)
五、冒泡排序(Bubble Sort)
六、快速排序(Quick Sort)
七、归并排序(Merging Sort)
八、基数排序(Radix Sort)
八大算法,网上的资料就比较多了。
吐血推荐参考资料:git hub 八大排序算法详解。此大神比作者讲解的还详细,作者就不在这里,描述重复的东西了,作者带领大家把重点的两个强调一下,此两个是必须要掌握的。
1:冒泡排序
基本思想:
冒泡排序(Bubble Sort)是一种简单的排序算法。它重复地走访过要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来。走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。这个算法的名字由来是因为越小的元素会经由交换慢慢“浮”到数列的顶端。
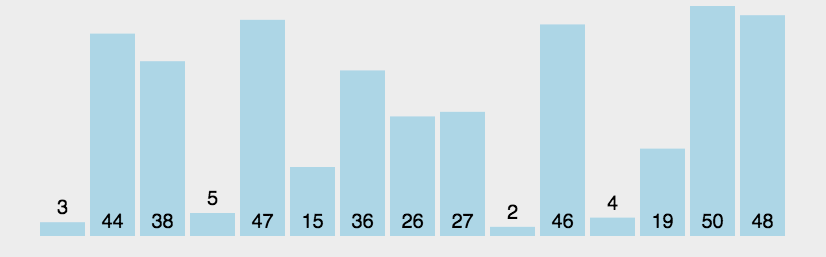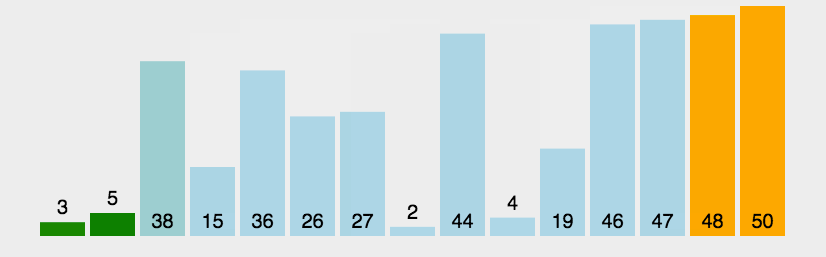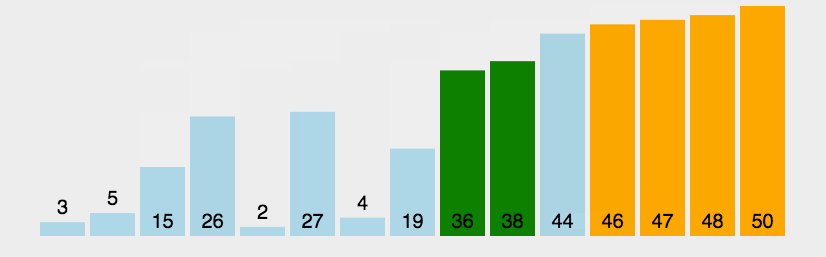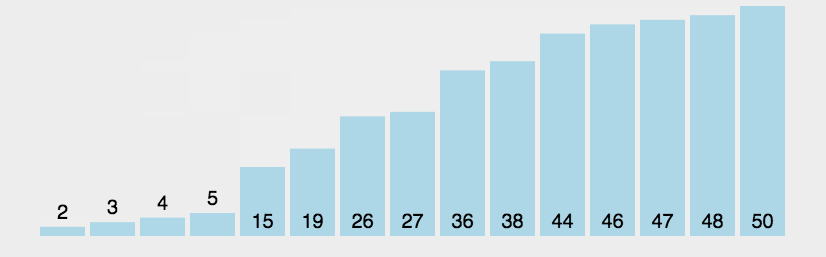
以下是冒泡排序算法复杂度:
| 平均时间复杂度 | 最好情况 | 最坏情况 | 空间复杂度 |
|---|---|---|---|
| O(n²) | O(n) | O(n²) | O(1) |
冒泡排序是最容易实现的排序, 最坏的情况是每次都需要交换, 共需遍历并交换将近n²/2次, 时间复杂度为O(n²). 最佳的情况是内循环遍历一次后发现排序是对的, 因此退出循环, 时间复杂度为O(n). 平均来讲, 时间复杂度为O(n²). 由于冒泡排序中只有缓存的temp变量需要内存空间, 因此空间复杂度为常量O(1).
Tips: 由于冒泡排序只在相邻元素大小不符合要求时才调换他们的位置, 它并不改变相同元素之间的相对顺序, 因此它是稳定的排序算法.
/**
* 冒泡排序
*
* ①. 比较相邻的元素。如果第一个比第二个大,就交换他们两个。
* ②. 对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对。这步做完后,最后的元素会是最大的数。
* ③. 针对所有的元素重复以上的步骤,除了最后一个。
* ④. 持续每次对越来越少的元素重复上面的步骤①~③,直到没有任何一对数字需要比较。
* @param arr 待排序数组
*/
public static void bubbleSort(int[] arr){
for (int i = arr.length; i > 0; i--) { //外层循环移动游标
for(int j = 0; j < i && (j+1) < i; j++){ //内层循环遍历游标及之后(或之前)的元素
if(arr[j] > arr[j+1]){
int temp = arr[j];
arr[j] = arr[j+1];
arr[j+1] = temp;
System.out.println("Sorting: " + Arrays.toString(arr));
}
}
}
}
2:快速排序
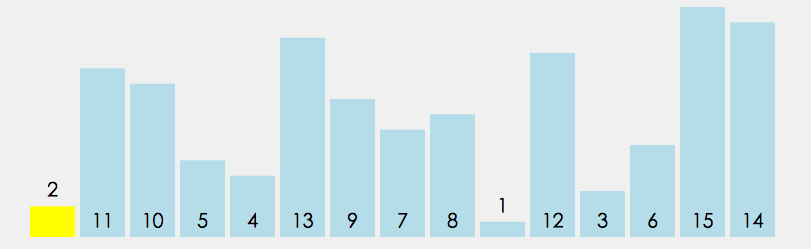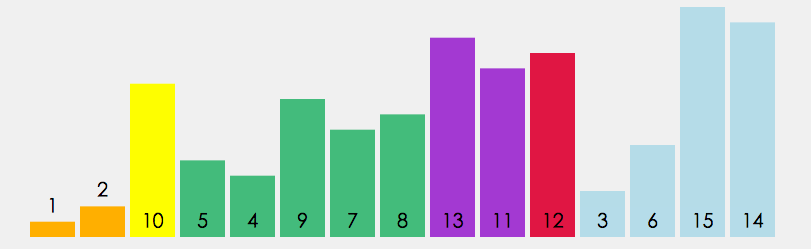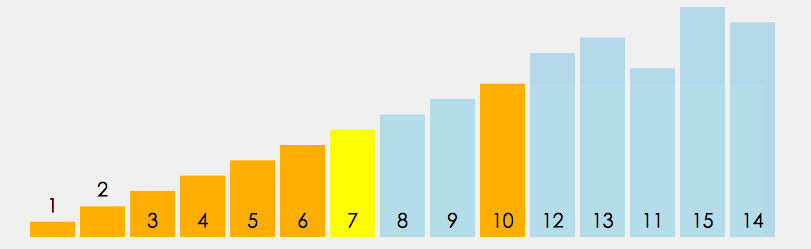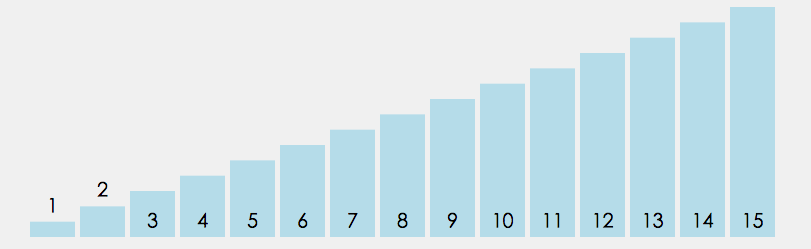
快速排序使用分治策略来把一个序列(list)分为两个子序列(sub-lists)。步骤为:
①. 从数列中挑出一个元素,称为”基准”(pivot)。
②. 重新排序数列,所有比基准值小的元素摆放在基准前面,所有比基准值大的元素摆在基准后面(相同的数可以到任一边)。在这个分区结束之后,该基准就处于数列的中间位置。这个称为分区(partition)操作。
③. 递归地(recursively)把小于基准值元素的子数列和大于基准值元素的子数列排序。
递归到最底部时,数列的大小是零或一,也就是已经排序好了。这个算法一定会结束,因为在每次的迭代(iteration)中,它至少会把一个元素摆到它最后的位置去。
代码实现:
用伪代码描述如下:
①. i = L; j = R; 将基准数挖出形成第一个坑a[i]。
②.j--,由后向前找比它小的数,找到后挖出此数填前一个坑a[i]中。
③.i++,由前向后找比它大的数,找到后也挖出此数填到前一个坑a[j]中。
④.再重复执行②,③二步,直到i==j,将基准数填入a[i]中。
快速排序采用“分而治之、各个击破”的观念,此为原地(In-place)分区版本。
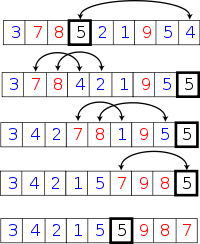
/**
* 快速排序(递归)
*
* ①. 从数列中挑出一个元素,称为"基准"(pivot)。
* ②. 重新排序数列,所有比基准值小的元素摆放在基准前面,所有比基准值大的元素摆在基准后面(相同的数可以到任一边)。在这个分区结束之后,该基准就处于数列的中间位置。这个称为分区(partition)操作。
* ③. 递归地(recursively)把小于基准值元素的子数列和大于基准值元素的子数列排序。
* @param arr 待排序数组
* @param low 左边界
* @param high 右边界
*/
public static void quickSort(int[] arr, int low, int high){
if(arr.length <= 0) return;
if(low >= high) return;
int left = low;
int right = high;
int temp = arr[left]; //挖坑1:保存基准的值
while (left < right){
while(left < right && arr[right] >= temp){ //坑2:从后向前找到比基准小的元素,插入到基准位置坑1中
right--;
}
arr[left] = arr[right];
while(left < right && arr[left] <= temp){ //坑3:从前往后找到比基准大的元素,放到刚才挖的坑2中
left++;
}
arr[right] = arr[left];
}
arr[left] = temp; //基准值填补到坑3中,准备分治递归快排
System.out.println("Sorting: " + Arrays.toString(arr));
quickSort(arr, low, left-1);
quickSort(arr, left+1, high);
}
以下是快速排序算法复杂度:
| 平均时间复杂度 | 最好情况 | 最坏情况 | 空间复杂度 |
|---|---|---|---|
| O(nlog₂n) | O(nlog₂n) | O(n²) | O(1)(原地分区递归版) |
快速排序排序效率非常高。 虽然它运行最糟糕时将达到O(n²)的时间复杂度, 但通常平均来看, 它的时间复杂为O(nlogn), 比同样为O(nlogn)时间复杂度的归并排序还要快. 快速排序似乎更偏爱乱序的数列, 越是乱序的数列, 它相比其他排序而言, 相对效率更高.
相关推荐
-
Java数据结构及算法实例:冒泡排序 Bubble Sort
/** * 冒泡排序估计是每本算法书籍都会提到的排序方法. * 它的基本思路是对长度为N的序列,用N趟来将其排成有序序列. * 第1趟将最大的元素排在序列尾部,第2趟将第2大的元素排在倒数第二的位置, * 即每次把未排好的最大元素冒泡到序列最后端. * 该排序方法实际上分为两重循环,外层循环:待排元素从数组的第1个元素开始. * 内层循环:待排元素从数组的第1个元素开始,直到数组尾端未排过的元素. * 在内循环中,如果遇到前面元素比其后的元素大就交换这两个元素的位置. * 由此可见冒泡排序的复杂
-
Java数据结构及算法实例:朴素字符匹配 Brute Force
/** * 朴素字符串算法通过两层循环来寻找子串, * 好像是一个包含模式的"模板"沿待查文本滑动. * 算法的思想是:从主串S的第pos个字符起与模式串进行比较, * 匹配不成功时,从主串S的第pos+1个字符重新与模式串进行比较. * 如果主串S的长度是n,模式串长度是 m,那么Brute-Force的时间复杂度是o(m*n). * 最坏情况出现在模式串的子串频繁出现在主串S中. * 虽然它的时间复杂度为o(m*n),但在一般情况下匹配时间为o(m+n), * 因此在实际中它被大量
-
Java数据结构及算法实例:考拉兹猜想 Collatz Conjecture
/** * 考拉兹猜想:Collatz Conjecture * 又称为3n+1猜想.冰雹猜想.角谷猜想.哈塞猜想.乌拉姆猜想或叙拉古猜想, * 是指对于每一个正整数,如果它是奇数,则对它乘3再加1, * 如果它是偶数,则对它除以2,如此循环,最终都能够得到1. */ package al; public class CollatzConjecture { private int i = 1; public static void main(String[] args) { long l = 9
-
Java数据结构及算法实例:快速计算二进制数中1的个数(Fast Bit Counting)
/** * 快速计算二进制数中1的个数(Fast Bit Counting) * 该算法的思想如下: * 每次将该数与该数减一后的数值相与,从而将最右边的一位1消掉 * 直到该数为0 * 中间循环的次数即为其中1的个数 * 例如给定"10100",减一后为"10011",相与为"10000",这样就消掉最右边的1 * Sparse Ones and Dense Ones were first described by Peter Wegner i
-
java数据结构与算法之中缀表达式转为后缀表达式的方法
本文实例讲述了java数据结构与算法之中缀表达式转为后缀表达式的方法.分享给大家供大家参考,具体如下: //stack public class StackX { private int top; private char[] stackArray; private int maxSize; //constructor public StackX(int maxSize){ this.maxSize = maxSize; this.top = -1; stackArray = new char[
-
java数据结构和算法学习之汉诺塔示例
复制代码 代码如下: package com.tiantian.algorithms;/** * _|_1 | | * __|__2 | | * ___|___3 | | (1).把A上的4个木块移动到C上. * ____|____4 | | *
-

Java数据结构与算法入门实例详解
第一部分:Java数据结构 要理解Java数据结构,必须能清楚何为数据结构? 数据结构: Data_Structure,它是储存数据的一种结构体,在此结构中储存一些数据,而这些数据之间有一定的关系. 而各数据元素之间的相互关系,又包括三个组成成分,数据的逻辑结构,数据的存储结构和数据运算结构. 而一个数据结构的设计过程分成抽象层.数据结构层和实现层. 数据结构在Java的语言体系中按逻辑结构可以分为两大类:线性数据结构和非线性数据结构. 一.Java数据结构之:线性数据结构 线性数据结构:常见的
-
java数据结构排序算法之归并排序详解
本文实例讲述了java数据结构排序算法之归并排序.分享给大家供大家参考,具体如下: 在前面说的那几种排序都是将一组记录按关键字大小排成一个有序的序列,而归并排序的思想是:基于合并,将两个或两个以上有序表合并成一个新的有序表 归并排序算法:假设初始序列含有n个记录,首先将这n个记录看成n个有序的子序列,每个子序列长度为1,然后两两归并,得到n/2个长度为2(n为奇数的时候,最后一个序列的长度为1)的有序子序列.在此基础上,再对长度为2的有序子序列进行亮亮归并,得到若干个长度为4的有序子序列.如此重
-
java数据结构与算法之快速排序详解
本文实例讲述了java数据结构与算法之快速排序.分享给大家供大家参考,具体如下: 交换类排序的另一个方法,即快速排序. 快速排序:改变了冒泡排序中一次交换仅能消除一个逆序的局限性,是冒泡排序的一种改进:实现了一次交换可消除多个逆序.通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列. 步骤: 1.从数列中挑出一个元素,称为 "基准"(piv
-
java数据结构与算法之插入排序详解
本文实例讲述了java数据结构与算法之插入排序.分享给大家供大家参考,具体如下: 复习之余,就将数据结构中关于排序的这块知识点整理了一下,写下来是想与更多的人分享,最关键的是做一备份,为方便以后查阅. 排序 1.概念: 有n个记录的序列{R1,R2,.......,Rn}(此处注意:1,2,n 是下表序列,以下是相同的作用),其相应关键字的序列是{K1,K2,.........,Kn}.通过排序,要求找出当前下标序列1,2,......,n的一种排列p1,p2,........pn,使得相应关键
-
java数据结构与算法之冒泡排序详解
本文实例讲述了java数据结构与算法之冒泡排序.分享给大家供大家参考,具体如下: 前面文章讲述的排序算法都是基于插入类的排序,这篇文章开始介绍交换类的排序算法,即:冒泡排序.快速排序(冒泡排序的改进). 交换类的算法:通过交换逆序元素进行排序的方法. 冒泡排序:反复扫描待排序记录序列,在扫描的过程中,顺次比较相邻的两个元素的大小,若逆序就交换位置. 算法实现代码如下: package exp_sort; public class BubbleSort { public static void b
-
Java数据结构之平衡二叉树的实现详解
目录 定义 结点结构 查找算法 插入算法 LL 型 RR 型 LR 型 RL 型 插入方法 删除算法 概述 实例分析 代码 完整代码 定义 动机:二叉查找树的操作实践复杂度由树高度决定,所以希望控制树高,左右子树尽可能平衡. 平衡二叉树(AVL树):称一棵二叉查找树为高度平衡树,当且仅当或由单一外结点组成,或由两个子树形 Ta 和 Tb 组成,并且满足: |h(Ta) - h(Tb)| <= 1,其中 h(T) 表示树 T 的高度 Ta 和 Tb 都是高度平衡树 即:每个结点的左子树和右子树的高
-
Java数据结构之二叉搜索树详解
目录 前言 性质 实现 节点结构 初始化 插入节点 查找节点 删除节点 最后 前言 今天leetcode的每日一题450是关于删除二叉搜索树节点的,题目要求删除指定值的节点,并且需要保证二叉搜索树性质不变,做完之后,我觉得这道题将二叉搜索树特性凸显的很好,首先需要查找指定节点,然后删除节点并且保持二叉搜索树性质不变,就想利用这个题目讲讲二叉搜索树. 二叉搜索树作为一个经典的数据结构,具有链表的快速插入与删除的特点,同时查询效率也很优秀,所以应用十分广泛,例如在文件系统和数据库系统一般会采用这种数
-
java操作mongoDB查询的实例详解
java操作mongo查询的实例详解 前言: MongoDB是一个基于分布式文件存储的数据库.由C++语言编写.旨在为WEB应用提供可扩展的高性能数据存储解决方案. MongoDB是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的.他支持的数据结构非常松散,是类似json的bson格式,因此可以存储比较复杂的数据类型.Mongo最大的特点是他支持的查询语言非常强大,其语法有点类似于面向对象的查询语言,几乎可以实现类似关系数据库单表查询的绝大部分功能,而且
-
hibernate4快速入门实例详解
Hibernate是什么 Hibernate是一个轻量级的ORMapping框架 ORMapping原理(Object RelationalMapping) ORMapping基本对应规则: 1:类跟表相对应 2:类的属性跟表的字段相对应 3:类的实例与表中具体的一条记录相对应 4:一个类可以对应多个表,一个表也可以对应对个类 5:DB中的表可以没有主键,但是Object中必须设置主键字段 6:DB中表与表之间的关系(如:外键)映射成为Object之间的关系 7:Object中属性的个数和名称可
-
spring boot + jpa + kotlin入门实例详解
spring boot +jpa的文章网络上已经有不少,这里主要补充一下用kotlin来做. kotlin里面的data class来创建entity可以帮助我们减少不少的代码,比如现在这个User的Entity,这是Java版本的: @Entity public class User { @Id @GeneratedValue(strategy = GenerationType.AUTO) private long id; private String firstName; private S