python用pyinstaller封装exe双击后疯狂闪退解决办法
这里我们需要分析问题报错闪退问题,如何查看问题:
利用 截图工具或者 QQ截图快捷键 去抓取cmd窗口的闪退里面的内容,去查看问题。
大部分都是因为 缺少模块包 导致的。在这里我想说的是网上那种 加 input 和 os.system(“pause”) 还有在cmd命令模式下加 .\***.exe 都是没有用的,如果你的代码真的没有input 那的确是要添加。就算不添加其实也能在CMD命令窗口中执行代码的缓慢过程,但 是 不会闪退的。
闪退解决办法:
1.利用QQ快捷键截图到exe在cmd闪退中代码。
2.截图好后,把截图另存到桌面,方便后续仔细查看问题
3.打开截图 查看问题 ,如果你看不懂其中代码提示,可以进行百度翻译,主要看 error 这类英文后面的命令提示
我以我出现的闪退问题为例:
下面这个图是 利用QQ截图 截图到的
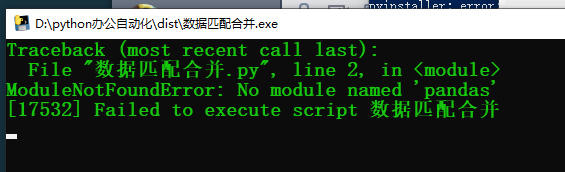
分析上面主要原因是【看error 后面的提示】:No module named “pandas” ----> 缺少名字为 pandas 模块
这个时候,我们发现用的编译器 pycharm 上面明明已经安装了 pandas。
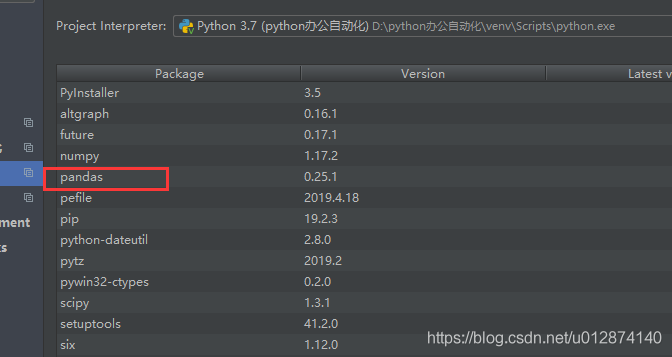
主要原因:pycharm 和 IDLE 是两个python编译器,你在安装模块包的时候,是通过pycharm 编译器安装的,模块包默认都在项目的venv文件下。在 IDLE编译器 里面是没有pandas这个模块包。就会导致你在 IDLE(CMD命令模式) 用 pyinstaller 封装 exe 的时候会缺少模块,在封装的时候也没有报错,因为封装时不检测你的程序是否能执行,只是单纯打包好,就类似于压缩文件。但是在封装好后,双击 exe 程序时候会执行命令,就会提示未识别到模块包,导致闪退。如果您在 IDLE命令模式下 执行pyinstaller 报错,提示没有这个命令,同理也是一样。需要在IDLE 安装pyinstaller命令是 pip install pyinstaller
所以我们在IDLE 封装前要在IDLE模式下安装好模块包,执行如下命令:
pip install pandas
就完美解决 exe闪退问题!
如果需要在IDLE 去安装pycharm 的模块包,就需要指定到安装路径【路劲为 pycharm 创建项目文件下的 ***\venv\Lib\site-packages\】,举例为:
pip install --target=D:\python办公自动化\venv\Lib\site-packages pyinstaller
到此这篇关于python用pyinstaller封装exe双击后疯狂闪退解决办法的文章就介绍到这了,更多相关pyinstaller封装exe双击闪退内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
详解pyinstaller生成exe的闪退问题解决方案
简单模块问题 如果在 pyinstaller project.py 的过程中,出现: No module named 'xxx' 那就 pip install xxx 就行,比如: $ pip install wxPython pypiwin32 tornado 这个 pip 对应于项目的虚拟环境. 其中 wxPython 对应 No module named 'wx' 其中 pypiwin32 对应 No module named 'win32com' 还有个老生常谈的小问题,提一下,避免萌新
-
解决pyinstaller打包发布后的exe文件打开控制台闪退的问题
解决步骤: 1.先打开一个cmd 2.cd到你的exe文件目录 3.输入 .\***.exe 以上这篇解决pyinstaller打包发布后的exe文件打开控制台闪退的问题就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们.
-

python用pyinstaller封装exe双击后疯狂闪退解决办法
这里我们需要分析问题报错闪退问题,如何查看问题: 利用 截图工具或者 QQ截图快捷键 去抓取cmd窗口的闪退里面的内容,去查看问题. 大部分都是因为 缺少模块包 导致的.在这里我想说的是网上那种 加 input 和 os.system("pause") 还有在cmd命令模式下加 .\***.exe 都是没有用的,如果你的代码真的没有input 那的确是要添加.就算不添加其实也能在CMD命令窗口中执行代码的缓慢过程,但 是 不会闪退的. 闪退解决办法: 1.利用QQ快捷键截图到exe在c
-
Eclipse启动Tomcat后无法访问项目解决办法
Eclipse启动Tomcat后无法访问项目解决办法 前言: Eclipse中的Tomcat可以正常启动,不过发布项目之后,无法访问,包括http://localhost:8080/的小猫页面也无法访问到,报404错误.这是因为Eclipse所指定的Server path和Deploy path的问题. 在Eclipse配置的Tomcat Server上双击,可以看到下图: 要想解决上述问题,需要修改Server path 和 Deploy path.选择上面第二项Use Tomcat inst
-
详解Tomcat双击startup.bat闪退的解决方法
作为一个刚学习Tomcat的程序猿来说,这是会经常出现的错误. 1.环境变量问题 1.1 首先需要确认java环境是否配置正确,jdk是否安装正确 win+R打开cmd,输入java 或者 javac 出现下图所示就说明jdk配置正确: 如果没有,则参考jdk的安装及配置 如果以上都没有问题,则向下看. 1.2确认Tomcat的环境变量配置 对于免安装版的Tomcat来说,在启动Tomcat时,需要读取环境变量和配置信息,缺少了这些信息,就不能登记环境变量,导致闪退. 解决方法: 1:在已解压的
-
python中pip安装库时出现Read timed out解决办法
昨天第一次用python画圆,当时并没有安装numpy库(导入数据包)和matplotlib库(导入图形包),于是尝试用pip安装库 首先,我先更新了pip,如下图: 顺便附上成功截图: 然后安装numpy库: 用这种常规方法安装库会出现time out,也就是超时的情况,以下是我的解决方法: 解决办法1:延长timeout时间 raise ReadTimeoutError(self._pool, None, 'Read timed out.')ReadTimeoutError: HTTPSCo
-
Python中str is not callable问题详解及解决办法
Python中str is not callable问题详解及解决办法 问题提出: 在Python的代码,在运行过程中,碰到了一个错误信息: python代码: def check_province_code(province, country): num = len(province) while num <3: province = ''.join([str(0),province]) num = num +1 return country + province 运行的错误信息: check
-
JS定时检测任务任务完成后执行下一步的解决办法
拿到一个需求,web前端调用一个脚本将数据写入ssdb,后从ssdb中查询并做展示.需要检测到脚本执行完毕后再做查询,于是有了如下简单的逻辑,感觉这个逻辑还比较实用,就做下记录~不废话,上代码. <!DOCTYPE html> <html> <head lang="en"> <meta charset="UTF-8"> <title></title> </head> <body
-
Python 爬虫之超链接 url中含有中文出错及解决办法
Python 爬虫之超链接 url中含有中文出错及解决办法 python3.5 爬虫错误: UnicodeEncodeError: 'ascii' codec can't encode characters 这个错误是由于超链接中含有中文引起的,超链接默认是用ascii编码的,所以不能直接出现中文,若要出现中文, 解决方法如下: import urllib from urllib.request import urlopen link="http://list.jd.com/list.html?
-
wamp中mysql安装时能启动重启后无法启动的解决办法
第一次安装wamp之后,所有服务可以正常使用,但是重启之后wamp的图标就变成黄色的了,重装了也这样 查看一下错误日志: 日志显示的错误是这样的: 日志提示可能是3306端口被占用的错误,那来看一下是哪个程序占用了3306端口: windows下运行cmd ,输入 netstat -aon|findstr "3306" 可以看到是pid为2092这个程序占用了3306端口,把他结束掉 输入指令: taskkill /f /pid 2092 成功之后重启wamp,正常启动! 总结 以上所
-
Python用requests库爬取返回为空的解决办法
首先介紹一下我們用360搜索派取城市排名前20. 我们爬取的网址:https://baike.so.com/doc/24368318-25185095.html 我们要爬取的内容: html字段: robots协议: 现在我们开始用python IDLE 爬取 import requests r = requests.get("https://baike.so.com/doc/24368318-25185095.html") r.status_code r.text 结果分析,我们可以