elasticsearch节点间通信的基础transport启动过程
目录
- 前言
- transport
- 启动serverBootStrap
- 如何连接到node
- 连接方法的代码
- 总结
前言
在前一篇中我们分析了cluster的一些元素。接下来的章节会对cluster的运作机制做详细分析。本节先分析一些transport,它是cluster间通信的基础。它有两种实现,一种是基于netty实现nettytransport,主要用于节点间的通信。另一种是localtransport,主要是用于同一个jvm上的节点通信。因为是同一个jvm上的网络模拟,localtransport实现上非常简单,实际用处也非常有限,这里就不过多说明。这一篇的重点是nettytransport。
transport
transport顾名思义是集群通信的基本通道,无论是集群状态信息,还是搜索索引请求信息,都是通过transport传送。elasticsearch定义了tansport,tansportmessage,tansportchannel,tansportrequest,tansportresponse等所需的所有的基础接口。这里将以transport为主,分析过程中会附带介绍其它接口。首先看一下transport节点的定义,如下图所示:
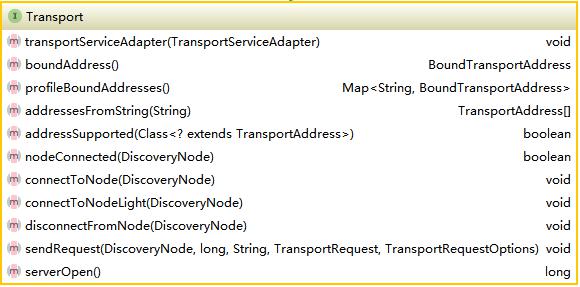
NettyTransport实现了该接口。分析NettyTransport前简单说一下Netty的用法,Netty的使用需要三个模块ServerBootStrap,ClientBootStrap(v3.x)及MessageHandler。ServerBootStrap启动服务器,ClientBootStrap启动客户端并连接服务器,MessageHandler是message处理逻辑所在,也就是业务逻辑。其它详细使用请参考Netty官方文档。
启动serverBootStrap
NettyTransport每个在doStart()方法中启动serverBootStrap,和ClientBootStrap,并绑定ip,代码如下所示:
protected void doStart() throws ElasticsearchException {
clientBootstrap = createClientBootstrap();//根据配置启动客户端
……//省略了无关分代码
createServerBootstrap(name, mergedSettings);//启动server端
bindServerBootstrap(name, mergedSettings);//绑定ip
}
每一个节点都需要发送和接收,因此两者都需要启动,client和server的启动分别在相应的方法中,启动过程就是netty的启动过程,有兴趣可以去看相应方法。bindServerBootstrap(name, mergedSettings)将本地ip和断开绑定到netty同时设定好export host(export host的具体作业我也看明白也没有看到相关的绑定,需要进一步研究)。
启动client及server的过程中将messagehandler注入到channelpipeline中。至此启动过程完成,但是client并未连接任何server,连接过程是在节点启动后,才连接到其它节点的。
如何连接到node
方法代码如下所示:
public void connectToNode(DiscoveryNode node, boolean light) {
//transport的模块必须要启动
if (!lifecycle.started()) {
throw new ElasticsearchIllegalStateException("can't add nodes to a stopped transport");
}
//获取读锁,每个节点可以和多个节点建立连接,因此这里用读锁
globalLock.readLock().lock();
try {
//以node.id为基础获取一个锁,这保证对于每个node只能建立一次连接
connectionLock.acquire(node.id());
try {
if (!lifecycle.started()) {
throw new ElasticsearchIllegalStateException("can't add nodes to a stopped transport");
}
NodeChannels nodeChannels = connectedNodes.get(node);
if (nodeChannels != null) {
return;
}
try {
if (light) {//这里的light,就是对该节点只获取一个channel,所有类型(5种连接类型下面会说到)都使用者一个channel
nodeChannels = connectToChannelsLight(node);
} else {
nodeChannels = new NodeChannels(new Channel[connectionsPerNodeRecovery], new Channel[connectionsPerNodeBulk], new Channel[connectionsPerNodeReg], new Channel[connectionsPerNodeState], new Channel[connectionsPerNodePing]);
try {
connectToChannels(nodeChannels, node);
} catch (Throwable e) {
logger.trace("failed to connect to [{}], cleaning dangling connections", e, node);
nodeChannels.close();
throw e;
}
}
// we acquire a connection lock, so no way there is an existing connection
connectedNodes.put(node, nodeChannels);
if (logger.isDebugEnabled()) {
logger.debug("connected to node [{}]", node);
}
transportServiceAdapter.raiseNodeConnected(node);
} catch (ConnectTransportException e) {
throw e;
} catch (Exception e) {
throw new ConnectTransportException(node, "general node connection failure", e);
}
} finally {
connectionLock.release(node.id());
}
} finally {
globalLock.readLock().unlock();
}
}
如果不是轻连接,每个server和clien之间都有5中连接,着5中连接承担着不同的任务
连接方法的代码
protected void connectToChannels(NodeChannels nodeChannels, DiscoveryNode node) {
//五种连接方式,不同的连接方式对应不同的集群操作
ChannelFuture[] connectRecovery = new ChannelFuture[nodeChannels.recovery.length];
ChannelFuture[] connectBulk = new ChannelFuture[nodeChannels.bulk.length];
ChannelFuture[] connectReg = new ChannelFuture[nodeChannels.reg.length];
ChannelFuture[] connectState = new ChannelFuture[nodeChannels.state.length];
ChannelFuture[] connectPing = new ChannelFuture[nodeChannels.ping.length];
InetSocketAddress address = ((InetSocketTransportAddress) node.address()).address();
//尝试建立连接
for (int i = 0; i < connectRecovery.length; i++) {
connectRecovery[i] = clientBootstrap.connect(address);
}
for (int i = 0; i < connectBulk.length; i++) {
connectBulk[i] = clientBootstrap.connect(address);
}
for (int i = 0; i < connectReg.length; i++) {
connectReg[i] = clientBootstrap.connect(address);
}
for (int i = 0; i < connectState.length; i++) {
connectState[i] = clientBootstrap.connect(address);
}
for (int i = 0; i < connectPing.length; i++) {
connectPing[i] = clientBootstrap.connect(address);
}
//获取每个连接的channel存入到相应的channels中便于后面使用。
try {
for (int i = 0; i < connectRecovery.length; i++) {
connectRecovery[i].awaitUninterruptibly((long) (connectTimeout.millis() * 1.5));
if (!connectRecovery[i].isSuccess()) {
throw new ConnectTransportException(node, "connect_timeout[" + connectTimeout + "]", connectRecovery[i].getCause());
}
nodeChannels.recovery[i] = connectRecovery[i].getChannel();
nodeChannels.recovery[i].getCloseFuture().addListener(new ChannelCloseListener(node));
}
for (int i = 0; i < connectBulk.length; i++) {
connectBulk[i].awaitUninterruptibly((long) (connectTimeout.millis() * 1.5));
if (!connectBulk[i].isSuccess()) {
throw new ConnectTransportException(node, "connect_timeout[" + connectTimeout + "]", connectBulk[i].getCause());
}
nodeChannels.bulk[i] = connectBulk[i].getChannel();
nodeChannels.bulk[i].getCloseFuture().addListener(new ChannelCloseListener(node));
}
for (int i = 0; i < connectReg.length; i++) {
connectReg[i].awaitUninterruptibly((long) (connectTimeout.millis() * 1.5));
if (!connectReg[i].isSuccess()) {
throw new ConnectTransportException(node, "connect_timeout[" + connectTimeout + "]", connectReg[i].getCause());
}
nodeChannels.reg[i] = connectReg[i].getChannel();
nodeChannels.reg[i].getCloseFuture().addListener(new ChannelCloseListener(node));
}
for (int i = 0; i < connectState.length; i++) {
connectState[i].awaitUninterruptibly((long) (connectTimeout.millis() * 1.5));
if (!connectState[i].isSuccess()) {
throw new ConnectTransportException(node, "connect_timeout[" + connectTimeout + "]", connectState[i].getCause());
}
nodeChannels.state[i] = connectState[i].getChannel();
nodeChannels.state[i].getCloseFuture().addListener(new ChannelCloseListener(node));
}
for (int i = 0; i < connectPing.length; i++) {
connectPing[i].awaitUninterruptibly((long) (connectTimeout.millis() * 1.5));
if (!connectPing[i].isSuccess()) {
throw new ConnectTransportException(node, "connect_timeout[" + connectTimeout + "]", connectPing[i].getCause());
}
nodeChannels.ping[i] = connectPing[i].getChannel();
nodeChannels.ping[i].getCloseFuture().addListener(new ChannelCloseListener(node));
}
if (nodeChannels.recovery.length == 0) {
if (nodeChannels.bulk.length > 0) {
nodeChannels.recovery = nodeChannels.bulk;
} else {
nodeChannels.recovery = nodeChannels.reg;
}
}
if (nodeChannels.bulk.length == 0) {
nodeChannels.bulk = nodeChannels.reg;
}
} catch (RuntimeException e) {
// clean the futures
for (ChannelFuture future : ImmutableList.<ChannelFuture>builder().add(connectRecovery).add(connectBulk).add(connectReg).add(connectState).add(connectPing).build()) {
future.cancel();
if (future.getChannel() != null && future.getChannel().isOpen()) {
try {
future.getChannel().close();
} catch (Exception e1) {
// ignore
}
}
}
throw e;
}
}
以上就是节点建立连接的过程,每一对client和server间都会建立一定数量的不同连接。之所以要区分连接,是因为不同的操作消耗的资源不同,请求的频率也不同。对于资源消耗少请求频率高的如ping,可以建立多一些连接,来确保并发。对于消耗资源多如bulk操作,则要少建立一些连接,保证机器不被拖垮。节点的断开,这是讲相应的channel释放的过程。这里就不再做详细说明,可以参考相关源码。
总结
nettytransport的连接过程,启动过程分别启动client和server,同时将对于的messagehandler注入,启动多次就是netty的启动过程。然后绑定server ip和断开。但是这里并没有连接,连接发送在节点启动时,节点启动会获取cluster信息,分别对集群中的节点建立上述的5种连接。
这就是NettyTransport的启动和连接过程。transport还有一个很重要的功能就是发送request,及如何处理request,这些功能会在下一篇中分析,希望大家以后多多支持我们!
相关推荐
-

elasticsearch集群cluster主要功能详细分析
在源码概述中我们分析过,elasticsearch源码从功能上可以分为分布式功能和数据功能,接下来这几篇会就分布式功能展开.这里首先会对cluster作简单概述,然后对cluster所涉及的主要功能详细分析. elasticsearch的集群功能代码在cluster包中,通过ClusterService接口对外暴露. cluster主要包括以下功能: 发现(Discovery),路由(routing),传送功能(transport),集群状态(clusterstates)等. 发现功能功能主要用
-
elasticsearch通过guice注入Node组装启动过程
目录 elasticsearch启动过程 首先看一下node的初始化 启动各个模块的过程 插件的加载过程 elasticsearch启动过程 elasticsearch的启动过程是根据配置和环境组装需要的模块并启动的过程.这一过程就是通过guice注入各个功能模块并启动这些模块,从而得到一个功能完整的node.正如之前所说elasticsearch的模块化特点,它的各个功能都是独立实现,然后实现通过guice对外提供. 首先简单的说一下guice,它是google的一个轻量级依赖注入框架.它的作
-
elasticsearch集群cluster示例详解
目录 前言 节点DiscoveryNode 集群阻塞 clusterService接口 总结 前言 上一篇通过clusterservice对cluster做了一个简单的概述, 应该能够给大家一个初步认识.本篇将对cluster的代码组成进行详细分析,力求能够对cluster做一个更清晰的描述.cluster作为多个节点的协同工作机制,它需要节点,节点间通信,各个节点的状态及各个节点上的数据(index)状态.因此这一部分代码包括了上述的几个部分. 节点DiscoveryNode 首先是节点(Di
-
elasticsearch节点的transport请求发送处理分析
目录 transport请求的发送和处理过程 request的发送过程 request的接受过程 request和response是如何被处理 request的处理 response的处理过程 最后总结 transport请求的发送和处理过程 前一篇分析对nettytransport的启动及连接,本篇主要分析transport请求的发送和处理过程. cluster中各个节点之间需要相互发送很多信息,如master检测其它节点是否存在,node节点定期检测master节点是否存储,cluster状
-
elasticsearch分布式及数据的功能源码分析
从功能上说,可以分为两部分,分布式功能和数据功能.分布式功能主要是节点集群及集群附属功能如restful借口.集群性能检测功能等,数据功能主要是索引和搜索.代码上这些功能并不是完全独立,而是由相互交叉部分.当然分布式功能是为数据功能服务,数据功能肯定也难以完全独立于分布式功能. 它的源码有以下几个特点: 模块化: 每个功能都以模块化的方式实现,最后以一个借口向外暴露,最终通过guice(google轻量级DI框架)进行管理.整个系统有30多个模块(version1.5). 接口解耦: es代码中
-
elasticsearch节点间通信的基础transport启动过程
目录 前言 transport 启动serverBootStrap 如何连接到node 连接方法的代码 总结 前言 在前一篇中我们分析了cluster的一些元素.接下来的章节会对cluster的运作机制做详细分析.本节先分析一些transport,它是cluster间通信的基础.它有两种实现,一种是基于netty实现nettytransport,主要用于节点间的通信.另一种是localtransport,主要是用于同一个jvm上的节点通信.因为是同一个jvm上的网络模拟,localtranspo
-
Java编程之多线程死锁与线程间通信简单实现代码
死锁定义 死锁是指两个或者多个线程被永久阻塞的一种局面,产生的前提是要有两个或两个以上的线程,并且来操作两个或者多个以上的共同资源:我的理解是用两个线程来举例,现有线程A和B同时操作两个共同资源a和b,A操作a的时候上锁LockA,继续执行的时候,A还需要LockB进行下面的操作,这个时候b资源在被B线程操作,刚好被上了锁LockB,假如此时线程B刚好释放了LockB则没有问题,但没有释放LockB锁的时候,线程A和B形成了对LockB锁资源的争夺,从而造成阻塞,形成死锁:具体其死锁代码如下:
-
深入解析Java的线程同步以及线程间通信
Java线程同步 当两个或两个以上的线程需要共享资源,它们需要某种方法来确定资源在某一刻仅被一个线程占用.达到此目的的过程叫做同步(synchronization).像你所看到的,Java为此提供了独特的,语言水平上的支持. 同步的关键是管程(也叫信号量semaphore)的概念.管程是一个互斥独占锁定的对象,或称互斥体(mutex).在给定的时间,仅有一个线程可以获得管程.当一个线程需要锁定,它必须进入管程.所有其他的试图进入已经锁定的管程的线程必须挂起直到第一个线程退出管程.这些其他的线程被
-
vue之父子组件间通信实例讲解(props、$ref、$emit)
组件是 vue.js 最强大的功能之一,而组件实例的作用域是相互独立的,这就意味着不同组件之间的数据无法相互引用.那么组件间如何通信,也就成为了vue中重点知识了.这篇文章将会通过props.$ref和 $emit 这几个知识点,来讲解如何实现父子组件间通信. 在说如何实现通信之前,我们先来建两个组件father.vue和child.vue作为示例的基础. //父组件 <template> <div> <h1>我是父组件!</h1> <child>
-
Java线程间通信不同步问题原理与模拟实例
本文实例讲述了Java线程间通信不同步问题原理与模拟.分享给大家供大家参考,具体如下: 一 点睛 下面两种情况可造成线程间不同步: 1 生产者没生产完,消费者就来消费. 2 消费者没消费完,生产者又来生产,覆盖了还没来得及消费的数据. 二 代码 class Producer implements Runnable { private Person person = null; public Producer( Person person ) { this.person = person; } @
-
超详细的vue组件间通信总结
目录 前言 一.props.$emit单向数据流 二.$parent.$children 三.$attrs.$listeners 四.provide.inject 五.eventBus(事件总线) 六.vuex 七.localstorage 总结 前言 组件通信在我们平时开发过程中,特别是在vue和在react中,有着举足轻重的地位.本篇将总结在vue中,组件之间通信的几种方式: props.$emit $parent.$children $attrs.$listeners provide.in
-
React组件间通信的三种方法(简单易用)
目录 一.父子组件通信 二.跨级组件通信 1.逐层传值 2.跨级传值 三.兄弟(无嵌套)组件通信 四.路由传值 五.Redux React知识中一个主要内容便是组件之间的通信,以下列举几种常用的组件通信方式,结合实例,通俗易懂,建议收藏. 一.父子组件通信 原理:父组件通过props(与vue中的props区分开)向子组件通信,子组件通过回调事件与父组件通信. 首先,先创建一个父组件Parent.js跟子组件Children.js,二者的关系为直接父子关系. Parent.js父组件如下,给父组
-
android Service基础(启动服务与绑定服务)
Service是Android中一个类,它是Android 四大组件之一,使用Service可以在后台执行耗时的操作(注意需另启子线程),其中Service并不与用户产生UI交互.其他的应用组件可以启动Service,即便用户切换了其他应用,启动的Service仍可在后台运行.一个组件可以与Service绑定并与之交互,甚至是跨进程通信.通常情况下Service可以在后台执行网络请求.播放音乐.执行文件读写操作或者与contentprovider交互等. 本文主要讲述service