Java代码实现哈希表(google 公司的上机题)
目录
- 1 哈希表(散列)-Google 上机题
- 2 哈希表的基本介绍
- 3. google 公司的一个上机题:
1 哈希表(散列)-Google 上机题
1) 看一个实际需求,google 公司的一个上机题:
2) 有一个公司,当有新的员工来报道时,要求将该员工的信息加入(id,性别,年龄,住址..),当输入该员工的 id 时,要求查
找到该员工的 所有信息.
3) 要求: 不使用数据库,尽量节省内存,速度越快越好=>哈希表(散列)
2 哈希表的基本介绍
散列表(Hash table,也叫哈希表),是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通
过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组
叫做散列表。
3. google 公司的一个上机题:
有一个公司,当有新的员工来报道时,要求将该员工的信息加入(id,性别,年龄,名字,住址..),当输入该员工的 id 时,
要求查找到该员工的 所有信息.
要求:
1) 不使用数据库,,速度越快越好=>哈希表(散列)
2) 添加时,保证按照 id 从低到高插入
3) 使用链表来实现哈希表, 该链表不带表头[即: 链表的第一个结点就存放雇员信息]
4) 思路分析并画出示意图
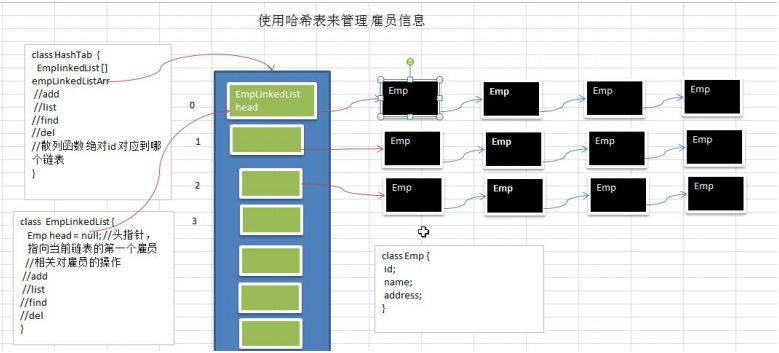
5) 代码实现
public class HashTableDemo {
public static void main(String[] args) {
HashTable hashTable = new HashTable(7);
String key = "";
Scanner scanner = new Scanner(System.in);
while(true) {
System.out.println("add:添加雇员");
System.out.println("list:查看雇员");
System.out.println("find:查找雇员");
System.out.println("del:删除雇员");
System.out.println("exit:退出");
key = scanner.next();
switch (key) {
case "add":
System.out.println("请输入id:");
int id = scanner.nextInt();
System.out.println("请输入名字:");
String name = scanner.next();
Emp emp = new Emp(id, name);
hashTable.add(emp);
break;
case "list":
hashTable.list();
break;
case "find":
System.out.println("请输入id:");
int id2 = scanner.nextInt();
hashTable.findEmpById(id2);
break;
case "del":
System.out.println("请输入id:");
int id3 = scanner.nextInt();
hashTable.del(id3);
break;
case "exit":
System.exit(10);
default:
break;
}
}
}
}
// emp
class Emp{
public int id;
public String name;
public Emp next;
public Emp(int id, String name) {
super();
this.id = id;
this.name = name;
}
}
// EmpLinkedList
class EmpLinkedList{
// 头指针,执行第一个Emp,因此我们这个链表的head,是直接指向第一个Emp
private Emp head;
// id是自增长的
public void add(Emp emp) {
// 如果是添加一个雇员
if(head == null) {
head = emp;
return;
}
// 如果不是第一个
Emp curEmp = head;
while(true) {
if(curEmp.next == null) {
break;
}
curEmp = curEmp.next;
}
curEmp.next = emp;
}
public void list(int no) {
if(head == null) {
System.out.println("第" + (no+1) + "条链表为空!");
return;
}
System.out.println("第" + (no+1) + "条链表信息为:");
Emp curEmp = head;
while(true) {
System.out.printf("=> id=%d name=%s\t",curEmp.id,curEmp.name);
if(curEmp.next == null) {
break;
}
curEmp = curEmp.next;
}
System.out.println();
}
// 根据id查找雇员
public Emp findEmpByid(int id) {
if(head == null) {
System.out.println("链表为空");
return null;
}
Emp curEmp = head;
while(true) {
if(curEmp.id == id) {
break;
}
if(curEmp.next == null) {
System.out.println("遍历完了,没有找到!");
curEmp = null;
break;
}
curEmp = curEmp.next;
}
return curEmp;
}
// 根据id进行删除
public boolean del(int id) {
boolean flag = false;
if(head == null) {
System.out.println("当前链表为空!");
return flag;
}
if(head.id == id) {
head = null;
flag = true;
return flag;
}
Emp curEmp = head;
while(true) {
// 找到了改雇员
if(curEmp.next.id == id) {
curEmp.next = curEmp.next.next;
curEmp.next = null;
return (flag == false);
}
// 没有找到
if(curEmp.next == null) {
System.out.println("没有找改雇员!");
curEmp = null;
return flag;
}
curEmp = curEmp.next;
}
}
}
// 哈希表
class HashTable{
private EmpLinkedList[] empLinkedListArr;
private int size;
public HashTable(int size) {
super();
this.size = size;
empLinkedListArr = new EmpLinkedList[size];
for(int i = 0; i < size; i++){
empLinkedListArr[i] = new EmpLinkedList();
}
}
// 添加雇员
public void add(Emp emp) {
// 根据员工的id得到改员工应该添加到哪条链表
int empLinkedListNo = hashFun(emp.id);
// 将emp添加到对应的链表中
empLinkedListArr[empLinkedListNo].add(emp);
}
public void list() {
for (int i = 0; i < empLinkedListArr.length; i++) {
empLinkedListArr[i].list(i);
}
}
public void findEmpById(int id) {
int empLinkedListNo = hashFun(id);
Emp emp = empLinkedListArr[empLinkedListNo].findEmpByid(id);
if(emp != null) {
System.out.println("在第" + (empLinkedListNo+1) + "条链表中找到id = " + id + "雇员");
} else {
System.out.println("在哈希表中没有找到");
}
}
public void del(int id) {
int empLinkedListNo = hashFun(id);
boolean flag = empLinkedListArr[empLinkedListNo].del(id);
if(flag == true) {
System.out.println("在第" + (empLinkedListNo+1) + "条链表中删除了id = " + id + "雇员");
} else {
System.out.println("在哈希表中没有找到");
}
}
public int hashFun(int id) {
return id %size;
}
}


注意:不要把链表的第一个节点(头节点)删除了,不然整条链表没了。(还可以改良)
思考:如果 id 不是从低到高插入,但要求各条链表仍是从低到高,怎么解决?
到此这篇关于Java 哈希表(google 公司的上机题)的文章就介绍到这了,更多相关java哈希表内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Java 集合框架掌握 Map 和 Set 的使用(内含哈希表源码解读及面试常考题)
目录 1. 搜索 1.1 场景引入 1.2 模型 2. Map 2.1 关于 Map 的介绍 2.2 关于 Map.Entry<K, V> 的介绍 2.3 Map 的常用方法说明 2.4 关于 HashMap 的介绍 2.5 关于 TreeMap 的介绍 2.6 HashMap 和 TreeMap 的区别 2.7 Map 使用示例代码 3. Set 3.1 关于 Set 的介绍 3.1 Set 的常用方法说明 3.3 关于 TreeSet 的介绍 3.4 关于 HashSet 的介绍 3.5
-
Java实现哈希表的基本功能
一.哈希表头插法放入元素 /** * user:ypc: * date:2021-05-20; * time: 11:05; */ public class HashBuck { class Node { public int key; int value; Node next; Node(int key, int value) { this.key = key; this.value = value; } } public int usedSize; public Node[] array;
-
Java深入了解数据结构之哈希表篇
目录 1,概念 2,冲突-避免 3,冲突-避免-哈希函数设计 4,冲突-避免-负载因子调节 5,冲突-解决-闭散列 ①线性探测 ②二次探测 6,冲突-解决-开散列/哈希桶 7,完整代码 1,概念 顺序结构以及平衡树中,元素关键码与其存储位置之间没有对应的关系,因此在查找一个元素时,必须要经过关键 码的多次比较.顺序查找时间复杂度为O(N),平衡树中为树的高度,即O( ),搜索的效率取决于搜索过程中 元素的比较次数. 理想的搜索方法:可以不经过任何比较,一次直接从表中得到要搜索的元素. 如果构造一
-
java中哈希表及其应用详解
哈希表也称为散列表,是用来存储群体对象的集合类结构. 什么是哈希表 数组和向量都可以存储对象,但对象的存储位置是随机的,也就是说对象本身与其存储位置之间没有必然的联系.当要查找一个对象时,只能以某种顺序(如顺序查找或二分查找)与各个元素进行比较,当数组或向量中的元素数量很多时,查找的效率会明显的降低. 一种有效的存储方式,是不与其他元素进行比较,一次存取便能得到所需要的记录.这就需要在对象的存储位置和对象的关键属性(设为 k)之间建立一个特定的对应关系(设为 f),使每个对象与一个唯一的存储位置
-
带你了解Java数据结构和算法之哈希表
目录 1.哈希函数的引入 ①.把数字相加 ②.幂的连乘 2.冲突 3.开放地址法 ①.线性探测 ②.装填因子 ③.二次探测 ④.再哈希法 4.链地址法 5.桶 6.总结 1.哈希函数的引入 大家都用过字典,字典的优点是我们可以通过前面的目录快速定位到所要查找的单词.如果我们想把一本英文字典的每个单词,从 a 到 zyzzyva(这是牛津字典的最后一个单词),都写入计算机内存,以便快速读写,那么哈希表是个不错的选择. 这里我们将范围缩小点,比如想在内存中存储5000个英文单词.我们可能想到每个单词
-
一文彻底搞定Java哈希表和哈希冲突
一.什么是哈希表? 哈希表也叫散列表,它是基于数组的.这间接带来了一个优点:查找的时间复杂度为 O(1).当然,它的插入时间复杂度也是 O(1).还有一个缺点:数组创建后扩容成本较高. 哈希表中有一个"主流"思想:转换.一个重要的概念是将「键」或「关键字」转换成数组下标.这由"哈希函数"完成. 二.什么是哈希函数? 由上,其作用就是将非 int 的键/关键字转化为 int 的值,使可以用来做数组下标. 比如,HashMap 中就这样实现了哈希函数: static f
-
Java数据结构之实现哈希表的分离链接法
哈希表的分离链接法 原理 Hash Table可以看作是一种特殊的数组.他的原理基本上跟数组相同,给他一个数据,经过自己设置的哈希函数变换得到一个位置,并在这个位置当中放置该数据.哦对了,他还有个名字叫散列 0 1 数据1 数据2 就像这个数组,0号位置放着数据1,1号位置放数据2 而我们的哈希表则是通过一个函数f(x) 把数据1变成0,把数据2变成1,然后在得到位置插入数据1和数据2. 非常重要的是哈希表的长度为素数最好!! 而且当插入数据大于一半的时候我们要进行扩充!!! 冲突问题产生 现在
-
JAVA中哈希表HashMap的深入学习
深入浅出学Java--HashMap 哈希表(hash table) 也叫散列表,是一种非常重要的数据结构,应用场景及其丰富,许多缓存技术(比如memcached)的核心其实就是在内存中维护一张大的哈希表,本文会对java集合框架中HashMap的实现原理进行讲解,并对JDK7的HashMap源码进行分析. 一.什么是哈希表 在讨论哈希表之前,我们先大概了解下其他数据结构在新增,查找等基础操作执行性能 数组:采用一段连续的存储单元来存储数据.对于指定下标的查找,时间复杂度为O(1):通过给定值进
-
java数据结构和算法中哈希表知识点详解
树的结构说得差不多了,现在我们来说说一种数据结构叫做哈希表(hash table),哈希表有是干什么用的呢?我们知道树的操作的时间复杂度通常为O(logN),那有没有更快的数据结构?当然有,那就是哈希表: 1.哈希表简介 哈希表(hash table)是一种数据结构,提供很快速的插入和查找操作(有的时候甚至删除操作也是),时间复杂度为O(1),对比时间复杂度就可以知道哈希表比树的效率快得多,并且哈希表的实现也相对容易,然而没有任何一种数据结构是完美的,哈希表也是:哈希表最大的缺陷就是基于数组,因
-
Java代码实现哈希表(google 公司的上机题)
目录 1 哈希表(散列)-Google 上机题 2 哈希表的基本介绍 3. google 公司的一个上机题: 1 哈希表(散列)-Google 上机题 1) 看一个实际需求,google 公司的一个上机题: 2) 有一个公司,当有新的员工来报道时,要求将该员工的信息加入(id,性别,年龄,住址..),当输入该员工的 id 时,要求查 找到该员工的 所有信息. 3) 要求: 不使用数据库,尽量节省内存,速度越快越好=>哈希表(散列) 2 哈希表的基本介绍 散列表(Hash table,也叫哈希表)
-
Java 哈希表详解(google 公司的上机题)
1 哈希表(散列)-Google 上机题 1) 看一个实际需求,google 公司的一个上机题: 2) 有一个公司,当有新的员工来报道时,要求将该员工的信息加入(id,性别,年龄,住址..),当输入该员工的 id 时,要求查 找到该员工的 所有信息. 3) 要求: 不使用数据库,尽量节省内存,速度越快越好=>哈希表(散列) 2 哈希表的基本介绍 散列表(Hash table,也叫哈希表),是根据关键码值(Key value)而直接进行访问的数据结构.也就是说,它通 过把关键码值映射到表中一个位置
-
java代码实现mysql分表操作(用户行为记录)
设置项目气动执行次方法(每天检查一次表记录) public class DayInterval implements ServletContextListener{ private static SimpleDateFormat simpleDateFormat=new SimpleDateFormat("yyyy-MM-dd HH:mm:ss"); public static void showDayTime() { Timer dTimer = new Timer(); dTime
-
C++数据结构哈希表详解
目录 实现 散列函数 开散列方法 闭散列方法(开地址方法) 删除* 实现 哈希表,即散列表,可以快速地存储和查询记录.理想哈希表的存储和查询时间都是 O(1). 本<资料>中哈希表分以下几部分:散列函数.存储和查找时的元素定位.存储.查找.删除操作因为不常用,所以只给出思想,不给出代码. 根据实际情况,可选择不同的散列方法. 以下代码假设哈希表不会溢出. // N表示哈希表长度,是一个素数,M表示额外空间的大小,empty代表"没有元素". const int N=9997
-
Java超详细分析讲解哈希表
目录 哈希表概念 哈希函数的构造 平均数取中法 折叠法 保留余数法 哈希冲突问题以及解决方法 开放地址法 再哈希函数法 公共溢出区法 链式地址法 哈希表的填充因子 代码实现 哈希函数 添加数据 删除数据 判断哈希表是否为空 遍历哈希表 获得哈希表已存键值对个数 哈希表概念 散列表,又称为哈希表(Hash table),采用散列技术将记录存储在一块连续的存储空间中. 在散列表中,我们通过某个函数f,使得存储位置 = f(关键字),这样我们可以不需要比较关键字就可获得需要的记录的存储位置. 散列技术
-
Java真题实练掌握哈希表的使用
目录 1.多数元素 题目描述 思路详解 代码与结果 2.数组中的k-diff数对 题目描述 思路详解 代码与结果 3.缺失的第一个正数 题目描述 思路详解 代码与结果 1.多数元素 题目描述 思路详解 这个思路比较简单,先排序,排序过后遍历如果后一个等于前一个输出就好 代码与结果 class Solution { public int majorityElement(int[] nums) { Arrays.sort(nums); return nums[nums.length / 2]; }