详解Pandas与openpyxl库的超强结合
目录
- 前言
- DataFrame转工作簿
- 工作簿转DataFrame
前言
用过Pandas和openpyxl库的同学都知道,这两个库是相互互补的。Pandas绝对是Python中处理Excel最快、最好用的库,但是使用 openpyxl 的一些优势是能够轻松地使用样式、条件格式等自定义电子表格。
如果你又想轻松的使用Pandas处理Excel数据,又想为Excel电子表格添加一些样式,应该怎么办呢?
但是您猜怎么着,您不必担心挑选。
事实上,openpyxl 支持将数据从 Pandas DataFrame 转换为工作簿,或者相反,将 openpyxl 工作簿转换为 Pandas DataFrame。
DataFrame转工作簿
我们先创建一个DataFrame:
import pandas as pd
data = {
"姓名": ["张三", "李四"],
"性别": ["男", "女"],
"年龄": [15, 25],
}
df = pd.DataFrame(data)
df
结果如下:

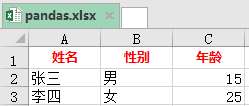
如果想要给表头设置为红色字体,并居中,应该如何设置呢?
from openpyxl import Workbook
from openpyxl.utils.dataframe import dataframe_to_rows
from openpyxl.styles import Font
from openpyxl.styles import Alignment
wb = Workbook()
ws = wb.active
for row in dataframe_to_rows(df, index=False, header=True):
ws.append(row)
font = Font(name="微软雅黑",size=10, bold=True,italic=False,color="FF0000")
alignment = Alignment(horizontal="center",vertical="center")
for i in range(1,df.shape[1]+1):
cell = ws.cell(row=1, column=i)
print(cell.value)
cell.font = font
cell.alignment = alignment
wb.save("pandas.xlsx")
结果如下:
工作簿转DataFrame
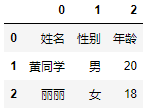
如果有这样一份数据,我们想将其转换为DataFrame,应该怎么做?

其实这个有点多此一举,我们直接使用pandas读取后,处理完数据,在进行样式设计不就行了吗?为何一开始非要使用openpyxl读取工作簿呢?
哈哈,但是既然openpyxl中提供了这种方法,我们就来看看。
import pandas as pd from openpyxl import load_workbook workbook = load_workbook(filename="df_to_openpyxl.xlsx") sheet = workbook.active values = sheet.values df = pd.DataFrame(values) df
结果如下:
到此这篇关于详解Pandas与openpyxl库的超强结合的文章就介绍到这了,更多相关Pandas openpyxl库结合内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Python使用pyautocad+openpyxl处理cad文件示例
本文实例讲述了Python使用pyautocad+openpyxl处理cad文件.分享给大家供大家参考,具体如下: 示例1: from pyautocad import Autocad import openpyxl wb=openpyxl.load_workbook('./cads.xlsx') sheet=wb.get_sheet_by_name('Sheet1') data=[] pset=[] acad=Autocad(create_if_not_exists=True) acad.pr
-
python openpyxl使用方法详解
openpyxl特点 openpyxl(可读写excel表)专门处理Excel2007及以上版本产生的xlsx文件,xls和xlsx之间转换容易 注意:如果文字编码是"gb2312" 读取后就会显示乱码,请先转成Unicode 1.openpyxl 读写单元格时,单元格的坐标位置起始值是(1,1),即下标最小值为1,否则报错! tableTitle = ['userName', 'Phone', 'age', 'Remark'] # 维护表头 # if row < 1 or co
-
Python Excel处理库openpyxl使用详解
openpyxl是一个第三方库,可以处理xlsx格式的Excel文件.pip install openpyxl安装. 读取Excel文件 需要导入相关函数 from openpyxl import load_workbook # 默认可读写,若有需要可以指定write_only和read_only为True wb = load_workbook('pythontab.xlsx') 默认打开的文件为可读写,若有需要可以指定参数read_only为True. 获取工作表--Sheet # 获得所有s
-
python使用openpyxl库修改excel表格数据方法
1.openpyxl库可以读写xlsx格式的文件,对于xls旧格式的文件只能用xlrd读,xlwt写来完成了. 简单封装类: from openpyxl import load_workbook from openpyxl import Workbook from openpyxl.chart import BarChart, Series, Reference, BarChart3D from openpyxl.styles import Color, Font, Alignment from
-
用python + openpyxl处理excel2007文档思路以及心得
寻觅工具 确定任务之后第一步就是找个趁手的库来干活. Python Excel上列出了xlrd.xlwt.xlutils这几个包,但是 它们都比较老,xlwt甚至不支持07版以后的excel 它们的文档不太友好,都可能需要去读源代码,而老姐的任务比较紧,加上我当时在期末,没有这个时间细读源代码 再一番搜索后我找到了openpyxl,支持07+的excel,一直有人在维护,文档清晰易读,参照Tutorial和API文档很快就能上手,就是它了~ 安装 这个很容易,直接pip install open
-

详解Pandas与openpyxl库的超强结合
目录 前言 DataFrame转工作簿 工作簿转DataFrame 前言 用过Pandas和openpyxl库的同学都知道,这两个库是相互互补的.Pandas绝对是Python中处理Excel最快.最好用的库,但是使用 openpyxl 的一些优势是能够轻松地使用样式.条件格式等自定义电子表格. 如果你又想轻松的使用Pandas处理Excel数据,又想为Excel电子表格添加一些样式,应该怎么办呢? 但是您猜怎么着,您不必担心挑选. 事实上,openpyxl 支持将数据从 Pandas Data
-
详解pandas中iloc, loc和ix的区别和联系
Pandas库十分强大,但是对于切片操作iloc, loc和ix,很多人对此十分迷惑,因此本篇博客利用例子来说明这3者之一的区别和联系,尤其是iloc和loc. 对于ix,由于其操作有些复杂,我在另外一篇博客专门详细介绍ix. 首先,介绍这三种方法的概述: loc gets rows (or columns) with particular labels from the index. loc从索引中获取具有特定标签的行(或列).这里的关键是:标签.标签的理解就是name名字. iloc get
-
详解Pandas 处理缺失值指令大全
前言 运用pandas 库对所得到的数据进行数据清洗,复习一下相关的知识. 1 数据清洗 1.1 处理缺失数据 对于数值型数据,分为缺失值(NAN)和非缺失值,对于缺失值的检测,可以通过Python中pandas库的Series类对象的isnull方法进行检测. import pandas as pd import numpy as np string_data = pd.Series(['Benzema', 'Messi', np.nan, 'Ronaldo']) string_data.is
-
详解Pandas中GroupBy对象的使用
目录 使用 Groupby 三个步骤 将原始对象拆分为组 按组应用函数 Aggregation Transformation Filtration 整合结果 总结 今天,我们将探讨如何在 Python 的 Pandas 库中创建 GroupBy 对象以及该对象的工作原理.我们将详细了解分组过程的每个步骤,可以将哪些方法应用于 GroupBy 对象上,以及我们可以从中提取哪些有用信息 不要再观望了,一起学起来吧 使用 Groupby 三个步骤 首先我们要知道,任何 groupby 过程都涉及以下
-
详解Python中pyautogui库的最全使用方法
在使用Python做脚本的话,有两个库可以使用,一个为PyUserInput库,另一个为pyautogui库.就本人而言,我更喜欢使用pyautogui库,该库功能多,使用便利.下面给大家介绍一下pyautogui库的使用方法.在cmd命令框中输入pip3 install pyautogui即可安装该库! 常用操作 我们在pyautogui库中常常使用的方法,如下: import pyautogui pyautogui.PAUSE = 1 # 调用在执行动作后暂停的秒数,只能在执行一些pyaut
-
详解pandas绘制矩阵散点图(scatter_matrix)的方法
使用散点图矩阵图,可以两两发现特征之间的联系 pd.plotting.scatter_matrix(frame, alpha=0.5, c,figsize=None, ax=None, diagonal='hist', marker='.', density_kwds=None,hist_kwds=None, range_padding=0.05, **kwds) 1.frame,pandas dataframe对象 2.alpha, 图像透明度,一般取(0,1] 3.figsize,以英寸为单
-
详解pandas获取Dataframe元素值的几种方法
可以通过遍历的方法: pandas按行按列遍历Dataframe的几种方式:https://www.jb51.net/article/172623.htm 选择列 使用类字典属性,返回的是Series类型 data['w'] 遍历Series for index in data['w'] .index: time_dis = data['w'] .get(index) pandas.DataFrame.at 根据行索引和列名,获取一个元素的值 >>> df = pd.DataFrame(
-
详解pandas.DataFrame.plot() 画图函数
首先看官网的DataFrame.plot( )函数 DataFrame.plot(x=None, y=None, kind='line', ax=None, subplots=False, sharex=None, sharey=False, layout=None,figsize=None, use_index=True, title=None, grid=None, legend=True, style=None, logx=False, logy=False, loglog=False,
-
详解python安装matplotlib库三种失败情况
(可能只有最后一句命令有用,可能全篇都没用) (小白方法,可能只适用于本人情况) 安装matplotlib时,出现的三种失败情况 1.read timed out 一开始我在pycharm终端使用pip install matplotlib时,出现的是下图所示情况,大致情况是安装时间太长,所以当时我用了清华镜像,将原来的命令改成了pip install -i https://mirrors.ustc.edu.cn/pypi/web/simple/ matplotlib,速度是上来了,但是还是安装
-
详解Python中第三方库Faker
项目开发初期,为了测试方便,我们总要造不少假数据到系统中,尽量模拟真实环境. 比如要创建一批用户名,创建一段文本,电话号码,街道地址.IP地址等等. 平时我们基本是键盘一顿乱敲,随便造个什么字符串出来,当然谁也不认识谁. 现在你不要这样做了,用Faker就能满足你的一切需求. 1. 安装 pip install Faker 2. 简单使用 >>> from faker import Faker >>> fake = Faker(locale='zh_CN') >&