Pandas缺失值填充 df.fillna()的实现
df.fillna主要用来对缺失值进行填充,可以选择填充具体的数字,或者选择临近填充。
官方文档
DataFrame.fillna(self, value=None, method=None, axis=None, inplace=False, limit=None, downcast=None)
df.fillna(x)可以将缺失值填充为指定的值
import pandas as pd
# 原数据
df = pd.DataFrame({'A':['a1','a1','a2','a2'],
'B':['b1','b2',None,'b2'],
'C':[1,2,3,4],
'D':[5,6,None,8],
'E':[5,None,7,8]
})
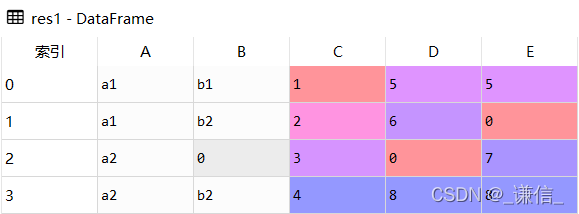
# 将缺失值填充为0
res1 = df.fillna(0)
结果展示
df
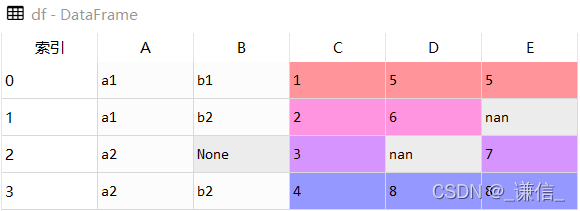
res1
# 常用的方法还有以下几个:
# 填充为0
df.fillna(0)
# 填充为指定字符
df.fillna('missing')
df.fillna('暂无')
df.fillna('待补充')
# 指定字段填充
df.E.fillna('暂无')
# 指定字段填充
df.E.fillna(0, inplace = True)
# 只替换第一个
df.fillna(0, limit = 1)
# 将不同列的缺失值替换为不同的值
values = {'A':0,'B':1,'C':2,'D':3}
df.fillna(value = values)
需要注意的是,如果想让填充马上生效,需要重新为df赋值或者传入参数inplace = True
有时候我们不能填入固定值,而是按照一定的方法填充,df.fillna()提供了一个method参数,可以指定以下几个方法:
pad/ffill:向前填充,使用前一个有效值填充,df.fillna(method=’ffill’)可以简写为df.ffill()
bfill/backfill:向后填充,使用后一个有效值填充,df.fillna(method=’bfill’)可以简写为df.bfill()
import pandas as pd
# 原数据
df = pd.DataFrame({'A':['a1','a1','a2','a2'],
'B':['b1','b2',None,'b2'],
'C':[1,2,3,4],
'D':[5,6,None,8],
'E':[5,None,7,8]
})
# 取后一个有效值填充
res1 = df.fillna(method = 'bfill')
# 取前一个有效值填充
res2 = df.fillna(method = 'ffill')
结果展示
df

res1

res2

除了取前后值,还可以取经过计算得到的值,比如常用的平均值填充法:
# 填充列的平均值 df.fillna(df.mean()) # 对指定列填充平均值 df.fillna(df.mean()['B':'D']) # 另一种填充列的平均值的方法 df.where(pd.notna(df),df.mean(),axis = 'columns')
缺失值的填充的另一思路是使用替换方法df.replace():
# 将指定列的空值替换成指定值
import pandas as pd
import numpy as np
# 原数据
df = pd.DataFrame({'A':['a1','a1','a2','a2'],
'B':['b1','b2',None,'b2'],
'C':[1,2,3,4],
'D':[5,6,None,8],
'E':[5,None,7,8]
})
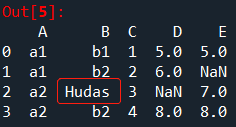
df.replace({'B':{np.nan:'Hudas'}})
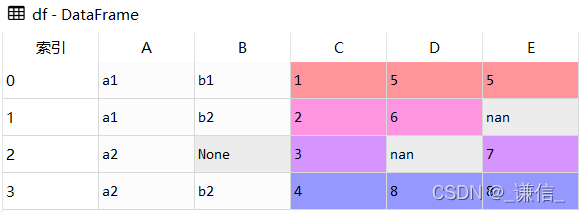
结果展示
到此这篇关于Pandas缺失值填充 df.fillna()的实现的文章就介绍到这了,更多相关Pandas缺失值填充 df.fillna() 内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
对Pandas DataFrame缺失值的查找与填充示例讲解
查看DataFrame中每一列是否存在空值: temp = data.isnull().any() #列中是否存在空值 print(type(temp)) print(temp) 结果如下,返回结果类型是Series,列中不存在空值则对应值为False: <class 'pandas.core.series.Series'> eventid False iyear False imonth False iday False approxdate True extended False reso
-
pandas 使用均值填充缺失值列的小技巧分享
pd.DataFrame中通常含有许多特征,有时候需要对每个含有缺失值的列,都用均值进行填充,代码实现可以这样: for column in list(df.columns[df.isnull().sum() > 0]): mean_val = df[column].mean() df[column].fillna(mean_val, inplace=True) # -------代码分解------- # 判断哪些列有缺失值,得到series对象 df.isnull().sum() > 0
-

Pandas缺失值填充 df.fillna()的实现
df.fillna主要用来对缺失值进行填充,可以选择填充具体的数字,或者选择临近填充. 官方文档 DataFrame.fillna(self, value=None, method=None, axis=None, inplace=False, limit=None, downcast=None) df.fillna(x)可以将缺失值填充为指定的值 import pandas as pd # 原数据 df = pd.DataFrame({'A':['a1','a1','a2','a2'], 'B
-
pandas学习之df.fillna的具体使用
目录 构建实例: value:scalar,series,dict,dataframe method:{backfill,bfill,pad,ffill,none},default none df.fillna主要用来对缺失值进行填充,可以选择填充具体的数字,或者选择临近填充. 官方文档 DataFrame.fillna(self, value=None, method=None, axis=None, inplace=False, limit=None, downcast=None) 解释 构
-
Pandas缺失值删除df.dropna()的使用
函数参数 函数形式:dropna(axis=0, how=‘any’, thresh=None, subset=None, inplace=False) 参数: axis:0或’index’,表示按行删除:1或’columns’,表示按列删除. how:‘any’,表示该行/列只要有一个以上的空值,就删除该行/列:‘all’,表示该行/列全部都为空值,就删除该行/列. thresh:int型,默认为None.如果该行/列中,非空元素数量小于这个值,就删除该行/列. subset:子集.列表,按c
-
pandas 缺失值与空值处理的实现方法
1.相关函数 df.dropna() df.fillna() df.isnull() df.isna() 2.相关概念 空值:在pandas中的空值是"" 缺失值:在dataframe中为nan或者naT(缺失时间),在series中为none或者nan即可 3.函数具体解释 DataFrame.dropna(axis=0, how='any', thresh=None, subset=None, inplace=False) 函数作用:删除含有空值的行或列 axis:维度,axis=
-
Python Pandas删除替换并提取其中的缺失值NaN(dropna,fillna,isnull)
目录 前言 Pandas中缺少值NaN的介绍 将缺失值作为Pandas中的缺少值NaN 缺少值NaN的删除方法 删除所有值均缺失的行/列 删除至少包含一个缺失值的行/列 根据不缺少值的元素数量删除行/列 删除特定行/列中缺少值的列/行 pandas.Series 替换(填充)缺失值 用通用值统一替换 为每列替换不同的值 用每列的平均值,中位数,众数等替换 替换为上一个或下一个值 指定连续更换的最大数量 pandas.Series 提取缺失值 提取特定行/列中缺少值的列/行 提取至少包含一个缺失值
-
pandas检查和填充缺失值的N种方法总结
目录 一.构建示例数据 二.检查缺失值的n种方法 2.1 确认是否有缺失值的两种方法 2.2 查看缺失数目和缺失率 2.3 查看非缺失值数目 三.缺失值填充三种示例 一.构建示例数据 import pandas as pd import numpy as np data = {"ID":[202001, 202002, 202003, 202004, 202005, 202006, 202007, 202008, 202009, 202010], "Chinese"
-
简单了解Pandas缺失值处理方法
这篇文章主要介绍了简单了解Pandas缺失值处理方法,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 判断数据是否为NaN: pd.isnull(df), pd.notnull(df) 判断缺失值是否存在 np.all(pd.notnull(data)) # 返回false代表有空值 np.any(pd.isnull(data)) #返回true代表有空值 处理方式: 存在缺失值nan,并且是np.nan: 1.删除缺失值:dropna(axis
-
pandas 强制类型转换 df.astype实例
废话不多说,大家还是直接看代码吧! import pandas as pd from matplotlib import pyplot as plt from datetime import datetime filename='sitka_weather_2014.csv' df=pd.read_csv(filename) print(df.dtypes) df[' Min Humidity']=df[' Min Humidity'].astype('float64') df=df.astyp
-
Pandas数据形状df.shape的实现
pandas: shape()获取Dataframe的行数和列数 返回列数: df.shape[1] 返回行数: df.shape[0] 或者:len(df) 返回形状,即几行几列的数组 dataframe.shape() 执行df.shape会返回一个元组,该元组的第一个元素代表行数,第二个元素代表列数,这就是这个数据的基本形状,也是数据的大小 import pandas as pd df = pd.DataFrame([['liver','E',89,21,24,64], ['Arry','
-
Pandas索引排序 df.sort_index()的实现
df.sort_index()实现按索引排序,默认以从小到大的升序方式排列,如希望按降序排列,传入ascending = False import pandas as pd df = pd.DataFrame([['liver','E',89,21,24,64], ['Arry','C',36,37,37,57], ['Ack','A',57,60,18,84], ['Eorge','C',93,96,71,78], ['Oah','D',65,49,61,86] ], columns = ['