R语言绘制带误差线的条形图
条形统计图是用一个单位长度表示一定的数量,根据数量的多少画成长短不同的直条.带误差的条形图可以通过误差线来判断显著性。
继续使用我们的汽车销售数据(公众号回复:汽车销售,可以获得该数据)来演示,先导入数据
library(foreign)
library(ggplot2)
library(tidyverse)
bc <- read.spss("E:/r/test/tree_car.sav",
use.value.labels=F, to.data.frame=T)
names(bc)
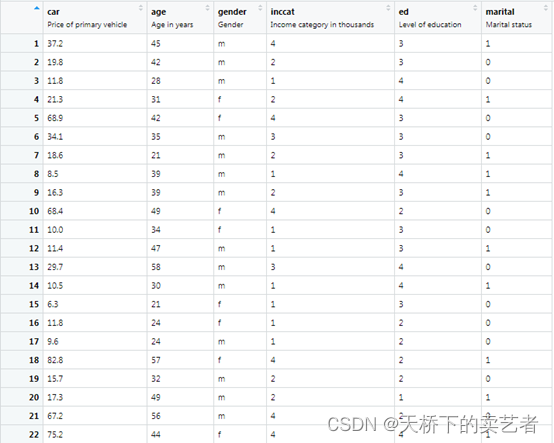
我们来看下数据,car就是汽车售价,age是年龄,gender是性别,inccat是收入,这里分成4个等级,ed是教育程度。
假设我们想知道不同教育水平的男女在买汽车的价格上有什么不同,可绘制带误差和可信区间的折线图,关键就是要算出它的标准误se和95%ci.
我们先生成一个计算标准误se和95%ci的自定义函数,这是国外一位大佬设计的函数,我见好用直接搬运过来了。
summarySE <- function(data=NULL, measurevar, groupvars=NULL, na.rm=FALSE,
conf.interval=.95, .drop=TRUE) {
library(plyr)
# New version of length which can handle NA's: if na.rm==T, don't count them
length2 <- function (x, na.rm=FALSE) {
if (na.rm) sum(!is.na(x))
else length(x)
}
# This does the summary. For each group's data frame, return a vector with
# N, mean, and sd
datac <- ddply(data, groupvars, .drop=.drop,
.fun = function(xx, col) {
c(N = length2(xx[[col]], na.rm=na.rm),
mean = mean (xx[[col]], na.rm=na.rm),
sd = sd (xx[[col]], na.rm=na.rm)
)
},
measurevar
)
# Rename the "mean" column
datac <- rename(datac, c("mean" = measurevar))
datac$se <- datac$sd / sqrt(datac$N) # Calculate standard error of the mean
# Confidence interval multiplier for standard error
# Calculate t-statistic for confidence interval:
# e.g., if conf.interval is .95, use .975 (above/below), and use df=N-1
ciMult <- qt(conf.interval/2 + .5, datac$N-1)
datac$ci <- datac$se * ciMult
return(datac)
}
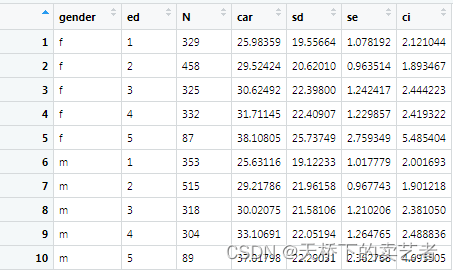
生成函数后,我们使用自定义函数summarySE生成标准误se和95%ci. Measurevar填入你要衡量比较的指标,这里填入汽车售价,groupvars这里填入性别和教育程度。
carss<- summarySE(bc, measurevar="car", groupvars=c("gender","ed"))
生成了我们需要的做图数据
画条形图和画折线图不同的是,教育这个指标我们要转换成分类变量
carss$ed <- factor(carss$ed)
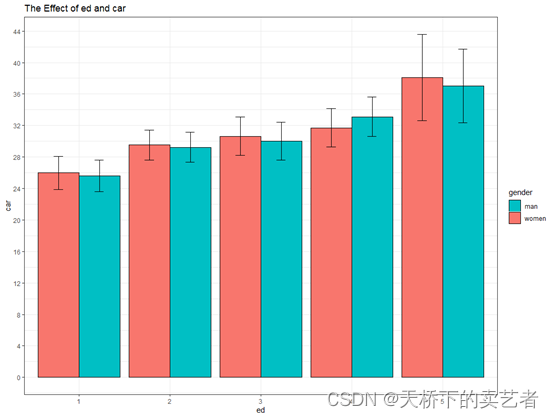
转换好以后就可以做图了,先做一个带误差线的
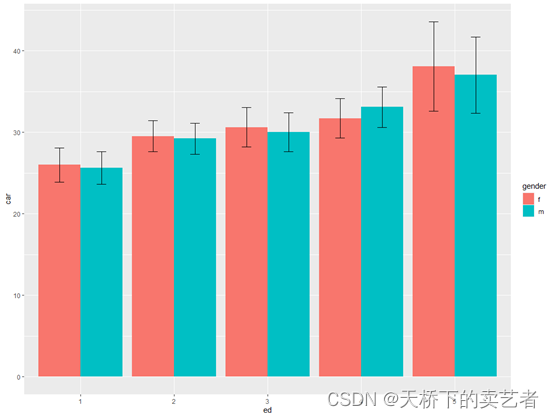
ggplot(carss, aes(x=ed, y=car, fill=gender)) +
geom_bar(position=position_dodge(), stat="identity") +
geom_errorbar(aes(ymin=car-se, ymax=car+se),
width=.2, # Width of the error bars
position=position_dodge(.9))
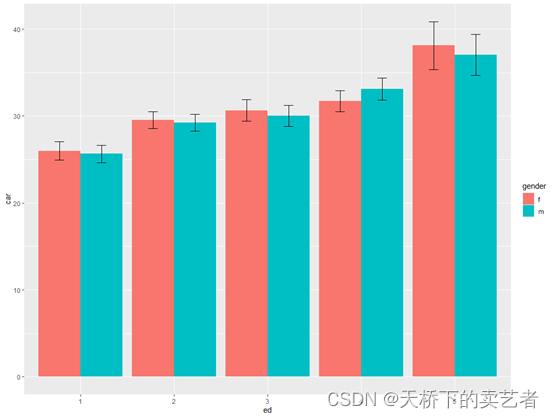
画个带置信区间的
ggplot(carss, aes(x=ed, y=car, fill=gender)) +
geom_bar(position=position_dodge(), stat="identity") +
geom_errorbar(aes(ymin=car-ci, ymax=car+ci),
width=.2, # Width of the error bars
position=position_dodge(.9))
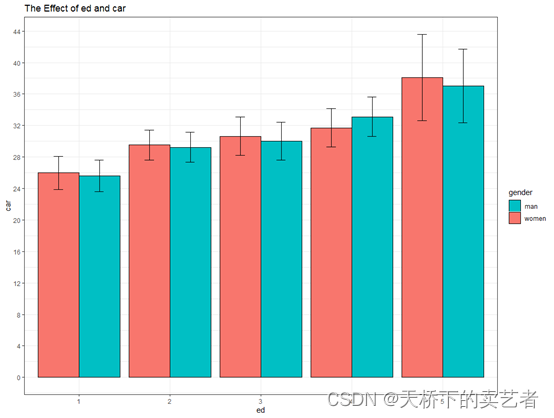
进行美化一下,一个可以用于发表的图就做成了
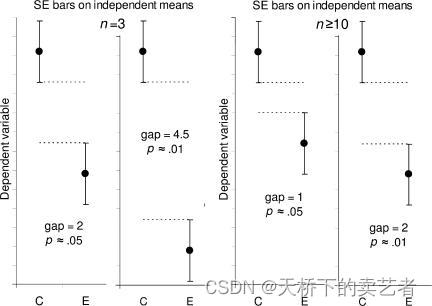
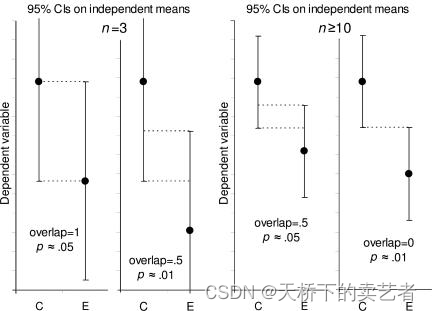
如何利用置信区间来判断显著性
到此这篇关于R语言绘制带误差线的条形图的文章就介绍到这了,更多相关R语言 带误差线条形图内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

R语言绘制条形图及分布密度图代码总结
目录 条形图 普通条形图 分组簇状条形图 分布密度图 条形图 普通条形图 ggplot(df,],aes(x=group,y=value)) +geom_bar(stat = "identity",width = 0.57) #width是条形宽度 +theme_bw() #去掉灰色的背景 +scale_x_discrete(labels=c("AUC-B","AUC-P")) #x轴分组的标签 +labs(x="time",
-
如何用R语言绘制饼图和条形图
R 语言提供来大量的库来实现绘图功能. 饼图,或称饼状图,是一个划分为几个扇形的圆形统计图表,用于描述量.频率或百分比之间的相对关系. R 语言使用 pie() 函数来实现饼图,语法格式如下: pie(x, labels = names(x), edges = 200, radius = 0.8, clockwise = FALSE, init.angle = if(clockwise) 90 else 0, density = NULL, angle = 45, col = NULL, bor
-
R语言条形图创建方法
条形图表示矩形条中的数据,条的长度与变量的值成比例. R语言使用函数 barplot() 创建条形图. R 语言可以在条形图中绘制垂直和水平条. 在条形图中,每个条可以给予不同的颜色. 语法 在 R 语言中创建条形图的基本语法是 H 是包含在条形图中使用的数值的向量或矩阵. xlab 是 x 轴的标签. ylab 是 y 轴的标签. main 是条形图的标题. names.arg 是在每个条下出现的名称的向量. col 用于向图中的条形提供颜色. barplot(H, xlab, ylab, m
-
R语言绘制带误差线的条形图
条形统计图是用一个单位长度表示一定的数量,根据数量的多少画成长短不同的直条.带误差的条形图可以通过误差线来判断显著性. 继续使用我们的汽车销售数据(公众号回复:汽车销售,可以获得该数据)来演示,先导入数据 library(foreign) library(ggplot2) library(tidyverse) bc <- read.spss("E:/r/test/tree_car.sav", use.value.labels=F, to.data.frame=T) names(b
-
R语言绘制line plot线图示例详解
目录 Step1.绘图数据的准备 Step2.绘图数据的读取 Step3.绘图所需package的安装.调用 Step4.绘图 最近小仙同学在Nature Cell Biology上看到了这样一张图,很常见的折线图画成这个样子——原来很常见的图标类型也可以“焕发新春”! 今天小仙同学就尝试用R复刻一张类似的折线图. Step1. 绘图数据的准备 首先要把你想要绘图的数据调整成R语言可以识别的格式,建议大家在excel中保存成csv格式.数据的格式如下图:一列表示一种变量,最后一列是每一行的行名.
-
如何用R语言绘制散点图
散点图是将所有的数据以点的形式展现在直角坐标系上,以显示变量之间的相互影响程度,点的位置由变量的数值决定,每个点对应一个 X 和 Y 轴点坐标. 散点图可以使用 plot() 函数来绘制,语法格式如下: plot(x, y, type="p", main, xlab, ylab, xlim, ylim, axes) x 横坐标 x 轴的数据集合 y 纵坐标 y 轴的数据集合 type:绘图的类型,p 为点.l 为直线, o 同时绘制点和线,且线穿过点. main 图表标题. xlab.
-
用R语言绘制函数曲线图
函数曲线图是研究函数的重要工具. R 中 curve() 函数可以绘制函数的图像,代码格式如下: curve(expr, from = NULL, to = NULL, n = 101, add = FALSE, type = "l", xname = "x", xlab = xname, ylab = NULL, log = NULL, xlim = NULL, -) # S3 函数的方法 plot(x, y = 0, to = 1, from = y, xlim
-
R语言绘制折线图实例分析
折线图是通过在它们之间绘制线段来连接一系列点的图. 这些点在它们的坐标(通常是x坐标)值之一中排序. 折线图通常用于识别数据中的趋势. R语言中的plot()函数用于创建折线图. 语法 在R语言中创建折线图的基本语法是 - plot(v,type,col,xlab,ylab) 以下是所使用的参数的描述 - v是包含数值的向量. 类型采用值"p"仅绘制点,"l"仅绘制线和"o"绘制点和线. xlab是x轴的标签. ylab是y轴的标签. main是
-
R语言绘制直方图实例讲解
直方图表示被存储到范围中的变量的值的频率. 直方图类似于条形图,但不同之处在于将值分组为连续范围. 直方图中的每个柱表示该范围中存在的值的数量的高度. R语言使用hist()函数创建直方图. 此函数使用向量作为输入,并使用一些更多的参数来绘制直方图. 语法 使用R语言创建直方图的基本语法是 hist(v,main,xlab,xlim,ylim,breaks,col,border) 以下是所使用的参数的描述 v是包含直方图中使用的数值的向量. main表示图表的标题. col用于设置条的颜色. b
-
使用R语言绘制散点图结合边际分布图教程
目录 1. 使用ggExtra结合ggplot2 1)传统散点图 2)密度函数 3)直方图 4)箱线图(宽窄的显示会有些问题) 5)小提琴图(会有重叠,不建议使用) 6)密度函数与直方图同时展现 2. 使用cowplot与ggpubr 1)重绘另一种散点图 2)有缝拼接 3)无缝拼接 参考 主要使用ggExtra结合ggplot2两个R包进行绘制.(胜在简洁方便)使用cowplot与ggpubr进行绘制.(胜在灵活且美观) 下面的绘图我们均以iris数据集为例. 1. 使用ggExtra结合gg
-
使用R语言绘制棒棒糖图火柴杆图教程
目录 使用原生ggplot方法 1)生成数据 使用ggpubr包中的ggdotchart() 参考 使用原生ggplot方法 最容易也是最简单想到的方法是直接使用ggplot2包进行更新,这里需要使用ggplot本身的特性,通过图层叠加的方式,进行最终棒棒糖图的展现.(宽度极窄的柱状图配合散点图即可呈现) 1)生成数据 下面我们的展示均以此份数据为例: library(ggplot2) # Load data data("mtcars") dfm <- mtcars # Conv
-
R语言绘制带ErrorBar的分组条形图代码的分享
目录 第一种实现方法:用aggregate计算数据 第二种实现方法:用dplyr包计算数据 笔者近期画了一张带error bar的分组条形图,将相关的代码分享一下. 感谢网友青山屋主的建议,提示笔者要严谨区分技术重复和生物学重复,所以笔者对文章做修改后重发.如果各位有任何建议,欢迎指正. 本文旨在给出一种利用R对生物学重复数据画带error bar的分组条形图的方法. 所用数据是模拟生成的:分成三个组,每个组进行了若干次生物学重复:测量的是3种基因的表达量.数据的部分内容如下: ## gene1