PostgreSQL 实现distinct关键字给单独的几列去重
PostgreSQL去重问题一直困扰着我,distinct和group by远不如MySQL用起来随便,但是如果掌握了规律,还是和MySQL差不多的
主要介绍的是distinct关键字

select distinct id,name,sex,age from student
假如有一张student表,字段如上图,我查询student表中所有信息用distinct去重(上面的SQL语句),pgsql就会根据所有的字段通过算法取得重复行的第一行,但是很明显,ID这个字段我在设计的时候不会让它重复,所以相当于没有去重
我想只根据name和age去重怎么办?
可以这么写
select distinct on (name,age) id,name,sex,age from student
这样就会只根据name和age去重了
总结一下:
distinct on (),括号里面的内容是要去重的列,括号外面的内容是你要查询展示的列,两者没有关系,你可以根据某些列去重不必将他们查询出来,最后这个举一个例子就是:
我要查询name和age,根据name和sex去重:
select distinct on (name,sex) name,age from student
补充:PostgreSQL按照某一字段去重,并显示其他字段信息
以前遇到去重的地方更多的是MySQL去重后统计,比如select count(distinct 字段) from 表,后来临时遇到用Postgresql查询全部信息,但要对某个字段去重,查资料发现select * from table group by 要去重的字段,在MySQL上可以用,就搬到Postgresql试一下发现不行,又Google一番,终于找到一种方案:select distinct on(字段) * from 表,就可以了。
如下图:
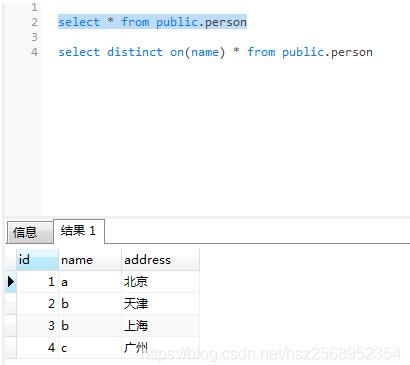
对name字段去重后再查询全部字段:

以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。如有错误或未考虑完全的地方,望不吝赐教。
相关推荐
-
使用PostgreSQL为表或视图创建备注的操作
1 为表和列创建备注 drop table if exists test; create table test( objectid serial not null, num integer not null, constraint pk_test_objectid primary key (objectid), constraint ck_test_num check(num < 123 ), ); comment on table test is '我是表'; comment on colum
-

postgresql安装及配置超详细教程
1. 安装 根据业务需求选择版本,官网下载 yum install https://download.postgresql.org/pub/repos/yum/9.6/redhat/rhel-7-x86_64/pgdg-centos96-9.6-3.noarch.rpm yum install postgresql96 postgresql96-server rpm -qa|grep postgre 初始化数据库 执行完初始化任务之后,postgresql 会自动创建和生成两个用户和一个数据库:
-
Postgresql中LIKE和ILIKE操作符的用法详解
LIKE和ILIKE操作符可以模糊匹配字符串,LIKE是一般用法,ILIKE匹配时则不区分字符串的大小写. 它们需要结合通配符使用,下面介绍两种常用的通配符. %:百分号用于匹配字符串序列,可匹配任意组合: _:下划线用于匹配任何单一字符. 举例来说明LIKE和ILIKE操作符的区别. 先创建一张数据表table1,包含两列:id列和name列,代码如下: create table table1(id int, name varchar); insert into table1 values(1
-
postgreSQL 使用timestamp转成date格式
尝试了以下两种方式,将pg中的timestamp格式转换成date格式: 方式一: select to_date( to_char( f.begin_time, 'yyyy-mm-dd' ), 'yyyy-mm-dd' ) from hafd f 方式二: select f.begin_time::DATE from hafd f 大概比较了一下,9万条测试数据,方式二的性能更好! 补充:PostgreSQL中的时间戳格式转化常识 前提:当数据库中保存的是timestamp类型时,我们需要通过这
-
Docker环境下升级PostgreSQL的步骤方法详解
前段时间接到了要升级数据库的需求,在公司大佬的指导下搞定了升级的方案,在此记录一下. 查阅PostgreSQL 官方文档 可以得知,官方提供了两种方式对数据库进行升级--pg_dumpall与pg_upgrade. pg_dumpall是将数据库转储成一个脚本文件,然后在新版数据库中可以直接导入.这种方式操作简单,跟着官方文档就能轻松操作,但是明显只适用于数据量较少的情况,在我的测试环境里,导入一个2g的数据库用了将近10分钟. 所以我这里选用的是 pg_upgrade,这种方式是直接将数据文件
-
postgresql varchar字段regexp_replace正则替换操作
1.替换目标 1).contact字段类型 varchar. 2).去掉字段中连续的两个,每个等号后面数字不同, effective_caller_id_name=051066824513,effective_caller_id_number=051066824513 2.查询原字段内容 select contact from pbx_agents where contact ~ 'effective_caller_id_name=' limit 2 "{sip_append_audio_sdp
-
PostgreSQL LIKE 大小写实例
PostgreSQL 数据库 函数upper("字符串"):转成大写字符串 WHERE UPPER("User_Name") LIKE upper(username) 此句查询"User_Name" 中值大小写不区分. SELECT "User_Id","User_Image","User_Name","User_Birthday","User_Sex&qu
-
PostgreSQL中的COMMENT用法说明
PostgreSQL附带了一个命令 - COMMENT .如果想要记录数据库中的内容,这个命令很有用.本文将介绍如何使用此命令. 随着数据库的不断发展和数据关系变得越来越复杂,跟踪数据库中添加的所有内容会变得非常困难.要记录数据的组织方式以及可能随时间添加或更改的组件,有必要添加某种文档. 例如,文档可以写在外部文件中,但这会产生一种问题,他们很快就会变为过时的文件.PostgreSQL有一个解决这个问题的方法:COMMENT命令.使用它可以向各种数据库对象添加注释,例如在需要时更新的列,索引,
-
postgresql insert into select无法使用并行查询的解决
本文信息基于PG13.1. 从PG9.6开始支持并行查询.PG11开始支持CREATE TABLE - AS.SELECT INTO以及CREATE MATERIALIZED VIEW的并行查询. 先说结论: 换用create table as 或者select into或者导入导出. 首先跟踪如下查询语句的执行计划: select count(*) from test t1,test1 t2 where t1.id = t2.id ; postgres=# explain analyze se
-
PostgreSQL 实现distinct关键字给单独的几列去重
PostgreSQL去重问题一直困扰着我,distinct和group by远不如MySQL用起来随便,但是如果掌握了规律,还是和MySQL差不多的 主要介绍的是distinct关键字 select distinct id,name,sex,age from student 假如有一张student表,字段如上图,我查询student表中所有信息用distinct去重(上面的SQL语句),pgsql就会根据所有的字段通过算法取得重复行的第一行,但是很明显,ID这个字段我在设计的时候不会让它重复,
-
详解PostgreSQL 语法中关键字的添加
详解PostgreSQL 语法中关键字的添加 当PostgreSQL的后台进程Postgres接收到查询语句后,首先将其传递给查询分析模块,进行词法.语法和语义分析. 记录下在parser语法解析模块添加关键字. 几个核心文件简介 源文件 说明 gram.y 定义语法结构,bison编译后生成gram.y和gram.h scan.l 定义词法结构,flex编译后生成scan.c kwlist.h 关键字列表,需要按序排列 check_keywords.pl linux下会调用其进行关键字检查(顺
-
MySQL基础教程之DML语句详解
目录 DML 语句 1.插入记录 2.更新记录 3.简单查询记录 4.删除记录 5.查询记录详解(DQL语句) 5.1.查询不重复的记录 5.2.条件查询 5.3.聚合查询 5.4.排序查询 5.5.limit查询 5.6.连表查询 5.7.子查询 5.8.记录联合 5.9.select语句的执行顺序 6.总结 DML 语句 DML(Data Manipulation Language)语句:数据操纵语句. 用途:用于添加.修改.删除和查询数据库记录,并检查数据完整性. 常用关键字:insert
-
MySQL关键字Distinct的详细介绍
MySQL关键字Distinct用法介绍 DDL Prepare SQL: create table test(id bigint not null primary key auto_increment, name varchar(10) not null, phone varchar(10) not null, email varchar(30) not null)engine=innodb; Prepare Data: insert into test(name, phone, email)
-
oracle sql 去重复记录不用distinct如何实现
用distinct关键字只能过滤查询字段中所有记录相同的(记录集相同),而如果要指定一个字段却没有效果,另外distinct关键字会排序,效率很低 . select distinct name from t1 能消除重复记录,但只能取一个字段,现在要同时取id,name这2个字段的值. select distinct id,name from t1 可以取多个字段,但只能消除这2个字段值全部相同的记录 所以用distinct达不到想要的效果,用group by 可以解决这个问题. 例如要显示的字
-
MySQL中Distinct和Group By语句的基本使用教程
MySQL Distinct 去掉查询结果重复记录 DISTINCT 使用 DISTINCT 关键字可以去掉查询中某个字段的重复记录. 语法: SELECT DISTINCT(column) FROM tb_name 例子: 假定 user 表有如下记录: uid username 1 小李 2 小张 3 小李 4 小王 5 小李 6 小张 SQL 语句: SELECT DISTINCT(username) FROM user 返回查询结果如下: username 小李 小张 小王 提示 使用
-
SQL语句的各个关键字的解析过程详细总结
由于最近需要做一些sql query性能提升的研究,因此研究了一下sql语句的解决过程.在园子里看了下,大家写了很多相关的文章,大家的侧重点各有不同.本文是我在看了各种资料后手机总结的,会详细的,一步一步的讲述一个sql语句的各个关键字的解析过程,欢迎大家互相学习. SQL语句的解析顺序 简单的说一个sql语句是按照如下的顺序解析的: 1. FROM FROM后面的表标识了这条语句要查询的数据源.和一些子句如,(1-J1)笛卡尔积,(1-J2)ON过滤,(1-J3)添加外部列,所要应用的对象.F
-
SQL中distinct的用法(四种示例分析)
在使用mysql时,有时需要查询出某个字段不重复的记录,虽然mysql提供有distinct这个关键字来过滤掉多余的重复记录只保留一条,但往往只 用它来返回不重复记录的条数,而不是用它来返回不重记录的所有值.其原因是distinct只能返回它的目标字段,而无法返回其它字段,这个问题让我困扰很久,用distinct不能解决的话,我只有用二重循环查询来解决,而这样对于一个数据量非常大的站来说,无疑是会直接影响到效率的,所以浪费了我大量时间. 在表中,可能会包含重复值.这并不成问题,不过,有时您也许希
-
SQL中distinct 和 row_number() over() 的区别及用法
1 前言 在咱们编写 SQL 语句操作数据库中的数据的时候,有可能会遇到一些不太爽的问题,例如对于同一字段拥有相同名称的记录,我们只需要显示一条,但实际上数据库中可能含有多条拥有相同名称的记录,从而在检索的时候,显示多条记录,这就有违咱们的初衷啦!因此,为了避免这种情况的发生,咱们就需要进行"去重"处理啦,那么何为"去重"呢?说白了,就是对同一字段让拥有相同内容的记录只显示一条记录. 那么,如何实现"去重"的功能呢?对此,咱们有两种方式可以实现该
-
SQL中一些小巧但常用的关键字小结
前言 前面的几篇文章中,我们大体上介绍了 SQL 中基本的创建.查询语句,甚至也学习了相对复杂的连接查询和子查询,这些基本功相信你也一定掌握的不错,那么本篇则着重介绍几个技巧方面的关键字,能够让你更快更有效率的写出一些 SQL. 下面话不多说了,来一起看看详细的介绍吧 起别名 在实际的项目中,有时候我们的表名.字段名过于复杂以致于我们的 SQL 写出来过长.过于复杂,这时候我们往往会通过起别名的方式将一些名字较长.较为复杂的字段或是表名简化. 我们可以使用别名(Alias)来对数据表或者列进行临