MySQL中order by的执行过程
目录
- 一 、测试数据
- 二、 全字段排序
- 三、rowid 排序
- 四、全字段排序 与 rowid 排序 比较
前言:
在开发过程中,一定会经常碰到需要根据指定的字段排序来显示结果的需求。还是以前文的订单表为例,假设查询“张三”的所有订单,并且按照订单价格排序返回前 1000 个订单号以及价格。
一 、测试数据
测试的这个订单表my_order的结构是这样的:
CREATE TABLE `my_order` ( `id` int(11) NOT NULL AUTO_INCREMENT, `oid` varchar(20) NOT NULL, `uid` int(11) NOT NULL, `price` decimal(6,2) NOT NULL DEFAULT '0.00', PRIMARY KEY (`id`) USING BTREE, KEY `uid` (`uid`) USING BTREE, KEY `oid` (`oid`) ) ENGINE=InnoDB AUTO_INCREMENT=1000000 DEFAULT CHARSET=utf8;

用户表my_user数据:
上面的订单表my_order的uid 与 用户表my_user的id 关联。
SQL 语句可以这么写:
SELECT oid, price FROM my_order WHERE uid = 1 ORDER BY price LIMIT 1000;
上面的SQL语句看上去逻辑很清晰,但是它的执行流程了解么?这篇文章就来学习一下这个语句是怎么执行的,以及有哪些参数会影响执行。
二、 全字段排序
为避免全表扫描,我们需要在 uid 字段加上索引。在 uid 字段加上索引之后,我们用 EXPLAIN 命令来看看这个语句的执行情况。

Extra 这个字段中的“Using filesort”表示的就是需要排序,MySQL 会给每个线程分配一块内存用于排序,称为 sort_buffer。为了说明这个 SQL 查询语句的执行过程,我们先看一下 uid 这个索引的示意图。
如下图所示:

通常情况下,这个语句执行流程如下 :
- 初始化 sort_buffer,确定放入 oid、price、uid 这三个字段;
- 从索引 uid 找到第一个满足 uid = 1 条件的主键 id,也就是图中的 ID-4;
- 到主键 id 索引取出整行,取 oid、price、uid 三个字段的值,存入 sort_buffer 中;
- 从索引 uid 取下一个记录的主键 id;
- 重复步骤 3、4 直到 uid 的值不满足查询条件为止;
- 对 sort_buffer 中的数据按照字段 oid 做快速排序;
- 按照排序结果取前 1000 行返回给客户端。
“按 oid 排序”这个动作,可能在内存中完成,也可能需要使用外部排序,这取决于排序所需的内存和参数 sort_buffer_size。
sort_buffer_size,就是 MySQL 为排序开辟的内存(sort_buffer)的大小。如果要排序的数据量小于 sort_buffer_size,排序就在内存中完成。但如果排序数据量太大,内存放不下,则不得不利用磁盘临时文件辅助排序。
你可以用下面介绍的方法,来确定一个排序语句是否使用了临时文件。
/* 打开 optimizer_trace,只对本线程有效 */ SET optimizer_trace = 'enabled=on'; /* @a 保存 Innodb_rows_read 的初始值 */ SELECT VARIABLE_VALUE INTO @a FROM PERFORMANCE_SCHEMA.session_status WHERE variable_name='Innodb_rows_read'; /* 执行语句 */ SELECT oid,price FROM my_order WHERE uid=1 ORDER BY price LIMIT 1000; /* 查看 OPTIMIZER_TRACE 输出 */ SELECT * FROM `information_schema`.`OPTIMIZER_TRACE`\G; /* @b 保存 Innodb_rows_read 的当前值 */ SELECT VARIABLE_VALUE INTO @b FROM PERFORMANCE_SCHEMA.session_status WHERE variable_name='Innodb_rows_read'; /* 计算 Innodb_rows_read 差值 */ SELECT @b-@a;
这个方法是通过查看 OPTIMIZER_TRACE 的结果来确认的,你可以从number_of_tmp_files 中看到是否使用了临时文件。

number_of_tmp_files 表示排序过程中使用的临时文件数。你一定奇怪,我当前测试的需要 0 个文件,表示排序可以直接在内存中完成。如果是 n,则表示内存放不下时,就需要使用外部排序,外部排序一般使用归并排序算法。可简单理解,MySQL 将需要排序的数据分成 n 份,每一份单独排序后存在这些临时文件中。然后把这 n 个有序文件再合并成一个有序的大文件。
注:当如果
sort_buffer_size超过了需要排序的数据量的大小,number_of_tmp_files就是 0,表示排序可以直接在内存中完成。
接下来,我再和你解释一下上图中其他两个值的意思。
我们的示例表中有 99972 条满足 uid = 1 的记录,examined_rows=99972,表示参与排序的行数是 99972 行。
sort_mode 里面是 additional_fields。
- 1、
< sort_key, rowid >对应的是MySQL 4.1之前的"原始排序模式"。表明排序缓冲区元组包含排序键值和原始表⾏的⾏id,排序后需要使⽤⾏id进⾏回表,这种算法也称为original filesort algorithm(回表排序算法); - 2、
< sort_key, additional_fields >对应的是MySQL 4.1以后引入的"修改后排序模式"。排序缓冲区元组包含排序键值和查询所需要的列,排序后直接从缓冲区元组取数据,⽆需回表,这种算法也称为modified filesort algorithm(不回表排序); - 3、
< sort_key, packed_additional_fields >是MySQL 5.7.3以后引入的进一步优化的"打包数据排序模式"。这类似上⼀种形式,但是附加的列(如varchar类型)紧密地打包在⼀起,⽽不是使⽤固定长度的编码。
同时,最后一个查询语句 select @b-@a 的返回结果是 99973。
那为啥不是上面那个 99972 呢?
这里需要注意的是,为了避免干扰,你可以把 internal_tmp_disk_storage_engine 设置成 MyISAM。否则,select @b-@a 的结果会显示为 99973。这是因为查询 OPTIMIZER_TRACE 这个表时,需要用到临时表,而 internal_tmp_disk_storage_engine 的默认值是 InnoDB。如果使用的是 InnoDB 引擎的话,把数据从临时表取出来的时候,会让 Innodb_rows_read 的值加 1。

三、rowid 排序
上面那个算法,只对原表的数据读了一遍,剩下的操作都是在 sort_buffer 和临时文件中执行的。但这个算法有一个问题,就是如果查询要返回的字段很多的话,那么 sort_buffer 里面要放的字段数太多,这样内存里能够同时放下的行数很少,要分成很多个临时文件,排序的性能会很差。所以如果单行很大,这个方法效率不够好。
如果 MySQL 认为排序的单行长度太大会怎么做呢?
下面来修改一个参数,让 MySQL 采用另外一种算法。
SET max_length_for_sort_data = 16;
max_length_for_sort_data,是 MySQL 中专门控制用于排序的行数据的长度的一个参数。它的意思是,如果单行的长度超过这个值,MySQL 就认为单行太大,要换一个算法。oid、price这2个字段的定义总长度是 28,我把 max_length_for_sort_data 设置为 16,我们再来看看计算过程有什么改变。新的算法放入 sort_buffer 的字段,只有要排序的列(即 price 字段)和主键 id。但这时,排序的结果就因为少了 price 字段的值,不能直接返回了,
整个执行流程就变成如下所示的样子:
- 初始化 sort_buffer,确定放入两个字段,即 price 和 id;
- 从索引 uid 找到第一个满足 uid= 1 条件的主键 id;
- 到主键 id 索引取出整行,取 price、id 这两个字段,存入 sort_buffer 中;
- 从索引 uid 取下一个记录的主键 id;
- 重复步骤 3、4 直到不满足 uid= 1 条件为止;
- 对 sort_buffer 中的数据按照字段 price 进行排序;
- 遍历排序结果,取前 1000 行,并按照 id 的值回到原表中取出 oid、price 2个字段返回给客户端。
对比全字段排序流程图,rowid 排序多访问了一次表 test 的主键索引,就是步骤 7。
说明:最后的“结果集”只是一个逻辑概念,实际上 MySQL 服务端从排序后的 sort_buffer 中依次取出 id,然后到原表查到 oid、price 这2个字段的结果,不需要在服务端再耗费内存存储结果,是直接返回给客户端的。
那么根据这个时候执行 select @b-@a,结果会是多少呢?
首先,图中的 examined_rows 的值还是 99972,表示用于排序的数据是 99972 行。但是 select @b-@a 这个语句的值变成 100973 了。(比上面的 select @b-@a 99973 多了1000行,因为这时候除了排序过程外,在排序完成后,还要根据 id 去原表取值。由于语句是 limit 1000,因此会多读 1000 行)。

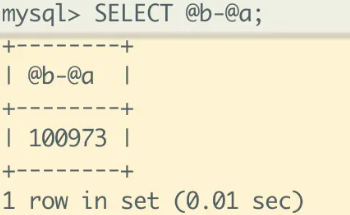
从 OPTIMIZER_TRACE 的结果中,你还能看到另外有个信息也变了。
- sort_mode 变成了 <sort_key, rowid>,表示参与排序的只有 price 和 id 这两个字段。
四、全字段排序 与 rowid 排序 比较
如果 MySQL 实在是担心排序内存太小,会影响排序效率,才会采用 rowid 排序算法,这样排序过程中一次可以排序更多行,但是需要再回到原表去取数据。
如果 MySQL 认为内存足够大,会优先选择全字段排序,把需要的字段都放到 sort_buffer 中,这样排序后就会直接从内存里面返回查询结果了,不用再回到原表去取数据。这也就体现了 MySQL 的一个设计思想:如果内存够,就要多利用内存,尽量减少磁盘访问。对于 InnoDB 表来说,rowid 排序会要求回表多造成磁盘读,因此不会被优先选择。
MySQL 做排序是一个成本比较高的操作。是不是所有的 order by 都需要排序操作呢?如果不排序就能得到正确的结果,那对系统的消耗会小很多,语句的执行时间也会变得更短。其实,并不是所有的 order by 语句,都需要排序操作的。从上面分析的执行过程,我们可以看到,MySQL 之所以需要生成临时表,并且在临时表上做排序操作,其原因是原来的数据都是无序的。如果能够保证从 uid 这个索引上取出来的行,天然就是按照 price 递增排序的话,是不是就可以不用再排序了呢?所以,我们可以在这个市民表上创建一个 uid 和 price 的联合索引,对应的 SQL 语句是:
ALTER TABLE my_order ADD INDEX un_key (uid,price);
作为与 uid 索引的对比,我们来看看这个索引的示意图。
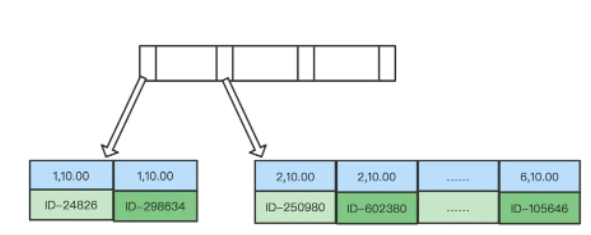
在这个索引里面,我们依然可以用树搜索的方式定位到第一个满足 uid=1 的记录,并且额外确保了,接下来按顺序取“下一条记录”的遍历过程中,只要 uid 的值是 1,price 的值就一定是有序的。
这样整个查询过程的流程就变成了:
- 从索引 (uid,price) 找到第一个满足 city= 1 条件的主键 id;
- 到主键 id 索引取出整行,取 oid、price 2个字段的值,作为结果集的一部分直接返回;
- 从索引 (uid,price) 取下一个记录主键 id;
- 重复步骤 2、3,直到查到第 1000 条记录,或者是不满足 uid=1 条件时循环结束。
这个查询过程不需要临时表,也不需要排序。接下来,我们用 EXPLAIN 的结果来印证一下。
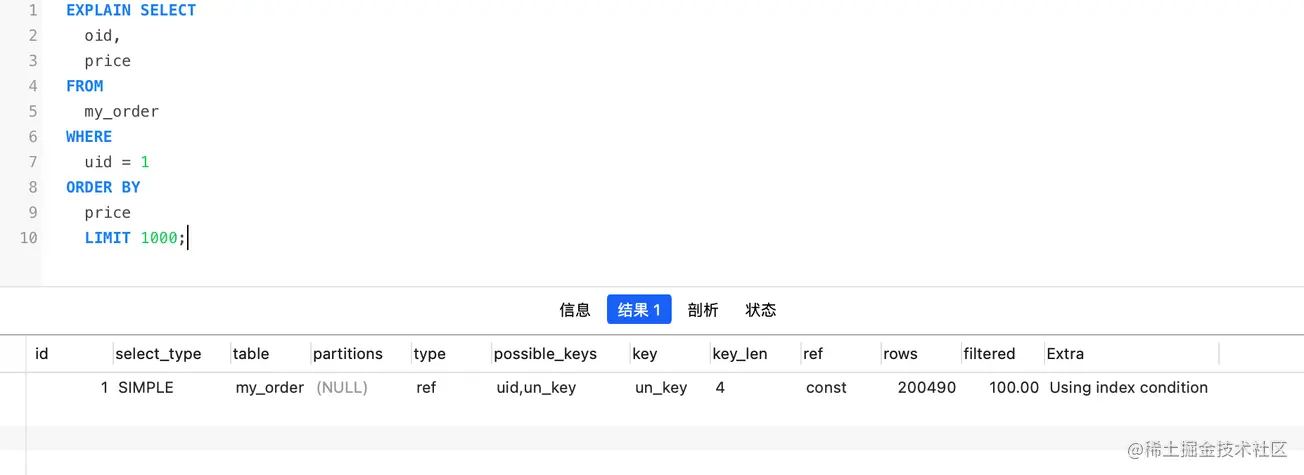
从图中可以看到,Extra 字段中没有 Using filesort 了,也就是不需要排序了。而且由于 (uid,price) 这个联合索引本身有序,所以这个查询也不用把 99972 行全都读一遍,只要找到满足条件的前 1000 条记录就可以退出了。也就是说,在我们这个例子里,只需要扫描 1000 次。同样看下 select @b-@a;

再稍微复习一下。覆盖索引是指,索引上的信息足够满足查询请求,不需要再回到主键索引上去取数据。Extra 字段里面多了“Using index”,表示的就是使用了覆盖索引,性能上会快很多。
当然,这里并不是说要为了每个查询能用上覆盖索引,就要把语句中涉及的字段都建上联合索引,毕竟索引还是有维护代价的。这是一个需要权衡的决定。
到此这篇关于MySQL中order by的执行过程的文章就介绍到这了,更多相关MySQL order by 内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
MySQL group by和order by如何一起使用
假设有一个表:reward(奖励表),表结构如下: CREATE TABLE test.reward ( id int(11) NOT NULL AUTO_INCREMENT, uid int(11) NOT NULL COMMENT '用户uid', money decimal(10, 2) NOT NULL COMMENT '奖励金额', datatime datetime NOT NULL COMMENT '时间', PRIMARY KEY (id) ) ENGINE = INNODB A
-
MySQL不使用order by实现排名的三种思路总结
假定业务: 查看在职员工的薪资的第二名的员工信息 创建数据库 drop database if exists emps; create database emps; use emps; create table employees( empId int primary key,-- 员工编号 gender char(1) NOT NULL, -- 员工性别 hire_date date NOT NULL -- 员工入职时间 ); create table salaries( empId int
-

MySQL中order by的使用详情
目录 1.简介 2.正文 2.1 单个列排序 2.2 多个列排序 2.3 排序的方式 2.4 order by结合limit 1.简介 在使用select语句时可以结合order by对查询的数据进行排序.如果不使用order by默认情况下MySQL返回的数据集,与它在底层表中的顺序相同,可能与你添加数据到表中的顺序一致,也可能不一致(在你对表进行修改.删除等操作时MySQL会对内存进行整理,此时数据的顺序会发生改变)因此如果我们希望得到的数据是有顺序的,就应该明确排序方式. 2.正文 首先准
-
MySql分页时使用limit+order by会出现数据重复问题解决
目录 摘要 问题描述 分析问题 解决问题 摘要 能把复杂的知识讲的简单很重要 在学习的过程中我们看过很多资料.视频.文档等,因为现在资料视频都较多所以往往一个知识点会有多种多样的视频形式讲解.除了推广营销以外,确实有很多人的视频讲解非常优秀,例如李永乐老师的短视频课,可以在一个黑板上把那么复杂的知识,讲解的那么容易理解,那么透彻.而我们学习编程的人也是,不只是要学会把知识点讲明白,也要写明白. 问题描述 在 MySQL 中我们通常会采用 limit 来进行翻页查询,比如 limit(0,10)
-
MySQL数据库索引order by排序精讲
排序这个词,我的第一感觉是几乎所有App都有排序的地方,淘宝商品有按照购买时间的排序.B站的评论有按照热度排序的... 对于MySQL,一说到排序,你第一时间想到的是什么?关键字order by?order by的字段最好有索引?叶子结点已经是顺序的?还是说尽量不要在MySQL内部排序? 事情的起因 现在假设有一张用户的朋友表: CREATE TABLE `user` ( `id` int(10) AUTO_INCREMENT, `user_id` int(10), `friend_addr`
-
MySQL中order by的执行过程
目录 一 .测试数据 二. 全字段排序 三.rowid 排序 四.全字段排序 与 rowid 排序 比较 前言: 在开发过程中,一定会经常碰到需要根据指定的字段排序来显示结果的需求.还是以前文的订单表为例,假设查询“张三”的所有订单,并且按照订单价格排序返回前 1000 个订单号以及价格. 一 .测试数据 测试的这个订单表my_order的结构是这样的: CREATE TABLE `my_order` ( `id` int(11) NOT NULL AUTO_INCREMENT, `oid` v
-
详解MySQL中Order By排序和filesort排序的原理及实现
目录 1.Order By原理 2.filesort排序算法 3.优化排序 1.Order By原理 MySQL的Order By操作用于排序,并且会有多种不同的排序算法,他们的性能都是不一样的. 假设有一个表,建表的sql如下: CREATE TABLE `obtest` ( `id` BIGINT NOT NULL AUTO_INCREMENT, `a` VARCHAR ( 100 ) NOT NULL, `b` VARCHAR ( 100 ) NOT NULL, `c` VARCHAR (
-
MySQL中order by排序语句的原理解析
order by 是怎么工作的? 表定义 CREATE TABLE `t1` ( `id` int(11) NOT NULL, `city` varchar(16) NOT NULL, `name` varchar(16) NOT NULL, `age` int(11) NOT NULL, `addr` varchar(128) DEFAULT NULL, PRIMARY KEY (`id`), KEY `city` (`city`)) ENGINE=InnoDB; SQL语句可以这样写: se
-
深入解析mysql中order by与group by的顺序问题
mysql 中order by 与group by的顺序是:selectfromwheregroup byorder by注意:group by 比order by先执行,order by不会对group by 内部进行排序,如果group by后只有一条记录,那么order by 将无效.要查出group by中最大的或最小的某一字段使用 max或min函数.例:select sum(click_num) as totalnum,max(update_time) as update_time,
-
MySQL中Order By多字段排序规则代码示例
说在前面 突发奇想,想了解一下mysql order by排序是以什么规则进行的? 好了,话不多说,直接进入正题吧. MySql order by 单字段 建一测试表如下: CREATE TABLE `a` ( `code` varchar(255) DEFAULT NULL, `name` varchar(255) DEFAULT NULL ) ENGINE=InnoDB DEFAULT CHARSET=utf8; INSERT into a values('中一', '我'); INSERT
-
Mysql中order by、group by、having的区别深入分析
order by 从英文里理解就是行的排序方式,默认的为升序. order by 后面必须列出排序的字段名,可以是多个字段名. group by 从英文里理解就是分组.必须有"聚合函数"来配合才能使用,使用时至少需要一个分组标志字段. 什么是"聚合函数"? 像sum().count().avg()等都是"聚合函数" 使用group by 的目的就是要将数据分类汇总. 一般如: select 单位名称,count(职工id),sum(职工工资)
-
React中的render何时执行过程
我们都知道Render在组件实例化和存在期时都会被执行.实例化在componentWillMount执行完成后就会被执行,这个没什么好说的.在这里我们主要分析存在期组件更新时的执行. 存在期的方法包含: - componentWillReceiveProps - shouldComponentUpdate - componentWillUpdate - render - componentDidUpdate 这些方法会在组件的状态或者属性发生发生变化时被执行,如果我们使用了Redux,那么就只有
-
mysql中order by与group by的区别
order by 从英文里理解就是行的排序方式,默认的为升序. order by 后面必须列出排序的字段名,可以是多个字段名. group by 从英文里理解就是分组.必须有"聚合函数"来配合才能使用,使用时至少需要一个分组标志字段. 什么是"聚合函数"? 像sum().count().avg()等都是"聚合函数" 使用group by 的目的就是要将数据分类汇总.
-
MySQL中安装样本数据库Sakila过程分享
通常情况下对于一个全新的MySQL服务器,没有任何数据供我们测试和使用.对此,MySQL为我们提供了一些样本数据库,我们可以基于这些数据库作基本的操作以及压力测试等等.本文描述的是安装sakila数据库.该数据库需要安装在MySQL 5.0以上的版本.以下是其描述. 1.下载种子数据库 下载位置:http://dev.mysql.com/doc/index-other.html 2.安装种子数据库sakila 复制代码 代码如下: [root@localhost ~]# unzip sakila