一文搞懂Pandas数据透视的4个函数的使用
目录
- pandas.melt()
- pandas.pivot()
- pandas.pivot_table()
- pandas.crosstab()
大家好,我是丁小杰!
今天和大家分享Pandas中四种有关数据透视的通用函数,在数据处理中遇到这类需求时,能够很好地应对。
pandas.melt()
melt函数的主要作用是将DataFrame从宽格式转换成长格式。
“
pandas.melt(frame,id_vars=None, value_vars=None, var_name=None, value_name='value', col_level=None, ignore_index=True)
”
参数含义
id_vars:tuple, list, or ndarray,可选,作为标识符变量的列value_vars:tuple, list, or ndarray, 可选,透视列,如果未指定,则使用未设置为id_vars的所有列。var_name:scalar,默认为None,使用variable作为列名value_name:标量, default ‘value’,value列的名称col_level:int or str, 可选,如果列是多层索引,melt将应用于指定级别ignore_index:bool, 默认为True,相当于从0开始重新排序。如果为False,则保留原来的索引,索引标签将出现重复。
看个例子先:
import pandas as pd
df = pd.DataFrame(
{'地区': ['A', 'B', 'C'],
'2020': [80, 60, 40],
'2021': [800, 600, 400],
'2022': [8000, 6000, 4000]})

pd.melt(df, id_vars=['地区'], value_vars=['2020', '2021', '2022'])

设置var_name与value_name。
df = pd.melt(df, id_vars=['地区'], value_vars=['2020', '2021', '2022'], var_name='年份', value_name='销售额')

pandas.pivot()
pivot函数主要用于通过索引及列值对DataFrame重构。
“
pandas.pivot(data, index=None, columns=None, values=None)
”
参数含义
data:DataFrame对象index:可选,用于新DataFrame的索引columns:用于创建新DataFrame的列values:可选,用于填充新DataFrame的值
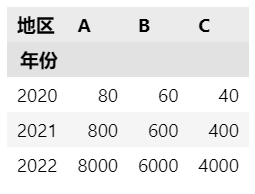
用上面的结果举个例子:
df.pivot(index='年份', columns='地区', values='销售额')
也可以写成以下格式。
df.pivot(index='年份', columns='地区')['销售额']
添加一个销量列,同时统计两个values,这样会使columns变成多层索引。
df['销量'] = df['销售额']/10 df.pivot(index='年份', columns='地区', values=['销售额', '销量'])

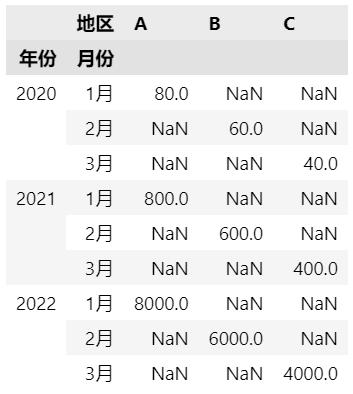
添加一个月份列,指定两个index。
df['月份'] = [f'{m}月' for m in range(1, 4)]*3
df.pivot(index=['年份', '月份'],
columns='地区',
values='销售额')
使用pivot时需要注意,当index,columns出现重复时,会导致ValueError。
df = pd.DataFrame(
{'地区': ['A', 'A', 'B', 'C'],
'年份': ['2020', '2020', '2021', '2022'],
'销售额': [800, 600, 400, 200]})

df.pivot(index='地区', columns='年份', values='销售额') # ValueError
pandas.pivot_table()
这个函数之前已经单独讲过了,详见Pandas玩转数据透视表,相比于pivot,pivot_table的灵活性更强。
pandas.crosstab()
crosstab函数计算两个(或多个)数组的简单交叉表。默认情况下计算元素的频率表。
“
pandas.crosstab(index, columns, values=None, rownames=None, colnames=None, aggfunc=None, margins=False, margins_name='All', dropna=True, normalize=False)
”
看下例子:
这里默认计算频率。
import numpy as np array_A = np.array(["one", "two", "two", "three", "three", "three"], dtype=object) array_B = np.array(["Python", "Python", "Python", "C", "C", "C"], dtype=object) array_C = np.array(["Y", "Y", "Y", "N", "N", "N"]) pd.crosstab(array_A, [array_B, array_C], rownames=['array_A'], colnames=['array_B', 'array_C'])

新建一个values列,计算总和。
array_D = np.array([1, 4, 9, 16, 25, 36]) pd.crosstab(index=array_A, columns=[array_B, array_C], rownames=['array_A'], colnames=['array_B', 'array_C'], values=array_D, aggfunc='sum')

到此这篇关于一文搞懂Pandas数据透视的4个函数的使用的文章就介绍到这了,更多相关Pandas数据透视内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

python 用pandas实现数据透视表功能
透视表是一种可以对数据动态排布并且分类汇总的表格格式.对于熟练使用 excel 的伙伴来说,一定很是亲切! pd.pivot_table() 语法: pivot_table(data, # DataFrame values=None, # 值 index=None, # 分类汇总依据 columns=None, # 列 aggfunc='mean', # 聚合函数 fill_value=None, # 对缺失值的填充 margins=False, # 是否启用总计行/列 dropna=True,
-
Pandas使用stack和pivot实现数据透视的方法
目录 前言 一.经过统计得到多维度指标数据 二.使用unstack实现数据的二维透视 三.使用pivot简化透视 四.stack.unstack.pivot的语法 1.stack 2.unstack 3.pivot 总结 前言 笔者最近正在学习Pandas数据分析,将自己的学习笔记做成一套系列文章.本节主要记录Pandas中使用stack和pivot实现数据透视. 一.经过统计得到多维度指标数据 非常场景的统计场景,指定多个维度,计算聚合后的指标 实例:统计得到"电影评分数据集",每个
-
用Python实现数据的透视表的方法
在处理数据时,经常需要对数据分组计算均值或者计数,在Microsoft Excel中,可以通过透视表轻易实现简单的分组运算.而对于更加复杂的分组运算,Python中pandas包可以帮助我们实现. 1 数据 首先引入几个重要的包: import pandas as pd import numpy as np from pandas import DataFrame,Series 通过代码构造数据集: data=DataFrame({'key1':['a','b','c','a','c','a',
-
Python+Pandas实现数据透视表
目录 导入示例数据 参数说明 常用操作 大家好,我是丁小杰. 对于数据透视表,相信对于 Excel 比较熟悉的小伙伴都知道如何使用它,并了解它的强大之处,而在pandas中要实现数据透视就要用到pivot_table了. 导入示例数据 首先导入演示的数据集. import pandas as pd df = pd.read_csv('销售目标.csv') df.head() 参数说明 主要参数: data:待操作的 DataFrame values:被聚合操作的列,可选项 index:行分组键,
-
Python实现数据透视表详解
目录 1.groupby + agg 2. crosstab 3.groupby + pivot pivot_table 总结 用Python里的Pandas可以实现,虽然感觉Excel更方便 1.groupby + agg 不够直观,不好看 对贷款年份,贷款种类创建数据透视 train_data.groupby(['year_of_loan', 'class']).agg(d_roat =('isDefault', 'mean')) 2. crosstab pandas.crosstab(in
-
一文搞懂Pandas数据透视的4个函数的使用
目录 pandas.melt() pandas.pivot() pandas.pivot_table() pandas.crosstab() 大家好,我是丁小杰! 今天和大家分享Pandas中四种有关数据透视的通用函数,在数据处理中遇到这类需求时,能够很好地应对. pandas.melt() melt函数的主要作用是将DataFrame从宽格式转换成长格式. “ pandas.melt(frame,id_vars=None, value_vars=None, var_name=None, val
-
一文搞懂Python中pandas透视表pivot_table功能详解
目录 一.概述 1.1 什么是透视表? 1.2 为什么要使用pivot_table? 二.如何使用pivot_table 2.1 读取数据 2.2Index 2.3Values 2.4Aggfunc 2.5Columns 一文看懂pandas的透视表pivot_table 一.概述 1.1 什么是透视表? 透视表是一种可以对数据动态排布并且分类汇总的表格格式.或许大多数人都在Excel使用过数据透视表,也体会到它的强大功能,而在pandas中它被称作pivot_table. 1.2 为什么要使用
-
一文搞懂Python中pandas透视表pivot_table功能
目录 一.概述 1.1 什么是透视表? 1.2 为什么要使用pivot_table? 二.如何使用pivot_table 2.1 读取数据 2.2Index 2.3Values 2.4Aggfunc 2.5Columns 一文看懂pandas的透视表pivot_table 一.概述 1.1 什么是透视表? 透视表是一种可以对数据动态排布并且分类汇总的表格格式.或许大多数人都在Excel使用过数据透视表,也体会到它的强大功能,而在pandas中它被称作pivot_table. 1.2 为什么要使用
-
一文搞懂Python中Pandas数据合并
目录 1.concat() 主要参数 示例 2.merge() 参数 示例 3.append() 参数 示例 4.join() 示例 数据合并是数据处理过程中的必经环节,pandas作为数据分析的利器,提供了四种常用的数据合并方式,让我们看看如何使用这些方法吧! 1.concat() concat() 可用于两个及多个 DataFrame 间行/列方向进行内联或外联拼接操作,默认对行(沿 y 轴)取并集. 使用方式 pd.concat( objs: Union[Iterable[~FrameOr
-
一文搞懂Python Sklearn库使用
目录 1.LabelEncoder 2.OneHotEncoder 3.sklearn.model_selection.train_test_split随机划分训练集和测试集 4.pipeline 5 perdict 直接返回预测值 6 sklearn.metrics中的评估方法 7 GridSearchCV 8 StandardScaler 9 PolynomialFeatures 4.10+款机器学习算法对比 4.1 生成数据 4.2 八款主流机器学习模型 4.3 树模型 - 随机森林 4.
-
一文搞懂ES6中的Map和Set
Map Map对象保存键值对.任何值(对象或者原始值) 都可以作为一个键或一个值.构造函数Map可以接受一个数组作为参数. Map和Object的区别 •一个Object 的键只能是字符串或者 Symbols,但一个Map 的键可以是任意值. •Map中的键值是有序的(FIFO 原则),而添加到对象中的键则不是. •Map的键值对个数可以从 size 属性获取,而 Object 的键值对个数只能手动计算. •Object 都有自己的原型,原型链上的键名有可能和你自己在对象上的设置的键名产生冲突.
-
一文搞懂C++ 动态内存
了解动态内存在 C++ 中是如何工作的是成为一名合格的 C++ 程序员必不可少的.C++ 程序中的内存分为两个部分: 栈:在函数内部声明的所有变量都将占用栈内存. 堆:这是程序中未使用的内存,在程序运行时可用于动态分配内存. 很多时候,您无法提前预知需要多少内存来存储某个定义变量中的特定信息,所需内存的大小需要在运行时才能确定. 在 C++ 中,您可以使用特殊的运算符为给定类型的变量在运行时分配堆内的内存,这会返回所分配的空间地址.这种运算符即new 运算符. 如果您不再需要动态分配的内存空间,
-
一文搞懂JAVA 修饰符
Java语言提供了很多修饰符,主要分为以下两类: 访问修饰符 非访问修饰符 修饰符用来定义类.方法或者变量,通常放在语句的最前端.我们通过下面的例子来说明: public class ClassName { // ... } private boolean myFlag; static final double weeks = 9.5; protected static final int BOXWIDTH = 42; public static void main(String[] argum
-
一文搞懂C# 数据类型
在 C# 中,变量分为以下几种类型: 值类型(Value types) 引用类型(Reference types) 指针类型(Pointer types) 值类型(Value types) 值类型变量可以直接分配给一个值.它们是从类 System.ValueType 中派生的. 值类型直接包含数据.比如 int.char.float,它们分别存储数字.字符.浮点数.当您声明一个 int 类型时,系统分配内存来存储值. 下表列出了 C# 2010 中可用的值类型: 类型 描述 范围 默认值 boo
-
如何使用IDEA开发Spark SQL程序(一文搞懂)
目录 前言 Spark SQL是什么 1.使用IDEA开发Spark SQL 1.1.指定列名添加Schema 1.2.通过StructType指定Schema 1.3.反射推断Schema–掌握 1.4.花式查询 1.5. 相互转化 1.6.Spark SQL完成WordCount(案例) 1.6.1.SQL风格 1.6.2.DQL风格 前言 大家好,我是DJ丶小哪吒,我又来跟你们分享知识了.对软件开发有着浓厚的兴趣.喜欢与人分享知识.做博客的目的就是为了能与 他 人知识共享.由于水平有限.博