Windows下使用IDEA搭建Hadoop开发环境的详细方法
笔者鼓弄了两个星期,终于把所有有关hadoop的环境配置好了,一是虚拟机上的 完全分布式集群 ,但是为了平时写代码的方便,则在windows上也配置了hadoop的 伪分布式集群 ,同时在IDEA上就可以编写代码,同时在windows环境下进行运行。(如果不配置windows下的伪分布式集群,则在IDEA上编写的代码无法在windows平台下运行)。笔者在网络上找了很多有关windows下使用idea搭建hadoop开发环境的中文教程都不太全,最后使用国外的英文教程配置成功,因此这里整理一下,方便大家使用。
我的开发环境如下:
1.Windows10
2.Java 8
3.VMware-workstation-pro
1.Hadoop在windows当中的安装
首先在Windows系统里打开浏览器,下载hadoop的安装包(二进制文件): http://hadoop.apache.org/releases.html
打开网址,我们会发现这样的界面:

由于hadoop在开发当中我们常常使用了2.x版本的,因此这里我们这里下载2.10.1版本的。如果你想使用其他版本的进行下载,那么在下载之前需要检查以下maven仓库里是否有相应版本所对应的版本,不然在使用IDEA进行开发的时候,则无法运行。我们打开网址:https://mvnrepository.com/
在其中搜索hadoop.则会出现以下的界面:

鼠标往下滑动,发现果然!2.10.1的版本出现了!因此我们可以使用找个版本的hadoop,因为在maven仓库里是可以找到的,这样就不会出现无法编程调用hadoop的问题:

2.将下载的文件进行解压
我们下载之后的文件二进制文件后缀名为tar.gz,你可以来到你下载的地方,使用windows下的压缩包软件直接进行解压,我使用的是2345压缩软件进行的解压。有些教程让我们必须在windows下模拟的linux环境下(MinGW)才能够解压,其实完全不用,就把tar.gz当作普通的压缩文件就好了,解压之后将文件夹更名为hadoop。
3.设置环境变量 一方面是要设置好Java的环境变量 另一方面是要设置好刚刚下载的Hadoop的环境变量
我们在环境变量处分别设置JAVA_HOME和HADOOP_HOME(目的是为了hadoop在运行的时候能够找到自己和java的地方在哪儿):

然后在Path里添加JAVA和hadoop的二进制文件夹,bin文件夹,目的是我们这样就可以使用cmd对java和haodoop进行操作:
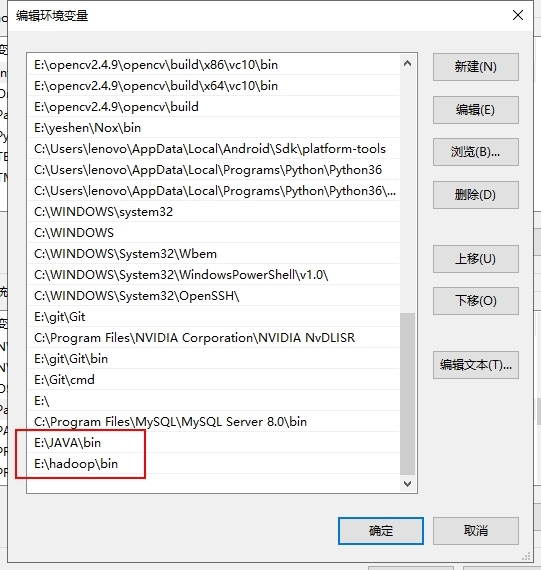
4.验证环境变量的配置
打开你的cmd,输入以下命令,出现我这样的输出说明配置环境变量成功:
C:\Users\lenovo>hadoop -version java version "1.8.0_162" Java(TM) SE Runtime Environment (build 1.8.0_162-b12) Java HotSpot(TM) 64-Bit Server VM (build 25.162-b12, mixed mode)
5.HDFS的配置
接下来就是配置HDFS的文件,进行伪分布式集群以适应你的计算机。(备注:伪分布式集群也是分布式集群,可以起动分布式计算的效果)
我们来到之前解压的hadoop文件夹下,打开etc/hadoop文件夹,发现里面有很多文件:

现在我们的任务就是修改这些文件当中的代码,务必修改,不然根本无法运行hadoop!!
6.修改 hadoop-env.cmd
打开这个文件,在找个文件当中的末尾添加上:
set HADOOP_PREFIX=%HADOOP_HOME% set HADOOP_CONF_DIR=%HADOOP_PREFIX%\etc\hadoop set YARN_CONF_DIR=%HADOOP_CONF_DIR% set PATH=%PATH%;%HADOOP_PREFIX%\bin
7.修改core-site.xml
将configuration处更改为:
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://0.0.0.0:9000</value> </property> </configuration>
8.hdfs-site.xml
将configuration处更改为如下所示,其中
file:///F:/DataAnalytics/dfs/namespace_logs file:///F:/DataAnalytics/dfs/data
这两个文件夹一定需要是已经存在的文件夹,你可以在你的hadoop文件夹下随意创建两个文件夹,然后将下面的这两个文件夹的绝对路径替换成你的文件夹,这里我也是创建了两个新的文件夹,hadoop的下载文件夹里本身是没有的。
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.name.dir</name> <value>file:///F:/DataAnalytics/dfs/namespace_logs</value> </property> <property> <name>dfs.data.dir</name> <value>file:///F:/DataAnalytics/dfs/data</value> </property> </configuration>
9. mapred-site.xml
将下方的%USERNAME%替换成你windows的用户名!!!这个十分重要,不要直接复制!!!
<configuration> <property> <name>mapreduce.job.user.name</name> <value>%USERNAME%</value> </property> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>yarn.apps.stagingDir</name> <value>/user/%USERNAME%/staging</value> </property> <property> <name>mapreduce.jobtracker.address</name> <value>local</value> </property> </configuration>
10.yarn-site.xml
修改为如下所示:
<configuration> <property> <name>yarn.server.resourcemanager.address</name> <value>0.0.0.0:8020</value> </property> <property> <name>yarn.server.resourcemanager.application.expiry.interval</name> <value>60000</value> </property> <property> <name>yarn.server.nodemanager.address</name> <value>0.0.0.0:45454</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> <property> <name>yarn.server.nodemanager.remote-app-log-dir</name> <value>/app-logs</value> </property> <property> <name>yarn.nodemanager.log-dirs</name> <value>/dep/logs/userlogs</value> </property> <property> <name>yarn.server.mapreduce-appmanager.attempt-listener.bindAddress</name> <value>0.0.0.0</value> </property> <property> <name>yarn.server.mapreduce-appmanager.client-service.bindAddress</name> <value>0.0.0.0</value> </property> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <property> <name>yarn.log-aggregation.retain-seconds</name> <value>-1</value> </property> <property> <name>yarn.application.classpath</name> <value>%HADOOP_CONF_DIR%,%HADOOP_COMMON_HOME%/share/hadoop/common/*,%HADOOP_COMMON_HOME%/share/hadoop/common/lib/*,%HADOOP_HDFS_HOME%/share/hadoop/hdfs/*,%HADOOP_HDFS_HOME%/share/hadoop/hdfs/lib/*,%HADOOP_MAPRED_HOME%/share/hadoop/mapreduce/*,%HADOOP_MAPRED_HOME%/share/hadoop/mapreduce/lib/*,%HADOOP_YARN_HOME%/share/hadoop/yarn/*,%HADOOP_YARN_HOME%/share/hadoop/yarn/lib/*</value> </property> </configuration>
11.初始化环境变量
在windows下的cmd,输入cmd的命令,用于初始化环境变量。hadoop-env.cmd后缀为cmd,说明是cmd下可执行的文件:
%HADOOP_HOME%\etc\hadoop\hadoop-env.cmd
12.格式化文件系统(File System)
这个命令在整个hadoop的配置环境和之后的使用当中务必仅使用一次!!!!不然的话后续会导致hadoop日志损坏,NameNode无法开启,整个hadoop就挂了!
将如下的命令输入到cmd当中进行格式化:
hadoop namenode -format
输出:
2018-02-18 21:29:41,501 INFO namenode.FSImage: Allocated new BlockPoolId: BP-353327356-172.24.144.1-1518949781495
2018-02-18 21:29:41,817 INFO common.Storage: Storage directory F:\DataAnalytics\dfs\namespace_logs has been successfully formatted.
2018-02-18 21:29:41,826 INFO namenode.FSImageFormatProtobuf: Saving image file F:\DataAnalytics\dfs\namespace_logs\current\fsimage.ckpt_0000000000000000000 using no compression
2018-02-18 21:29:41,934 INFO namenode.FSImageFormatProtobuf: Image file F:\DataAnalytics\dfs\namespace_logs\current\fsimage.ckpt_0000000000000000000 of size 390 bytes saved in 0 seconds.
2018-02-18 21:29:41,969 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0
13.向hadoop文件当中注入winutills文件
由于windows下想要开启集群,会有一定的bug,因此我们去网站:https://github.com/steveloughran/winutils
下载对应版本的 winutils.exe 文件。打开这个Github仓库后如下所示:

我们打开hadoop2.8.3/bin,选择其中的 winutils.exe 文件进行下载,然后将下载的这个文件放入到本地的hadoop/bin文件当中。不然的话,你打开一会儿你的伪分布式集群,马上hadoop就会自动关闭,缺少这两个文件的话。
我本地的bin文件最终如下所示:

14.开启hadoop集群
下面就是最激动人心的开启hadoop集群了!!!!我们在cmd当中输入:
C:\Users\lenovo>%HADOOP_HOME%/sbin/start-all.cmd This script is Deprecated. Instead use start-dfs.cmd and start-yarn.cmd starting yarn daemons
这样就会跳出来很多黑色的窗口,如下所示:

然后可以使用JPS工具查看目前开启的node有哪些,如果出现namenode,datanode的话说明集群基本上就成功了。如下所示:

15.打开本地浏览器进行验证
我们在浏览器输入localhost:50070,如果能够打开这样的网页,说明hadoop已经成功开启:

接下来就可以开始IDEA的配置了
16.创建MAVEN项目工程
打开IDEA之后,里面的参数和项目工程名称随便写,等待工程创建完毕即可。然后我们编辑pom.xml文件,如下所示:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.atguigu</groupId>
<artifactId>hdfs1205</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>RELEASE</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.8.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.10.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.10.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.10.1</version>
</dependency>
</dependencies>
</project>
因为我使用了2.10.1版本,因此导入的包均为2.10.1,除了log4j,这个是固定的2.8.2版本的。
然后点击我箭头指向的同步maven仓库,如下所示:

同步完成之后,IDEA左边的external libararies处就会显示大量的有关hadoop的jar包,如下所示:

这样就说明我们导入maven仓库成功了。
17.编写代码
现在我们开始编写代码,在开启hadoop伪分布式集群之后,代码才可以运行哦!
代码如下所示:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.net.URI;
public class Test {
public static void main(String[] args) throws Exception {
FileSystem fs = FileSystem.get(new URI("hdfs://127.0.0.1:9000"), new Configuration());
FileStatus[] files = fs.listStatus(new Path("/"));
for (FileStatus f : files) {
System.out.println(f);
}
System.out.println("Compile Over");
}
}
这段代码的含义是遍历hadoop文件系统(HDFS)下的root下所有文件的状态,并输出,由于我目前并没有在HDFS下put了任何文件,因此不会有输出,出现这样的输出,说明代码代码运行成功:

exit code 0,返回code为0说明运行成功!
到此这篇关于Windows下使用IDEA搭建Hadoop开发环境的文章就介绍到这了,更多相关IDEA搭建Hadoop开发环境内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
IDEA快速搭建Java开发环境的教程图解
作为IntelliJ IDEA mac新手,IDEA如何快速搭建Java开发环境呢? 今天小编就给大家带来了IntelliJ IDEA mac使用教程,想知道IDEA如何快速搭建Java开发环境?那就一起来看看吧! 全局JDK(默认配置) 具体步骤:顶部工具栏 File ->Other Settins -> Default Project Structure -> SDKs -> JDK 示例: 根据下图步骤设置JDK目录,最后点击OK保存. 注:SDKs全称是Software D
-
使用IntelliJ IDEA 配置安卓(Android)开发环境的教程详解(新手必看)
上移动端的测试课,老师和同学们用的都是eclipse, 只有我一个人用的是idea(用了两款软件之后觉得IDEA更好),真的太难了,配置环境就只有一个人孤军奋战了,自己选择的路,爬都要爬完,害! 有大佬推荐我用Android studio,去了解了一下,这个软件也不错,考虑到已经用了IDEA那就用吧. 操作环境和基本配置 操作环境:Win 10 基本环境配置:Java 1.8 基本工具:IDEA(自行下载安装购买,支持正版!) 一.jdk的下载安装与配置 1.1下载安装 jdk的官网下载
-

eclipse/intellij idea 远程调试hadoop 2.6.0
很多hadoop初学者估计都我一样,由于没有足够的机器资源,只能在虚拟机里弄一个linux安装hadoop的伪分布,然后在host机上win7里使用eclipse或Intellj idea来写代码测试,那么问题来了,win7下的eclipse或intellij idea如何远程提交map/reduce任务到远程hadoop,并断点调试? 一.准备工作 1.1 在win7中,找一个目录,解压hadoop-2.6.0,本文中是D:\yangjm\Code\study\hadoop\hadoop-2.
-
在IDEA中安装scala、maven、hadoop遇到的问题小结
小白在通过IDEA使用scala.maven.hadoop遇到的问题 问题一:idea new 新文件没有scala:File->setting->Plugins,然后搜索scala插件安装.安装完成后重启idea.然后设置Scala sdk: File->Project Structure->Libraries->+ 问题二:Maven的的导入时mvn不是内部或外部命令-:这是环境变量没有配置好,下图附环境变量: 在D:\maven\apache-maven-3.6.1\c
-
Intellij IDEA + Android SDK + Genymotion Emulator打造最佳Android开发环境
一直使用Eclipse环境开发Android,也尝鲜使用过Android Studio去开发,各种IDE配合Android SDK及SDK原生的Android Emulator的个中滋味也许大家都有领略,Eclipse的超长启动时间似乎是在与Android Emulator这个超级大腕比看谁更姗姗来迟,Android Studio的大版本号从推出来到两年后的今天仍然一直游走在1之下,不的不说襁褓婴儿不知道什么时候能长大,不得不说大哥我真不敢用你. 本文则介绍Lorinnn在开发Android过程
-
Windows下使用IDEA搭建Hadoop开发环境的详细方法
笔者鼓弄了两个星期,终于把所有有关hadoop的环境配置好了,一是虚拟机上的 完全分布式集群 ,但是为了平时写代码的方便,则在windows上也配置了hadoop的 伪分布式集群 ,同时在IDEA上就可以编写代码,同时在windows环境下进行运行.(如果不配置windows下的伪分布式集群,则在IDEA上编写的代码无法在windows平台下运行).笔者在网络上找了很多有关windows下使用idea搭建hadoop开发环境的中文教程都不太全,最后使用国外的英文教程配置成功,因此这里整理一下,方
-
使用IDEA搭建Hadoop开发环境的操作步骤(Window10为例)
下载安装Hadoop 下载安装包 进入官网下载下载hadoop的安装包(二进制文件)http://hadoop.apache.org/releases.html 我们这里下载2.10.1版本的,如果想下载更高版本的请先去maven仓库查看是否有对应版本 解压文件 下载好的.gz文件可以直接解压. winRAR和Bandizip都可以用来解压,但是注意必须以管理员身份打开解压软件,否则会出现解压错误 配置环境变量 配置JAVA_HOME和HADOOP_HOME 我们在环境变量处分别设置JAVA_H
-
vscode搭建STM32开发环境的详细过程
需要安装的软件 vscode 必装插件: C/C++:用于提供高亮显示和代码补全 Cortex-Debug:用于提供调试配置 make make工具可以直接下载xPack项目提供的windows-build-tools工具里面带了make工具. Release xPack Windows Build Tools v4.2.1-2 · xpack-dev-tools/windows-build-tools-xpack (github.com) openocd arm-none-eabi stm32
-
一步步教你搭建Scala开发环境(非常详细!)
目录 一.Scala开发环境搭建 1.1.安装scala 1.2.scala插件安装 1.2.1.在线安装 1.2.2.离线安装 1.3.Scala快速入门 1.创建一个maven项目 2.引入scala框架 3.创建项目的源文件目录 4.在scala下新建一个包 5.编写代码 1.4.关联scala源码 1.5.Scala API 总结 一.Scala开发环境搭建 1.1.安装scala 1.首先确保jdk是否安装成功 如果还未安装jdk,请猛戳这里–>JDK安装教程 2.下载对应的scala
-
openEuler 搭建java开发环境的详细过程
目录 1. 初始化环境 2. 安装jdk8 3. 安装SVN 4. 安装Git 5. 安装Node.js 6. 下载并激活IntelliJ IDEA 7. 下载并激活Navicat 本文操作系统及版本号:↓openEuler release 22.03 LTSLinux version 5.10.0-60.35.0.64.oe2203.x86 _64 1. 初始化环境 # 1. 更新依赖库 yum -y update # 2. 安装常用工具包 yum -y install wget tar vi
-
windows 32位eclipse远程hadoop开发环境搭建
本文假设hadoop环境在远程机器(如linux服务器上),hadoop版本为2.5.2 注:本文eclipse/intellij idea 远程调试hadoop 2.6.0主要参考了并在其基础上有所调整 由于我喜欢在win7 64位上安装32位的软件,比如32位jdk,32位eclipse,所以虽然本文中的操作系统是win7 64位,但是所有的软件都是32位的. 软件版本: 操作系统:win7 64位 eclipse: eclipse-jee-mars-2-win32 java: 1.8.0_
-
使用Maven搭建Hadoop开发环境
关于Maven的使用就不再啰嗦了,网上很多,并且这么多年变化也不大,这里仅介绍怎么搭建Hadoop的开发环境. 1. 首先创建工程 复制代码 代码如下: mvn archetype:generate -DgroupId=my.hadoopstudy -DartifactId=hadoopstudy -DarchetypeArtifactId=maven-archetype-quickstart -DinteractiveMode=false 2. 然后在pom.xml文件里添加hadoop的依赖
-
JSP动态网站开发环境配置详细方法第1/2页
下面就以Tomcat作为JSP引擎,配合Tomcat.Apache.IIS这三种Web服务器来讲述3种搭建JSP运行环境的方案. 一.相关软件介绍 1. J2SDK:Java2的软件开发工具,是Java应用程序的基础.JSP是基于Java技术的,所以配置JSP环境之前必须要安装J2SDK. 2. Apache服务器:Apache组织开发的一种常用Web服务器,提供Web服务. 3. Tomcat服务器:Apache组织开发的一种JSP引擎,本身具有Web服务器的功能,可以作为独立的Web服务器来
-
windows下apache搭建php开发环境
本文详细介绍了在Windows2003下使用Apache2.2.21/PHP5.3.5/Mysql5.5.19/phpMyAdmin3.4.9搭建php开发环境. 第一步:下载安装的文件 1. Apache 版本 httpd-2.2.21-win32-x86-no_ssl.msi 2. MySQL 版本 mysql-5.5.19-win32.msi 3. PHP 版本 php-5.3.5-Win32-VC6-x86.zip 4. phpMyadmin 版本 phpMyAdmin-3.4.9-al
-
Windows下搭建python开发环境详细步骤
本文为大家分享了Windows下搭建python开发环境详细步骤,供大家参考,具体内容如下 1.搭建Java环境 (1)直接从官网下载相应版本的JDK或者JRE并点击安装就可以 (2)JDK与JRE的区别: 1)JDK就是Java Development Kit.简单的说JDK是面向开发人员使用的SDK,它提供了Java的开发环境和运行环境.SDK是Software Development Kit 一般指软件开发包,可以包括函数库.编译程序等 2)JRE是Java Runtime Envirom