yolov5训练时参数workers与batch-size的深入理解
目录
- yolov5训练命令
- workers和batch-size参数的理解
- workers
- batch-size
- 两个参数的调优
- 总结
yolov5训练命令
python .\train.py --data my.yaml --workers 8 --batch-size 32 --epochs 100
yolov5的训练很简单,下载好仓库,装好依赖后,只需自定义一下data目录中的yaml文件就可以了。这里我使用自定义的my.yaml文件,里面就是定义数据集位置和训练种类数和名字。
workers和batch-size参数的理解
一般训练主要需要调整的参数是这两个:
workers
指数据装载时cpu所使用的线程数,默认为8。代码解释如下
parser.add_argument('--workers', type=int, default=8, help='max dataloader workers (per RANK in DDP mode)')
一般默使用8的话,会报错~~。原因是爆系统内存,除了物理内存外,需要调整系统的虚拟内存。训练时主要看已提交哪里的实际值是否会超过最大值,超过了不是强退程序就是报错。
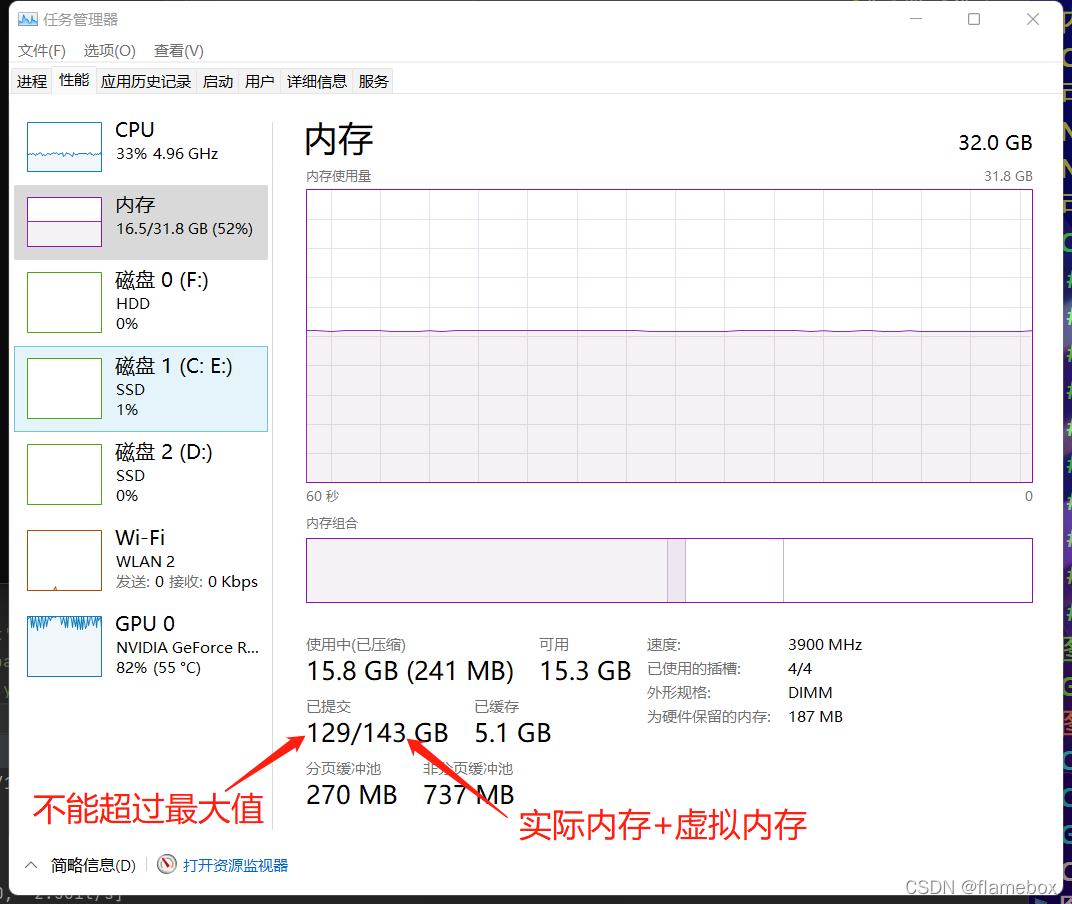
所以需要根据实际情况分配系统虚拟内存(python执行程序所在的盘)的最大值

batch-size
就是一次往GPU哪里塞多少张图片了。决定了显存占用大小,默认是16。
parser.add_argument('--batch-size', type=int, default=16, help='total batch size for all GPUs, -1 for autobatch')
训练时显存占用越大当然效果越好,但如果爆显存,也是会无法训练的。我使用–batch-size 32时,显存差不多能利用完。

两个参数的调优
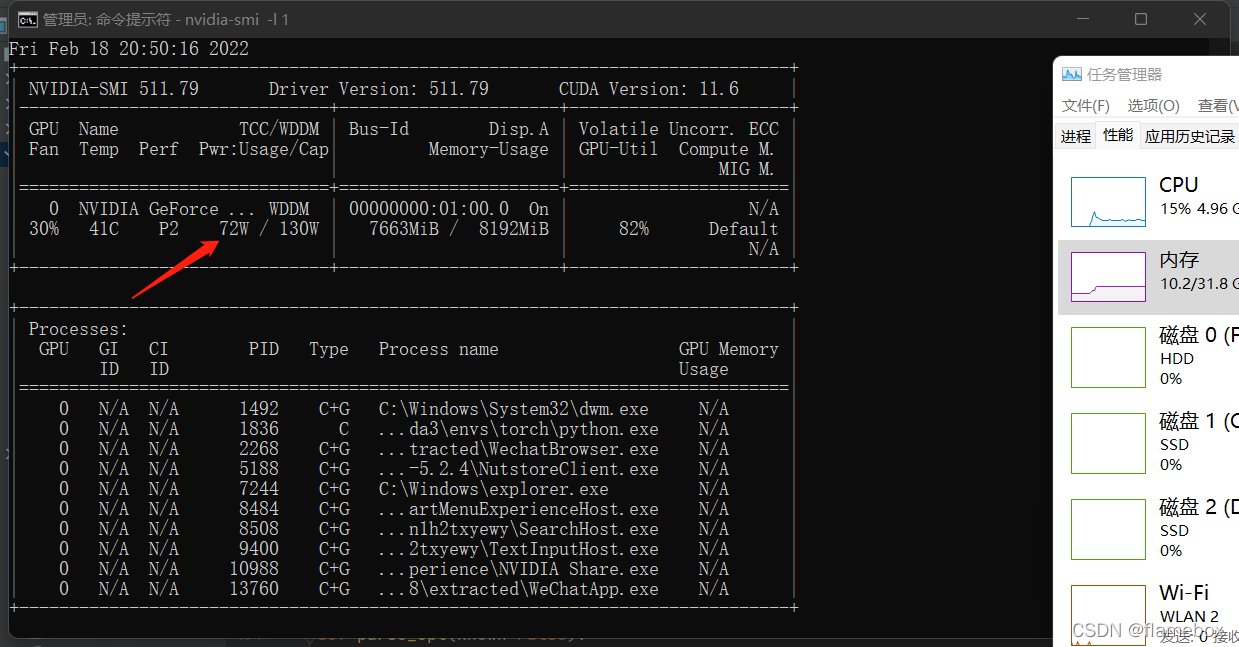
对于workers,并不是越大越好,太大时gpu其实处理不过来,训练速度一样,但虚拟内存(磁盘空间)会成倍占用。

workers为4时的内存占用

workers为8时的内存占用
我的显卡是rtx3050,实际使用中上到4以上就差别不大了,gpu完全吃满了。但是如果设置得太小,gpu会跑不满。比如当workers=1时,显卡功耗只得72W,速度慢了一半;workers=4时,显卡功耗能上到120+w,完全榨干了显卡的算力。所以需要根据你实际的算力调整这个参数。
2. 对于batch-size,有点玄学。理论是能尽量跑满显存为佳,但实际测试下来,发现当为8的倍数时效率更高一点。就是32时的训练效率会比34的高一点,这里就不太清楚原理是什么了,实际操作下来是这样。
总结
以上参数的调整能最大化显卡的使用效率,其中的具体数值和电脑的实际配置还有模型大小、数据集大小有关,需要根据实际情况反复调整。当然,要实质提升训练速度,还是得有好显卡(钞能力)~~~~
相关推荐
-

Yolov5训练意外中断后如何接续训练详解
目录 1.配置环境 2.问题描述 3.解决方法 3.1设置需要接续训练的结果 3.2设置训练代码 4.原理 5.结束语 1.配置环境 操作系统:Ubuntu20.04 CUDA版本:11.4 Pytorch版本:1.9.0 TorchVision版本:0.7.0 IDE:PyCharm 硬件:RTX2070S*2 2.问题描述 在训练YOLOv5时由于数据集很大导致训练时间十分漫长,这期间Python.主机等可能遇到死机的情况,如果需要训练300个epoch但是训练一晚后发现在200epoch时
-
yolov5训练时参数workers与batch-size的深入理解
目录 yolov5训练命令 workers和batch-size参数的理解 workers batch-size 两个参数的调优 总结 yolov5训练命令 python .\train.py --data my.yaml --workers 8 --batch-size 32 --epochs 100 yolov5的训练很简单,下载好仓库,装好依赖后,只需自定义一下data目录中的yaml文件就可以了.这里我使用自定义的my.yaml文件,里面就是定义数据集位置和训练种类数和名字. worke
-
对比分析BN和dropout在预测和训练时区别
目录 Batch Normalization Dropout Batch Normalization和Dropout是深度学习模型中常用的结构. 但BN和dropout在训练和测试时使用却不相同. Batch Normalization BN在训练时是在每个batch上计算均值和方差来进行归一化,每个batch的样本量都不大,所以每次计算出来的均值和方差就存在差异.预测时一般传入一个样本,所以不存在归一化,其次哪怕是预测一个batch,但batch计算出来的均值和方差是偏离总体样本的,所以通常是
-
Keras框架中的epoch、bacth、batch size、iteration使用介绍
1.epoch Keras官方文档中给出的解释是:"简单说,epochs指的就是训练过程接中数据将被"轮"多少次" (1)释义: 训练过程中当一个完整的数据集通过了神经网络一次并且返回了一次,这个过程称为一个epoch,网络会在每个epoch结束时报告关于模型学习进度的调试信息. (2)为什么要训练多个epoch,即数据要被"轮"多次 在神经网络中传递完整的数据集一次是不够的,对于有限的数据集(是在批梯度下降情况下),使用一个迭代过程,更新权重一
-
记录模型训练时loss值的变化情况
记录训练过程中的每一步的loss变化 if verbose and step % verbose == 0: sys.stdout.write('\r{} / {} : loss = {}'.format( step, total_steps, np.mean(total_loss))) sys.stdout.flush() if verbose: sys.stdout.write('\r') sys.stdout.flush() 一般我们在训练神经网络模型的时候,都是每隔多少步,输出打印一下l
-
SQL SERVER使用ODBC 驱动建立的链接服务器调用存储过程时参数不能为NULL值
我们知道SQL SERVER建立链接服务器(Linked Server)可以选择的驱动程序非常多,最近发现使用ODBC 的 Microsoft OLE DB 驱动程序建立的链接服务器(Linked Server), 调用存储过程过程时,参数不能为NULL值. 否则就会报下面错误提示: 对应的英文错误提示为: EXEC xxx.xxx.dbo.Usp_Test NULL,NULL,'ALL' Msg 7213, Level 16, State 1, Line 1 The attempt by th
-
Python定义函数时参数有默认值问题解决
这篇文章主要介绍了Python定义函数时参数有默认值问题解决,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 在定义函数的时候,如果函数的参数有默认值,有两种类型的参数,一种是整数,字符串这种不可变类型,另一种是列表这种可变类型,对于第一种情况没有什么特殊的地方,但是对于可变类型,有一个微妙的小陷阱. 可变类型以及小陷阱: def append_item(item, list1=[]): list1.append(item) return lis
-
解决tensorflow训练时内存持续增加并占满的问题
记录一次小白的tensorflow学习过程,也为有同样困扰的小白留下点经验. 先说我出错和解决的过程.在做风格迁移实验时,使用预加载权重的VGG19网络正向提取中间层结果,结果因为代码不当,在遍历图片提取时内存持续增长,导致提取几十个图片的特征内存就满了. 原因是在对每一张图片正向传播结束后,都会在留下中间信息.具体地说是在我将正向传播的代码与模型的代码分离了,在每次遍历图片时都会正向传播,在tensorflow中新增加了很多的计算节点(如tf.matmul等等),导致内存中遗留了大量的过期信息
-
tensorflow 固定部分参数训练,只训练部分参数的实例
在使用tensorflow来训练一个模型的时候,有时候需要依靠验证集来判断模型是否已经过拟合,是否需要停止训练. 1.首先想到的是用tf.placeholder()载入不同的数据来进行计算,比如 def inference(input_): """ this is where you put your graph. the following is just an example. """ conv1 = tf.layers.conv2d(inp
-
postman中POST请求时参数包含参数list设置方式
如下所示: 图中params包含多个参数,具体如下: {"rzrq":"2019-01-21","rzlx":"1","nr":"","jsonStr":"[{'gzlx':'1','gznr':'11','gzcg':'11','czwt':'11','yjjy':'11','rzgl_id':'','px':1},{'gzlx':'1','gznr':'