简单学习Python多进程Multiprocessing
1.1 什么是 Multiprocessing
多线程在同一时间只能处理一个任务。
可把任务平均分配给每个核,而每个核具有自己的运算空间。
1.2 添加进程 Process
与线程类似,如下所示,但是该程序直接运行无结果,因为IDLE不支持多进程,在命令行终端运行才有结果显示
import multiprocessing as mp
def job(a,b):
print('abc')
if __name__=='__main__':
p1=mp.Process(target=job,args=(1,2))
p1.start()
p1.join()
1.3 存储进程输出 Queue
不知道为什么下面的这个程序可以在IDLE中正常运行。首先定义了一个job函数作系列数学运算,然后将结果放到res中,在main函数运行,取出queue中存储的结果再进行一次加法运算。
import multiprocessing as mp def job(q): res=0 for i in range(1000): res+=i+i**2+i**3 q.put(res) if __name__ == '__main__': q=mp.Queue() p1 = mp.Process(target=job,args=(q,))#注意当参数只有一个时,应加上逗号 p2 = mp.Process(target=job,args=(q,)) p1.start() p2.start() p1.join() p2.join() res1=q.get() res2=q.get() print(res1+res2)
结果如下所示:

1.4 效率比对 threading & multiprocessing
在job函数中定义了数学运算,比较正常情况、多线程和多进程分别的运行时间。
import multiprocessing as mp
import threading as td
import time
def job(q):
res = 0
for i in range(10000000):
res += i+i**2+i**3
q.put(res) # queue
def multicore():
q = mp.Queue()
p1 = mp.Process(target=job, args=(q,))
p2 = mp.Process(target=job, args=(q,))
p1.start()
p2.start()
p1.join()
p2.join()
res1 = q.get()
res2 = q.get()
print('multicore:' , res1+res2)
def normal():
res = 0
for _ in range(2):#线程或进程都构造了两个,进行了两次运算,所以这里循环两次
for i in range(10000000):
res += i+i**2+i**3
print('normal:', res)
def multithread():
q = mp.Queue()
t1 = td.Thread(target=job, args=(q,))
t2 = td.Thread(target=job, args=(q,))
t1.start()
t2.start()
t1.join()
t2.join()
res1 = q.get()
res2 = q.get()
print('multithread:', res1+res2)
if __name__ == '__main__':
st = time.time()
normal()
st1= time.time()
print('normal time:', st1 - st)
multithread()
st2 = time.time()
print('multithread time:', st2 - st1)
multicore()
print('multicore time:', time.time()-st2)
在视频中的运行结果是多进程<正常<多线程,而我的运行结果为下图所示:
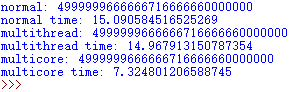
综上,多核/多进程运行最快,说明在同时间运行了多个任务,而多线程却不一定会比正常情况下的运行来的快,这和多线程中的GIL有关。
1.5 进程池
进程池Pool,就是我们将所要运行的东西,放到池子里,Python会自行解决多进程的问题。
import multiprocessing as mp def job(x): return x*x def multicore(): pool=mp.Pool(processes=2)#定义一个Pool,并定义CPU核数量为2 res=pool.map(job,range(10)) print(res) res=pool.apply_async(job,(2,)) print(res.get()) multi_res=[pool.apply_async(job,(i,)) for i in range(10)] print([res.get()for res in multi_res]) if __name__=='__main__': multicore()
运行结果如下所示:

首先定义一个池子,有了池子之后,就可以让池子对应某一个函数,在上述代码中定义的pool对应job函数。我们向池子里丢数据,池子就会返回函数返回的值。 Pool和之前的Process的不同点是丢向Pool的函数有返回值,而Process的没有返回值。
接下来用map()获取结果,在map()中需要放入函数和需要迭代运算的值,然后它会自动分配给CPU核,返回结果

我们怎么知道Pool是否真的调用了多个核呢?我们可以把迭代次数增大些,然后打开CPU负载看下CPU运行情况
打开CPU负载(Mac):活动监视器 > CPU > CPU负载(单击一下即可)
Pool默认大小是CPU的核数,我们也可以通过在Pool中传入processes参数即可自定义需要的核数量。
Pool除了可以用map来返回结果之外,还可以用apply_async(),与map不同的是,只能传递一个值,只会放入一个核进行计算,但是传入值时要注意是可迭代的,所以在传入值后需要加逗号, 同时需要用get()方法获取返回值。所对应的代码为:
res=pool.apply_async(job,(2,)) print(res.get())
运行结果为4。
由于传入值是可以迭代的,则我们同样可以使用apply_async()来输出多个结果。如果在apply_async()中输入多个传入值:
res = pool.apply_async(job, (2,3,4,))
结果会报错:
TypeError: job() takes exactly 1 argument (3 given)
即apply_async()只能输入一组参数。
在此我们将apply_async()放入迭代器中,定义一个新的multi_res
multi_res = [pool.apply_async(job, (i,)) for i in range(10)]
同样在取出值时需要一个一个取出来
print([res.get() for res in multi_res])
apply用迭代器的运行结果与map取出的结果相同。
note:
(1)Pool默认调用是CPU的核数,传入processes参数可自定义CPU核数
(2)map() 放入迭代参数,返回多个结果
(3)apply_async()只能放入一组参数,并返回一个结果,如果想得到map()的效果需要通过迭代
1.6 共享内存 shared memory
只有通过共享内存才能让CPU之间进行交流。
通过Value将数据存储在一个共享的内存表中。
import multiprocessing as mp
value1 = mp.Value('i', 0)
value2 = mp.Value('d', 3.14)
其中,i和d表示数据类型。i为带符号的整型,d为双精浮点类型。更多数据类型可参考网址:https://docs.python.org/3/library/array.html
在多进程中有一个Array类,可以和共享内存交互,来实现进程之间共享数据。
和numpy中的不同,这里的Array只能是一维的,并且需要定义数据类型否则会报错。
array = mp.Array('i', [1, 2, 3, 4])
1.7 进程锁 Lock
首先是不加进程锁的运行情况,在下述代码中定义了共享变量v,定义了两个进程,均可对v进行操作。job函数的作用是每隔0.1s输出一次累加num的值,累加值num在两个进程中分别为1和3。
import multiprocessing as mp
import time
def job(v,num):
for _ in range(10):
time.sleep(0.1)#暂停0.1s,让输出效果更明显
v.value+=num #v.value获取共享变量值
print(v.value)
def multicore():
v=mp.Value('i',0)#定义共享变量
p1=mp.Process(target=job,args=(v,1))
p2=mp.Process(target=job,args=(v,3))
p1.start()
p2.start()
p1.join()
p2.join()
if __name__=='__main__':
multicore()
运行结果如下所示:

可以看到两个进程互相抢占共享内存v。
为了解决上述不同进程抢共享资源的问题,我们可以用加进程锁来解决。
首先需要定义一个进程锁:
l = mp.Lock() # 定义一个进程锁
然后将进程锁的信息传入各个进程中
p1 = mp.Process(target=job, args=(v,1,l)) # 需要将Lock传入 p2 = mp.Process(target=job, args=(v,3,l))
在job()中设置进程锁的使用,保证运行时一个进程的对锁内内容的独占
def job(v, num, l): l.acquire() # 锁住 for _ in range(5): time.sleep(0.1) v.value += num # v.value获取共享内存 print(v.value) l.release() # 释放
完整代码:
def job(v, num, l):
l.acquire() # 锁住
for _ in range(5):
time.sleep(0.1)
v.value += num # 获取共享内存
print(v.value)
l.release() # 释放
def multicore():
l = mp.Lock() # 定义一个进程锁
v = mp.Value('i', 0) # 定义共享内存
p1 = mp.Process(target=job, args=(v,1,l)) # 需要将lock传入
p2 = mp.Process(target=job, args=(v,3,l))
p1.start()
p2.start()
p1.join()
p2.join()
if __name__ == '__main__':
multicore()
运行结果如下所示:

可以看到进程1运行完之后才运行进程2。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-

Python标准库之多进程(multiprocessing包)介绍
在初步了解Python多进程之后,我们可以继续探索multiprocessing包中更加高级的工具.这些工具可以让我们更加便利地实现多进程. 进程池 进程池 (Process Pool)可以创建多个进程.这些进程就像是随时待命的士兵,准备执行任务(程序).一个进程池中可以容纳多个待命的士兵. "三个进程的进程池" 比如下面的程序: 复制代码 代码如下: import multiprocessing as mul def f(x): return x**2 pool = mul.
-
Python使用multiprocessing实现一个最简单的分布式作业调度系统
mutilprocess像线程一样管理进程,这个是mutilprocess的核心,他与threading很是相像,对多核CPU的利用率会比threading好的多. 介绍 Python的multiprocessing模块不但支持多进程,其中managers子模块还支持把多进程分布到多台机器上.一个服务进程可以作为调度者,将任务分布到其他多个机器的多个进程中,依靠网络通信. 想到这,就在想是不是可以使用此模块来实现一个简单的作业调度系统. 实现 Job 首先创建一个Job类,为了测试简单,只包含一
-
Python multiprocessing模块中的Pipe管道使用实例
multiprocessing.Pipe([duplex]) 返回2个连接对象(conn1, conn2),代表管道的两端,默认是双向通信.如果duplex=False,conn1只能用来接收消息,conn2只能用来发送消息.不同于os.open之处在于os.pipe()返回2个文件描述符(r, w),表示可读的和可写的 实例如下: 复制代码 代码如下: #!/usr/bin/python #coding=utf-8 import os from multiprocessing import P
-
Python多进程multiprocessing用法实例分析
本文实例讲述了Python多进程multiprocessing用法.分享给大家供大家参考,具体如下: mutilprocess简介 像线程一样管理进程,这个是mutilprocess的核心,他与threading很是相像,对多核CPU的利用率会比threading好的多. 简单的创建进程: import multiprocessing def worker(num): """thread worker function""" print 'Wor
-
python基于multiprocessing的多进程创建方法
本文实例讲述了python基于multiprocessing的多进程创建方法.分享给大家供大家参考.具体如下: import multiprocessing import time def clock(interval): while True: print ("the time is %s"% time.time()) time.sleep(interval) if __name__=="__main__": p = multiprocessing.Process
-
Python使用multiprocessing创建进程的方法
本文实例讲述了Python使用multiprocessing创建进程的方法.分享给大家供大家参考.具体分析如下: 进程可以通过调用multiprocessing的Process进行创建,下面代码创建两个进程. [root@localhost ~]# cat twoproces.py #!/usr/bin/env python from multiprocessing import Process import os def output(): print "My pid is :%d\n&quo
-
Python多进程并发(multiprocessing)用法实例详解
本文实例讲述了Python多进程并发(multiprocessing)用法.分享给大家供大家参考.具体分析如下: 由于Python设计的限制(我说的是咱们常用的CPython).最多只能用满1个CPU核心. Python提供了非常好用的多进程包multiprocessing,你只需要定义一个函数,Python会替你完成其他所有事情.借助这个包,可以轻松完成从单进程到并发执行的转换. 1.新建单一进程 如果我们新建少量进程,可以如下: import multiprocessing import t
-
Python multiprocessing.Manager介绍和实例(进程间共享数据)
Python中进程间共享数据,处理基本的queue,pipe和value+array外,还提供了更高层次的封装.使用multiprocessing.Manager可以简单地使用这些高级接口. Manager()返回的manager对象控制了一个server进程,此进程包含的python对象可以被其他的进程通过proxies来访问.从而达到多进程间数据通信且安全. Manager支持的类型有list,dict,Namespace,Lock,RLock,Semaphore,BoundedSemaph
-
python使用multiprocessing模块实现带回调函数的异步调用方法
本文实例讲述了python使用multiprocessing模块实现带回调函数的异步调用方法.分享给大家供大家参考.具体分析如下: multipressing模块是python 2.6版本加入的,通过这个模块可以轻松实现异步调用 from multiprocessing import Pool def f(x): return x*x if __name__ == '__main__': pool = Pool(processes=1) # Start a worker processes. r
-
简单学习Python多进程Multiprocessing
1.1 什么是 Multiprocessing 多线程在同一时间只能处理一个任务. 可把任务平均分配给每个核,而每个核具有自己的运算空间. 1.2 添加进程 Process 与线程类似,如下所示,但是该程序直接运行无结果,因为IDLE不支持多进程,在命令行终端运行才有结果显示 import multiprocessing as mp def job(a,b): print('abc') if __name__=='__main__': p1=mp.Process(target=job,args=
-
Python多进程multiprocessing.Pool类详解
multiprocessing模块 multiprocessing包是Python中的多进程管理包.它与 threading.Thread类似,可以利用multiprocessing.Process对象来创建一个进程.该进程可以允许放在Python程序内部编写的函数中.该Process对象与Thread对象的用法相同,拥有is_alive().join([timeout]).run().start().terminate()等方法.属性有:authkey.daemon(要通过start()设置)
-
总结python多进程multiprocessing的相关知识
multiprocessing多进程 概念 创建多进程基本流程 创建进程对象 启动进程 回收进程 代码: import multiprocessing as mp from time import sleep # 进程执行函数 def fun(): print("开始一个进程") sleep(3) print("进程结束") # 创建进程对象 p = mp.Process(target = fun) p.start() # 启动进程 p.join() # 回收进程
-
Python多进程multiprocessing、进程池用法实例分析
本文实例讲述了Python多进程multiprocessing.进程池用法.分享给大家供大家参考,具体如下: 内容相关: multiprocessing: 进程的创建与运行 进程常用相关函数 进程池: 为什么要有进程池 进程池的创建与运行:串行.并行 回调函数 多进程multiprocessing: python中的多进程需要使用multiprocessing模块 多进程的创建与运行: 1.进程的创建:进程对象=multiprocessing.Process(target=函数名,args=(参
-
简单学习Python time模块
本文针对Python time模块进行分类学习,希望对大家的学习有所帮助. 一.壁挂钟时间 1.time() time模块的核心函数time(),它返回纪元开始的秒数,返回值为浮点数,具体精度依赖于平台. >>>import time >>>time.time() 1460599046.85416 2.ctime() 浮点数一般用于存储和比较日期,但是对人类不友好,要记录和打印时间,可以使用ctime(). >>>import time >>
-
Python多进程池 multiprocessing Pool用法示例
本文实例讲述了Python多进程池 multiprocessing Pool用法.分享给大家供大家参考,具体如下: 1. 背景 由于需要写python程序, 定时.大量发送htttp请求,并对结果进行处理. 参考其他代码有进程池,记录一下. 2. 多进程 vs 多线程 c++程序中,单个模块通常是单进程,会启动几十.上百个线程,充分发挥机器性能.(目前c++11有了std::thread编程多线程很方便,可以参考我之前的博客) shell脚本中,都是多进程后台执行.({ ...} &, 可以参考
-
python多进程执行方法apply_async使用说明
apply_async简介 python在同一个线程中多次执行同一方法时,该方法执行耗时较长且每次执行过程及结果互不影响,如果只在主进程中执行,效率会很低,因此使用multiprocessing.Pool(processes=n)及其apply_async()方法提高程序执行的并行度从而提高程序的执行效率,其中processes=n为程序并行执行的进程数. apply_async使用简明代码 import multiprocessing #method为多次调用的方法 def method(pa
-
Python利用multiprocessing实现最简单的分布式作业调度系统实例
介绍 Python的multiprocessing模块不但支持多进程,其中managers子模块还支持把多进程分布到多台机器上.一个服务进程可以作为调度者,将任务分布到其他多个机器的多个进程中,依靠网络通信.想到这,就在想是不是可以使用此模块来实现一个简单的作业调度系统.在这之前,我们先来详细了解下python中的多进程管理包multiprocessing. multiprocessing.Process multiprocessing包是Python中的多进程管理包.它与 threading.
-
python多进程控制学习小结
前言: python多进程,经常在使用,却没有怎么系统的学习过,官网上面讲得比较细,结合自己的学习,整理记录下官网:https://docs.python.org/3/library/multiprocessing.html multiprocessing简介 multiprocessing是python自带的多进程模块,可以大批量的生成进程,在服务器为多核CPU时效果更好,类似于threading模块.相对于多线程,多进程由于独享内存空间,更稳定安全,在运维里面做些批量操作时,多进程有更多适用