零基础写python爬虫之打包生成exe文件
1.下载pyinstaller并解压(可以去官网下载最新版):
https://github.com/pyinstaller/pyinstaller/
2.下载pywin32并安装(注意版本,我的是python2.7):
https://pypi.python.org/pypi/pywin32
3.将项目文件放到pyinstaller文件夹下面(我的是baidu.py):
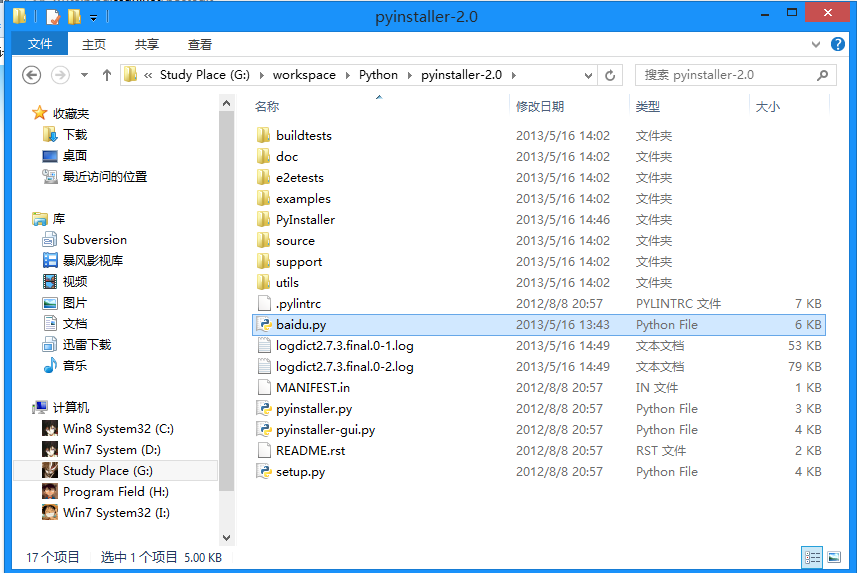
4.按住shift键右击,在当前路径打开命令提示行,输入以下内容(最后的是文件名):
python pyinstaller.py -F baidu.py
5.生成的exe文件,在baidu文件夹下的dist文件夹中,双击即可运行:

相关推荐
-
python学习必备知识汇总
一.变量 1.变量 •指在程序执行过程中,可变的量: •定义一个变量,就会伴随有3个特征,分别是内存ID.数据类型和变量值. •其他语言运行完之前,一定要手动把程序的内存空间释放掉.但python解释器是自带内存回收机制的,一旦python程序运行完后,会自动释放内存空间. age=10 print(id(age),type(age),age) 2.常量 •指在程序执行过程中,不可变的量: •一般都用大写字母定义常量. AGE=10 print(AGE) 3. 变量的命名方式 •驼峰体 AgeO
-

Python学习笔记(一)(基础入门之环境搭建)
Python入门 本系列为Python学习相关笔记整理所得,IT人,多学无害,多多探索,激发学习兴趣,开拓思维,不求高大上,只求懂点皮毛,作为知识储备,不至于落后太远. 本文主要介绍Python的相关背景,环境搭建. 一.了解Python 1,关于Python的语言特点: 借用Python官网Https://www.python.org的解释: Python is powerful... and fast; plays well with others; runs everywhere
-
零基础写python爬虫之urllib2使用指南
前面说到了urllib2的简单入门,下面整理了一部分urllib2的使用细节. 1.Proxy 的设置 urllib2 默认会使用环境变量 http_proxy 来设置 HTTP Proxy. 如果想在程序中明确控制 Proxy 而不受环境变量的影响,可以使用代理. 新建test14来实现一个简单的代理Demo: 复制代码 代码如下: import urllib2 enable_proxy = True proxy_handler = urllib2.ProxyHandler({"http&
-
Python类的基础入门知识
复制代码 代码如下: class Account(object): "一个简单的类" account_type="Basic" def __init__(self,name,balance): "初始化一个新的Account实例" self.name=name self.balance=balance def deposit(self,amt): "存款" self.balance=self.balance+amt def w
-
python基础教程之数字处理(math)模块详解
1.math简介 复制代码 代码如下: >>> import math>>>dir(math) #这句可查看所有函数名列表>>>help(math) #查看具体定义及函数0原型 2.常用函数 复制代码 代码如下: ceil(x) 取顶floor(x) 取底fabs(x) 取绝对值factorial (x) 阶乘hypot(x,y) sqrt(x*x+y*y)pow(x,y) x的y次方sqrt(x) 开平方log(x
-
python基础教程之类class定义使用方法
面对对象(oop)中的对象,是一个非常重要的知识点,我们可以把它简单看做是数据以及由存取.操作这些数据的方法所组成的一个集合.我们在学习函数(function)之后,知道了如果重用代码,那为什么还要用类来取代函数呢? 类有这样一些的优点 1) .类对象是多态的:也就是多种形态,这意味着我们可以对不同的类对象使用同样的操作方法,而不需要额外写代码. 2).类的封装:封装之后,可以直接调用类的对象,来操作内部的一些类方法,不需要让使用者看到代码工作的细节. 3).类的继承:类可以从其它类或者元类中继
-
零基础写python爬虫之打包生成exe文件
1.下载pyinstaller并解压(可以去官网下载最新版): https://github.com/pyinstaller/pyinstaller/ 2.下载pywin32并安装(注意版本,我的是python2.7): https://pypi.python.org/pypi/pywin32 3.将项目文件放到pyinstaller文件夹下面(我的是baidu.py): 4.按住shift键右击,在当前路径打开命令提示行,输入以下内容(最后的是文件名): python pyinstaller.
-
零基础写python爬虫之抓取百度贴吧并存储到本地txt文件改进版
百度贴吧的爬虫制作和糗百的爬虫制作原理基本相同,都是通过查看源码扣出关键数据,然后将其存储到本地txt文件. 项目内容: 用Python写的百度贴吧的网络爬虫. 使用方法: 新建一个BugBaidu.py文件,然后将代码复制到里面后,双击运行. 程序功能: 将贴吧中楼主发布的内容打包txt存储到本地. 原理解释: 首先,先浏览一下某一条贴吧,点击只看楼主并点击第二页之后url发生了一点变化,变成了: http://tieba.baidu.com/p/2296712428?see_lz=1&pn=
-
零基础写python爬虫之使用Scrapy框架编写爬虫
网络爬虫,是在网上进行数据抓取的程序,使用它能够抓取特定网页的HTML数据.虽然我们利用一些库开发一个爬虫程序,但是使用框架可以大大提高效率,缩短开发时间.Scrapy是一个使用Python编写的,轻量级的,简单轻巧,并且使用起来非常的方便.使用Scrapy可以很方便的完成网上数据的采集工作,它为我们完成了大量的工作,而不需要自己费大力气去开发. 首先先要回答一个问题. 问:把网站装进爬虫里,总共分几步? 答案很简单,四步: 新建项目 (Project):新建一个新的爬虫项目 明确目标(Item
-
零基础写python爬虫之神器正则表达式
接下来准备用糗百做一个爬虫的小例子. 但是在这之前,先详细的整理一下Python中的正则表达式的相关内容. 正则表达式在Python爬虫中的作用就像是老师点名时用的花名册一样,是必不可少的神兵利器. 一. 正则表达式基础 1.1.概念介绍 正则表达式是用于处理字符串的强大工具,它并不是Python的一部分. 其他编程语言中也有正则表达式的概念,区别只在于不同的编程语言实现支持的语法数量不同. 它拥有自己独特的语法以及一个独立的处理引擎,在提供了正则表达式的语言里,正则表达式的语法都是一样的. 下
-
零基础写python爬虫之爬虫框架Scrapy安装配置
前面十章爬虫笔记陆陆续续记录了一些简单的Python爬虫知识, 用来解决简单的贴吧下载,绩点运算自然不在话下. 不过要想批量下载大量的内容,比如知乎的所有的问答,那便显得游刃不有余了点. 于是乎,爬虫框架Scrapy就这样出场了! Scrapy = Scrach+Python,Scrach这个单词是抓取的意思, Scrapy的官网地址:点我点我. 那么下面来简单的演示一下Scrapy的安装流程. 具体流程参照:http://www.jb51.net/article/48607.htm 友情提醒:
-
零基础写python爬虫之抓取糗事百科代码分享
项目内容: 用Python写的糗事百科的网络爬虫. 使用方法: 新建一个Bug.py文件,然后将代码复制到里面后,双击运行. 程序功能: 在命令提示行中浏览糗事百科. 原理解释: 首先,先浏览一下糗事百科的主页:http://www.qiushibaike.com/hot/page/1 可以看出来,链接中page/后面的数字就是对应的页码,记住这一点为以后的编写做准备. 然后,右击查看页面源码: 观察发现,每一个段子都用div标记,其中class必为content,title是发帖时间,我们只需
-
零基础写python爬虫之爬虫编写全记录
先来说一下我们学校的网站: http://jwxt.sdu.edu.cn:7777/zhxt_bks/zhxt_bks.html 查询成绩需要登录,然后显示各学科成绩,但是只显示成绩而没有绩点,也就是加权平均分. 显然这样手动计算绩点是一件非常麻烦的事情.所以我们可以用python做一个爬虫来解决这个问题. 1.决战前夜 先来准备一下工具:HttpFox插件. 这是一款http协议分析插件,分析页面请求和响应的时间.内容.以及浏览器用到的COOKIE等. 以我为例,安装在火狐上即可,效果如图:
-
零基础写python爬虫之抓取百度贴吧代码分享
这里就不给大家废话了,直接上代码,代码的解释都在注释里面,看不懂的也别来问我,好好学学基础知识去! 复制代码 代码如下: # -*- coding: utf-8 -*- #--------------------------------------- # 程序:百度贴吧爬虫 # 版本:0.1 # 作者:why # 日期:2013-05-14 # 语言:Python 2.7 # 操作:输入带分页的地址,去掉最后面的数字,设置一下起始页数和终点页数. # 功能:下载对应页
-
零基础写python爬虫之HTTP异常处理
先来说一说HTTP的异常处理问题. 当urlopen不能够处理一个response时,产生urlError. 不过通常的Python APIs异常如ValueError,TypeError等也会同时产生. HTTPError是urlError的子类,通常在特定HTTP URLs中产生. 1.URLError 通常,URLError在没有网络连接(没有路由到特定服务器),或者服务器不存在的情况下产生. 这种情况下,异常同样会带有"reason"属性,它是一个tuple(可以理解为不可变的