Python 正则表达式的高级用法
对于Python来说,学习正则就要学习模块re的使用方法。本文将展示一些大家都应该掌握的高级技巧。
编译正则对象
re.compile函数根据一个模式字符串和可选的标志参数生成一个正则表达式对象。该对象拥有一系列方法用于正则表达式匹配和替换。用法上略有区别,举个例子, 匹配一个字符串可用如下方式:
如果使用compile,将变成:
为什么要这么用呢?其实就是为了提高正则匹配的速度,重复利用正则表达式对象。我们对比一下2种方式的效率:
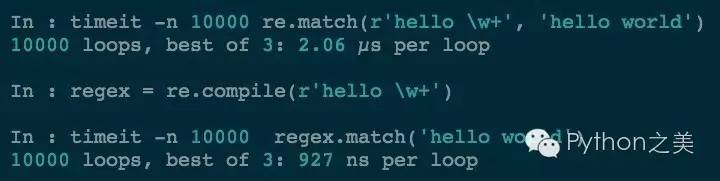
可以看到第二种方式要快很多。在实际的工作中你会发现越多的使用编译好的正则表达式对象,效果就越好。
分组(group)
你可能已经见过对匹配的内容进行分组的用法了:
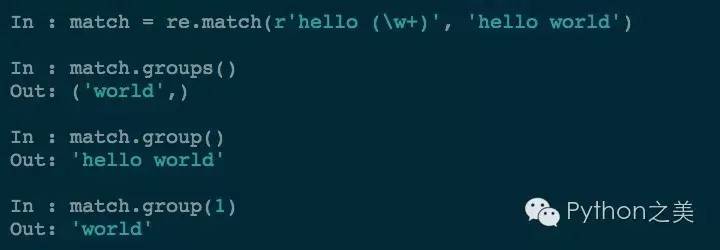
通过对要匹配的对象添加括号,就可以精确的对应符合的结果了。我们还可以进行嵌套的分组:
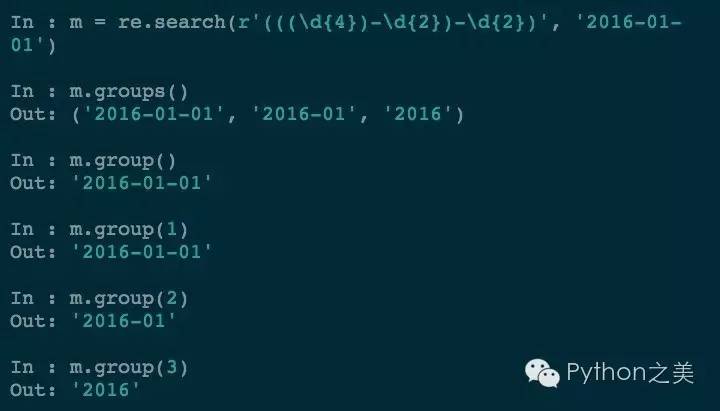
分组可以满足需求,但是有时候可读性很差,那可以对分组进行命名:

现在可读性就非常高了。
字符串匹配
学过sed的同学可能见过如下替换用法:
这个\1表示前面正则匹配到的结果。上面的sed也就是给匹配到的结果加上中括号。
在re模块中也存在这样的用法:

用命名分组也是可以的:
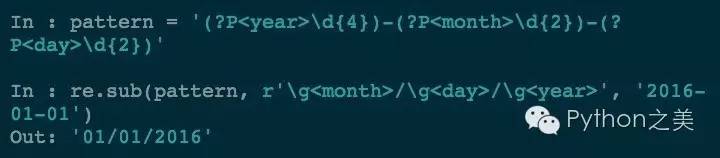
附近匹配(Look around)
re模块也支持附近匹配,看看例子就懂了:

正则匹配的时候使用函数
之前我们看到的大部分内容都是匹配的是一个表达式,但是有时候需求要复杂得多,尤其是在替换的时候。
举个例子,通过Slack的API能获取聊天记录,比如下面这句:
其中<@U1EAT8MG9>和<@U0K1MF23Z>是2个真实的用户,但是被Slack封装了,需要通过其他接口获取这个对应关系,
其结果类似这样:
在解析对应关系之后,还希望吧尖括号也去掉,替换后的结果是「@xiaoming, @laolin 嗯 确实是这样的 」
用正则怎么实现呢?

所以pattern当然也可以是一个函数
相关推荐
-
Python正则表达式实现截取成对括号的方法
本文实例讲述了Python正则表达式实现截取成对括号的方法.分享给大家供大家参考,具体如下: strs = '1(2(3(4(5(67)6)7)8)9)0' reg1 = re.compile('([()])∗') #一对括号 reg2 = re.compile('([()]|\([()]∗)*\)') #两对括号 reg3 = re.compile('([()]|\([()]∗|([()]|\([()]∗)*\))*\)') #三层 函数 #匹配成对括号正则表达式 def getReg(sel
-
Python正则表达式如何进行字符串替换实例
Python正则表达式在使用中会经常应用到字符串替换的代码.有很多人都不知道如何解决这个问题,下面的代码就告诉你其实这个问题无比的简单,希望你有所收获. 1.替换所有匹配的子串用newstring替换subject中所有与正则表达式regex匹配的子串 result, number = re.subn(regex, newstring, subject) 2.替换所有匹配的子串(使 用正则表达式对象) rereobj = re.compile(regex) result, number = re
-

Python中正则表达式match()、search()函数及match()和search()的区别详解
match()和search()都是python中的正则匹配函数,那这两个函数有何区别呢? match()函数只检测RE是不是在string的开始位置匹配, search()会扫描整个string查找匹配, 也就是说match()只有在0位置匹配成功的话才有返回,如果不是开始位置匹配成功的话,match()就返回none 例如: #! /usr/bin/env python # -*- coding=utf-8 -*- import re text = 'pythontab' m = re.ma
-
Python正则替换字符串函数re.sub用法示例
本文实例讲述了Python正则替换字符串函数re.sub用法.分享给大家供大家参考,具体如下: python re.sub属于python正则的标准库,主要是的功能是用正则匹配要替换的字符串 然后把它替换成自己想要的字符串的方法 re.sub 函数进行以正则表达式为基础的替换工作 下面是一段示例源码 #!/usr/bin/env python #encoding: utf-8 import re url = 'https://113.215.20.136:9011/113.215.6.77/c3
-
python 根据正则表达式提取指定的内容实例详解
python 根据正则表达式提取指定的内容 正则表达式是极其强大的,利用正则表达式来提取想要的内容是很方便的事. 下面演示了在python里,通过正则表达式来提取符合要求的内容. 实例代码: import re # 正则表达式是极其强大的,利用正则表达式来提取想要的内容是很方便的事. # 下面演示了在python里,通过正则表达式来提取符合要求的内容.有几个要注意 # 的地方就是: # [1] 要用()将需要的内容包含起来 # [2] 编号为0的group是整个符合正则表达式的内容,编号为1的是
-
Python正则获取、过滤或者替换HTML标签的方法
本文实例介绍了Python通过正则表达式获取,去除(过滤)或者替换HTML标签的几种方法,具体内容如下 python正则表达式关键内容: python正则表达式转义符: . 匹配除换行符以外的任意字符 \w 匹配字母或数字或下划线或汉字 \s 匹配任意的空白符 \d 匹配数字 \b 匹配单词的开始或结束 ^ 匹配字符串的开始 $ 匹配字符串的结束 \W 匹配任意不是字母,数字,下划线,汉字的字符 \S 匹配任意不是空白符的字符 \D 匹配任意非数字的字符 \B 匹配不是单词开头或结束的位置 [^
-
python利用正则表达式提取字符串
前言 正则表达式的基础知识就不说了,有兴趣的可以点击这里,提取一般分两种情况,一种是提取在文本中提取单个位置的字符串,另一种是提取连续多个位置的字符串.日志分析会遇到这种情况,下面我会分别讲一下对应的方法. 一.单个位置的字符串提取 这种情况我们可以使用(.+?)这个正则表达式来提取. 举例,一个字符串"a123b",如果我们想提取ab之间的值123,可以使用findall配合正则表达式,这样会返回一个包含所以符合情况的list. 代码如下: import re str = "
-
python使用正则表达式匹配字符串开头并打印示例
本文实例讲述了python使用正则表达式匹配字符串开头并打印的方法.分享给大家供大家参考,具体如下: import re s="name=z1hangshan username=fff url=www.baidu.com password=ddd256" s2="username=fff name=z1hangshan url=www.baidu.com password=ddd256" #p=re.compile(r'((?:\s)name=(\S)+)') p=
-
python使用正则表达式分析网页中的图片并进行替换的方法
本文实例讲述了python使用正则表达式分析网页中的图片并进行替换的方法.分享给大家供大家参考.具体分析如下: 这段代码分析网页中的所有图片表单<img>,分析后为其前后添加相应的修饰标签,并添加到图片的超级链接. 复制代码 代码如下: result = value.replace("[ page ]","").replace(' ',u' ') p=re.compile(r'''(<img\b[^<>]*?\bsrc[\s\t\r\
-
Python正则表达式匹配中文用法示例
本文实例讲述了Python正则表达式匹配中文用法.分享给大家供大家参考,具体如下: #!/usr/bin/python #-*- coding:cp936-*-#思路,将str转换成unicode,方可用正则表达式,前提是,要知道文件的编码,本例中是gbk import cPickle as mypickle import re import sys if (__name__=='__main__'): fid1=file('demo.txt','r');#demo.txt写入字符如:我们 p=