SQLserver 实现分组统计查询(按月、小时分组)
设置AccessCount字段可以根据需求在特定的时间范围内如果是相同IP访问就在AccessCount上累加。
代码如下:
Create table Counter
(
CounterID int identity(1,1) not null,
IP varchar(20),
AccessDateTime datetime,
AccessCount int
)
该表在这儿只是演示使用,所以只提供了最基本的字段
现在往表中插入几条记录
insert into Counter
select '127.0.0.1',getdate(),1 union all
select '127.0.0.2',getdate(),1 union all
select '127.0.0.3',getdate(),1
1 根据年来查询,以月为时间单位
通常情况下一个简单的分组就能搞定
代码如下:
select
convert(varchar(7),AccessDateTime,120) as Date,
sum(AccessCount) as [Count]
from
Counter
group by
convert(varchar(7),AccessDateTime,120)
像这样分组后没有记录的月份不会显示,如下: 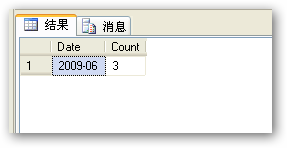
这当然不是我们想要的,所以得换一种思路来实现,如下:
代码如下:
declare @Year int
set @Year=2009
select
m as [Date],
sum(
case when datepart(month,AccessDateTime)=m
then AccessCount else 0 end
) as [Count]
from
Counter c,
(
select 1 m
union all select 2
union all select 3
union all select 4
union all select 5
union all select 6
union all select 7
union all select 8
union all select 9
union all select 10
union all select 11
union all select 12
) aa
where
@Year=year(AccessDateTime)
group by
m
查询结果如下: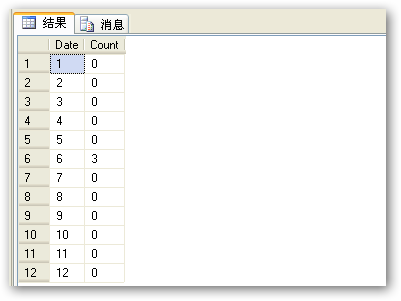
2 根据天来查询,以小时为单位。这个和上面的类似,代码如下:
代码如下:
declare @DateTime datetime
set @DateTime=getdate()
select
right(100+a,2)+ ':00 -> '+right(100+b,2)+ ':00 ' as DateSpan,
sum(
case when datepart(hour,AccessDateTime)> =a
and datepart(hour,AccessDateTime) <b
then AccessCount else 0 end
) as [Count]
from Counter c ,
(select 0 a,1 b
union all select 1,2
union all select 2,3
union all select 3,4
union all select 4,5
union all select 5,6
union all select 6,7
union all select 7,8
union all select 8,9
union all select 9,10
union all select 10,11
union all select 11,12
union all select 12,13
union all select 13,14
union all select 14,15
union all select 15,16
union all select 16,17
union all select 17,18
union all select 18,19
union all select 19,20
union all select 20,21
union all select 21,22
union all select 22,23
union all select 23,24
) aa
where datediff(day,@DateTime,AccessDateTime)=0
group by right(100+a,2)+ ':00 -> '+right(100+b,2)+ ':00 '
查询结果如下图: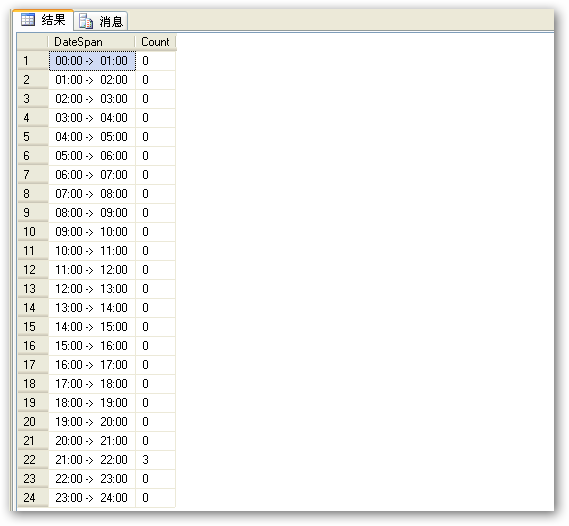
相关推荐
-

SQL Server 树形表非循环递归查询的实例详解
很多人可能想要查询整个树形表关联的内容都会通过循环递归来查...事实上在微软在SQL2005或以上版本就能用别的语法进行查询,下面是示例. --通过子节点查询父节点 WITH TREE AS( SELECT * FROM Areas WHERE id = 6 -- 要查询的子 id UNION ALL SELECT Areas.* FROM Areas, TREE WHERE TREE.PId = Areas.Id ) SELECT Area FROM TREE --通过父节点查询子节点 WIT
-
使用SQLSERVER 2005/2008 递归CTE查询树型结构的方法
下面是一个简单的Family Tree 示例: 复制代码 代码如下: DECLARE @TT TABLE (ID int,Relation varchar(25),Name varchar(25),ParentID int) INSERT @TT SELECT 1,' Great GrandFather' , 'Thomas Bishop', null UNION ALL SELECT 2,'Grand Mom', 'Elian Thomas Wilson' , 1 UNION ALL SELE
-
sql server实现递归查询的方法示例
本文实例讲述了sql server实现递归查询的方法示例.分享给大家供大家参考,具体如下: 有时候面对树结构的数据时需要进行递归查询,网上找了一番,参考了各位大神的文章,发现蛮简单的,当做个小笔记方便以后使用 sql server 通过CTE来支持递归查询,这对查询树形或层次结构的数据很有用 一般的树形表结构如下,相信大家都很熟悉的 id title pid 1 1级节点 0 2 2级节点 1 3 3级节点 2 4 4级节点 3 5 5级节点 4 下面上代码 ----------sql serv
-
SQL Server SQL高级查询语句小结
Ø 基本常用查询 --select select * from student; --all 查询所有 select all sex from student; --distinct 过滤重复 select distinct sex from student; --count 统计 select count(*) from student; select count(sex) from student; select count(distinct sex) from student; --top
-
SQLSERVER2005 中树形数据的递归查询
问题描述.借用了adinet的问题.参见:http://www.jb51.net/article/28670.htm 今天做项目遇到一个问题, 有产品分类A,B,C顶级分类, 期中A下面有a1,a2,a3子分类. 但是a1可能共同属于A和B,然后我的数据库是这样设计的 id name parnet 1 A 0 2 B 0 3 a1 1,2 如果想要查询A的所有子类的话就要查询parent中包含1的,所以就萌生了这个办法.呵呵,解决方案 复制代码
-
SQLserver2008使用表达式递归查询
复制代码 代码如下: --由父项递归下级 with cte(id,parentid,text) as (--父项 select id,parentid,text from treeview where parentid = 450 union all --递归结果集中的下级 select t.id,t.parentid,t.text from treeview as t inner join cte as c on t.parentid = c.id ) select id,parentid,t
-
Sql server2005 优化查询速度50个方法小结
I/O吞吐量小,形成了瓶颈效应. 没有创建计算列导致查询不优化. 内存不足. 网络速度慢. 查询出的数据量过大(可以采用多次查询,其他的方法降低数据量). 锁或者死锁(这也是查询慢最常见的问题,是程序设计的缺陷). sp_lock,sp_who,活动的用户查看,原因是读写竞争资源. 返回了不必要的行和列. 查询语句不好,没有优化. 可以通过如下方法来优化查询 : 1.把数据.日志.索引放到不同的I/O设备上,增加读取速度,以前可以将Tempdb应放在RAID0上,SQL2000不在支持.数据量(
-
sqlserver 模糊查询常用方法
搜索条件中的模式匹配 LIKE 关键字搜索与指定模式匹配的字符串.日期或时间值.LIKE 关键字使用常规表达式包含值所要匹配的模式.模式包含要搜索的字符串,字符串中可包含四种通配符的任意组合. 通配符 含义 % 包含零个或更多字符的任意字符串. _ 任何单个字符. [ ] 指定范围(例如 [a-f])或集合(例如 [abcdef])内的任何单个字符. [^] 不在指定范围(例如 [^a - f])或集合(例如 [^abcdef])内的任何单个字符. 请将通配符和字符串用单引号引起来,例如: LI
-
sql server递归子节点、父节点sql查询表结构的实例
一.查询当前部门下的所有子部门 WITH dept AS ( SELECT * FROM dbo.deptTab --部门表 WHERE pid = @id UNION ALL SELECT d.* FROM dbo.deptTab d INNER JOIN dept ON d.pid = dept.id ) SELECT * FROM dept 二.查询当前部门所有上级部门 WITH tab AS ( SELECT DepId , ParentId , DepName , [Enable] ,
-
使用SqlServer CTE递归查询处理树、图和层次结构
CTE(Common Table Expressions)是从SQL Server 2005以后版本才有的.指定的临时命名结果集,这些结果集称为CTE. 与派生表类似,不存储为对象,并且只在查询期间有效.与派生表的不同之处在于,CTE 可自引用,还可在同一查询中引用多次.使用CTE能改善代码可读性,且不损害其性能. 递归CTE是SQL SERVER 2005中重要的增强之一.一般我们在处理树,图和层次结构的问题时需要用到递归查询. CTE的语法如下 WITH CTE AS ( SELECT Em
-
高效的SQLSERVER分页查询(推荐)
第一种方案.最简单.普通的方法: 复制代码 代码如下: SELECT TOP 30 * FROM ARTICLE WHERE ID NOT IN(SELECT TOP 45000 ID FROM ARTICLE ORDER BY YEAR DESC, ID DESC) ORDER BY YEAR DESC,ID DESC 平均查询100次所需时间:45s 第二种方案: 复制代码 代码如下: SELECT * FROM ( SELECT TOP 30 * FROM (SELECT TOP 4503