Python实现正则表达式匹配任意的邮箱方法
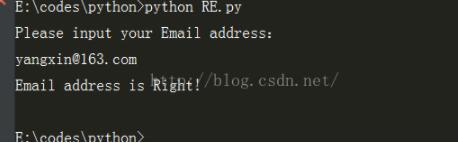
首先来个简单的例子,利用Python实现匹配163邮箱的代码:
#-*- coding:utf-8 -*-
__author__ = '杨鑫'
import re
text = input("Please input your Email address:\n"):
if re.match(r'[0-9a-zA-Z_]{0,19}@163.com',text):
print('Email address is Right!')
else:
print('Please reset your right Email address!')
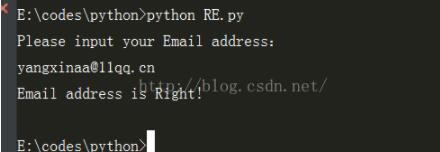
接着来一个匹配所有邮箱格式的代码:
#-*- coding:utf-8 -*-
__author__ = '杨鑫'
import re
text = input("Please input your Email address:\n")
if re.match(r'^[0-9a-zA-Z_]{0,19}@[0-9a-zA-Z]{1,13}\.[com,cn,net]{1,3}$',text):
#if re.match(r'[0-9a-zA-Z_]{0,19}@163.com',text):
print('Email address is Right!')
else:
print('Please reset your right Email address!')
以上这篇Python实现正则表达式匹配任意的邮箱方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
js正则表达式校验指定字符串的方法
最新一个小表单验证需求:"只能输入汉字,并且必须包含"支行","分行","银行","信用社""字样,需用正则表达式校验 故写出了如下的表达式 var patt1=new RegExp(/^[\u0391-\uFFE5]*(([\u652f]{1}[\u884c]{1})|([\u5206]{1}[\u884c]{1})|([\u94f6]{1}[\u884c]{1})|([\u4fe1]{1}[\u7528
-
python正则表达式去除两个特殊字符间的内容方法
以去掉去掉<!--和-->为例进行说明: def clearContentWithSpecialCharacter(content): # 先将<!--替换成,普通字符l content = content.replace("<!--","l") # 再将-->替换成,普通字符l content = content.replace("-->","l") # 分组标定,替换, pattern
-
Java使用正则表达式验证手机号和电话号码的方法
一个朋友需要,所以写了这两个,话不多说,看代码 中国电信号段 133.149.153.173.177.180.181.189.199 中国联通号段 130.131.132.145.155.156.166.175.176.185.186 中国移动号段 134(0-8).135.136.137.138.139.147.150.151.152.157.158.159.178.182.183.184.187.188.198 其他号段 14号段以前为上网卡专属号段,如中国联通的是145,中国移动的是147
-

JS使用正则表达式获取小括号、中括号及花括号内容的方法示例
本文实例讲述了JS使用正则表达式获取小括号.中括号及花括号内容的方法.分享给大家供大家参考,具体如下: JS 正则表达式 获取小括号 中括号 花括号内的内容 <!DOCTYPE html> <html> <head> <meta charset="utf-8" /> <title>www.jb51.net JS获取括号内容</title> </head> <body> <script
-
正则表达式性能优化方法(高效正则表达式书写)
这里说的正则表达式优化,主要是针对目前常用的NFA模式正则表达式,详细可以参考:正则表达式匹配解析过程探讨分析(正则表达式匹配原理).从上面例子,我们可以推断出,影响NFA类正则表达式(常见语言:GNU Emacs,Java,ergp,less,more,.NET语言, PCRE library,Perl,PHP,Python,Ruby,sed,vi )其实主要是它的"回溯",减少"回溯"次数(减少循环查找同一个字符次数),是提高性能的主要方法. 我们来看个例子:
-
Android 2018最新手机号验证正则表达式方法
下面给大家分享2018手机号正则表达式验证方法,具体内容如下所示: /** * 判断字符串是否符合手机号码格式 * 移动号段: 134,135,136,137,138,139,147,150,151,152,157,158,159,170,178,182,183,184,187,188 * 联通号段: 130,131,132,145,155,156,170,171,175,176,185,186 * 电信号段: 133,149,153,170,173,177,180,181,189 * @par
-
前端正则表达式书写及常用的方法
正则表达式(regular expression)描述了一种字符串匹配的模式(pattern),可以用来检查一个串是否含有某种子串.将匹配的子串替换或者从某个串中取出符合某个条件的子串等. 前端正则表达式书写 一.写法 写法一 /正则表达式/修饰符 修饰符 /i (忽略大小写) /g (全文查找出现的所有匹配字符) /m (多行查找) /gi(全文查找.忽略大小写) /ig(全文查找.忽略大小写) 例子:/a/gi 查找内容中的a 不写修饰符默认只匹配一个 写法二 let a = new Reg
-
Python 正则表达式匹配字符串中的http链接方法
利用Python正则表达式匹配字符串中的http链接.主要难点是用正则表示出http 链接的模式. import re pattern = re.compile(r'http[s]?://(?:[a-zA-Z]|[0-9]|[$-_@.&+]|[!*\(\),]|(?:%[0-9a-fA-F][0-9a-fA-F]))+') # 匹配模式 string = 'Its after 12 noon, do you know where your rooftops are? http://tinyur
-
Python实现正则表达式匹配任意的邮箱方法
首先来个简单的例子,利用Python实现匹配163邮箱的代码: #-*- coding:utf-8 -*- __author__ = '杨鑫' import re text = input("Please input your Email address:\n"): if re.match(r'[0-9a-zA-Z_]{0,19}@163.com',text): print('Email address is Right!') else: print('Please reset you
-
Python利用正则表达式匹配并截取指定子串及去重的方法
本文实例讲述了Python利用正则表达式匹配并截取指定子串及去重的方法.分享给大家供大家参考.具体如下: import re pattern=re.compile(r'\| (\d+) \| (\d+) \|') numset=set() all=''' | 29266795 | 533 | | 29370116 | 533 | | 29467495 | 533 | | 29500404 | 533 | | 29500622 | 533 | | 29515964 | 530 | | 295160
-
python使用正则表达式匹配字符串开头并打印示例
本文实例讲述了python使用正则表达式匹配字符串开头并打印的方法.分享给大家供大家参考,具体如下: import re s="name=z1hangshan username=fff url=www.baidu.com password=ddd256" s2="username=fff name=z1hangshan url=www.baidu.com password=ddd256" #p=re.compile(r'((?:\s)name=(\S)+)') p=
-
Python使用正则表达式分割字符串的实现方法
如下: re.split(pattern, string, [maxsplit], [flags]) pattern:表示模式字符串,由要匹配的正则表达式转换而来. string:表示要匹配的字符串. maxsplit:可选参数,表示最大的拆分次数. flags:可选参数表示标志位,用于控制匹配方式,如是否区分子母大小写 示例代码: import re pattern = r'[?|&]' # 定义分隔符 url = 'http://www.baidu.com/login.jsp?usernam
-
python使用正则表达式匹配反斜杠\遇到的问题
目录 遇到的问题: 正则表达式 python字符串 综上 字符串方法replace() 总结 遇到的问题: 在做爬虫的时候,爬取的url链接内还有转义字符,反斜杠 \,打算用正则的re.sub()替换掉的时候遇到了问题,这是要做替换的字符串 最开始直接写 re.sub("\\","",item) 编译器漏红了 然后就是找解决办法,最后发现要用四个反斜杠才可以,也就是使用 re.sub("\\\\","",item) 查了查资料
-
python使用正则表达式提取网页URL的方法
本文实例讲述了python使用正则表达式提取网页URL的方法.分享给大家供大家参考.具体实现方法如下: import re import urllib url="http://www.jb51.net" s=urllib.urlopen(url).read() ss=s.replace(" ","") urls=re.findall(r"<a.*?href=.*?<\/a>",ss,re.I) for i i
-
python使用正则表达式匹配txt特定字符串(有换行)
在原txt文件中,我们需要匹配出的字符串为:休闲服务(中间参杂着换行) 直接复制到notebook里进行处理 ①发现需要拿出的字符串都在证卷研究报告前,第一步就把证券报告前面的所有内容全部提出来(包括换行) ②发现需要的字符串在两个换行符(\n)的中间,再对其进行处理 完整代码 import re txt = """ 行业报告 | 行业点评 休闲服务 证券研究报告""" result = re.findall(r"([\s\S]*)证券
-
Python批量模糊匹配的3种方法实例
目录 前言 使用编辑距离算法进行模糊匹配 使用fuzzywuzzy进行批量模糊匹配 fuzz模块 process模块 整体代码 使用Gensim进行批量模糊匹配 Gensim简介 使用词袋模型直接进行批量相似度匹配 使用TF-IDF主题向量变换后进行批量相似度匹配 同时获取最大的3个结果 完整代码 总结 前言 当然,基于排序的模糊匹配(类似于Excel的VLOOKUP函数的模糊匹配模式)也属于模糊匹配的范畴,但那种过于简单,不是本文讨论的范畴. 本文主要讨论的是以公司名称或地址为主的字符串的模糊
-
正则表达式匹配任意字符(包括换行符)的写法
今天在Java中想使用正则表达式来获取一段文本中的任意字符.于是很随意得就写出如下匹配规则: (.*) 结果运行之后才发现,无法获得换行之后的文本.于是查了一下手册,才发现正则表达式中,"."(点符号)匹配的是除了换行符"\n"以外的所有字符.同时,手册上还有一句话:要匹配包括 '\n' 在内的任何字符,请使用像 '[.\n]' 的模式.于是我将正则表达式的匹配规则修改如下: ([.\n]*),当然,如果是在java程序中直接写到话,需要改为([.\\n]*) 结果
-
php用正则表达式匹配URL的简单方法
在PHP的官网上看到的parse_url()函数的替代方案.结果和parse_url()函数差不多,是使用正则实现的.URI 是 Web上可用的每种资源 - HTML文档.图像.视频片段.程序等 - 由一个通用资源标志符(Uniform Resource Identifier, 简称"URI")进行定位. 对象分组: 复制代码 代码如下: ^(([^:/?#]+):)?(//([^/?#]*))?([^?#]*)(\?([^#]*))?(#(.*))?12 3