python pandas 如何替换某列的一个值
摘要:本文主要是讲解怎么样替换某一列的一个值。
应用场景:
假如我们有以下的数据集:
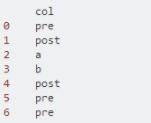
我们想把里面不是pre的字符串全部换成Nonpre,我们要怎么做呢?
做法很简单。
df['col2']=df['col1'] df.loc[df['col1'] !=' pre','col2']=Nonpre

以上这篇python pandas 如何替换某列的一个值就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
python之pandas用法大全
一.生成数据表 1.首先导入pandas库,一般都会用到numpy库,所以我们先导入备用: import numpy as np import pandas as pd 2.导入CSV或者xlsx文件: df = pd.DataFrame(pd.read_csv('name.csv',header=1)) df = pd.DataFrame(pd.read_excel('name.xlsx')) 3.用pandas创建数据表: df = pd.DataFrame({"id":[1001
-

Python科学计算之Pandas详解
起步 Pandas最初被作为金融数据分析工具而开发出来,因此 pandas 为时间序列分析提供了很好的支持. Pandas 的名称来自于面板数据(panel data)和python数据分析 (data analysis) .panel data是经济学中关于多维数据集的一个术语,在Pandas中也提供了panel的数据类型. 在我看来,对于 Numpy 以及 Matplotlib ,Pandas可以帮助创建一个非常牢固的用于数据挖掘与分析的基础.而Scipy当然是另一个主要的也十分出色的科学计
-
Python遍历pandas数据方法总结
前言 Pandas是python的一个数据分析包,提供了大量的快速便捷处理数据的函数和方法.其中Pandas定义了Series 和 DataFrame两种数据类型,这使数据操作变得更简单.Series 是一种一维的数据结构,类似于将列表数据值与索引值相结合.DataFrame 是一种二维的数据结构,接近于电子表格或者mysql数据库的形式. 在数据分析中不可避免的涉及到对数据的遍历查询和处理,比如我们需要将dataframe两列数据两两相除,并将结果存储于一个新的列表中.本文通过该例程介绍对pa
-
Python常见的pandas用法demo示例
本文实例总结了Python常见的pandas用法.分享给大家供大家参考,具体如下: import numpy as np import pandas as pd s = pd.Series([1,3,6, np.nan, 44, 1]) #定义一个序列. 序列就是一列内容,每一行有一个index值 print(s) print(s.index) 0 1.0 1 3.0 2 6.0 3 NaN 4 44.0 5 1.0 dtype: float64 R
-
在Python中利用Pandas库处理大数据的简单介绍
在数据分析领域,最热门的莫过于Python和R语言,此前有一篇文章<别老扯什么Hadoop了,你的数据根本不够大>指出:只有在超过5TB数据量的规模下,Hadoop才是一个合理的技术选择.这次拿到近亿条日志数据,千万级数据已经是关系型数据库的查询分析瓶颈,之前使用过Hadoop对大量文本进行分类,这次决定采用Python来处理数据: 硬件环境 CPU:3.5 GHz Intel Core i7 内存:32 GB HDDR 3 1600 MHz 硬
-
python中pandas.DataFrame排除特定行方法示例
前言 大家在使用Python进行数据分析时,经常要使用到的一个数据结构就是pandas的DataFrame,关于python中pandas.DataFrame的基本操作,大家可以查看这篇文章. pandas.DataFrame排除特定行 如果我们想要像Excel的筛选那样,只要其中的一行或某几行,可以使用isin()方法,将需要的行的值以列表方式传入,还可以传入字典,指定列进行筛选. 但是如果我们只想要所有内容中不包含特定行的内容,却并没有一个isnotin()方法.我今天的工作就遇到了这样的需
-
python pandas dataframe 按列或者按行合并的方法
concat 与其说是连接,更准确的说是拼接.就是把两个表直接合在一起.于是有一个突出的问题,是横向拼接还是纵向拼接,所以concat 函数的关键参数是axis . 函数的具体参数是: concat(objs,axis=0,join='outer',join_axes=None,ignore_index=False,keys=None,levels=None,names=None,verigy_integrity=False) objs 是需要拼接的对象集合,一般为列表或者字典 axis=0 是
-
Windows下Python使用Pandas模块操作Excel文件的教程
安装Python环境 ANACONDA是一个Python的发行版本,包含了400多个Python最常用的库,其中就包括了数据分析中需要经常使用到的Numpy和Pandas等.更重要的是,不论在哪个平台上,都可以一键安装,自动配置好环境,不需要用户任何的额外操作,非常方便.因此,安装Python环境就只需要到ANACONDA网站上下载安装文件,双击安装即可. ANACONDA官方下载地址:https://www.continuum.io/downloads 安装完成之后,使用windows + r
-
Python pandas常用函数详解
本文研究的主要是pandas常用函数,具体介绍如下. 1 import语句 import pandas as pd import numpy as np import matplotlib.pyplot as plt import datetime import re 2 文件读取 df = pd.read_csv(path='file.csv') 参数:header=None 用默认列名,0,1,2,3... names=['A', 'B', 'C'...] 自定义列名 index_col='
-
python中pandas.DataFrame的简单操作方法(创建、索引、增添与删除)
前言 最近在网上搜了许多关于pandas.DataFrame的操作说明,都是一些基础的操作,但是这些操作组合起来还是比较费时间去正确操作DataFrame,花了我挺长时间去调整BUG的.我在这里做一些总结,方便你我他.感兴趣的朋友们一起来看看吧. 一.创建DataFrame的简单操作: 1.根据字典创造: In [1]: import pandas as pd In [3]: aa={'one':[1,2,3],'two':[2,3,4],'three':[3,4,5]} In [4]: bb=