解决python字典对值(值为列表)赋值出现重复的问题
可能很少有人遇到这个问题,网上也没找到,这里记录一下,希望也可以帮到其他人。
问题描述:假设有一个字典data,其键不定,可能随时添加键(这不是关键),某一个键下面对应的值为一个长度为10的list,初始化为0,然后我想修改某些键下面的列表中的某一个值,比如data有一个键'k',对应的值为[0,0,0,0,0,0,0,0,0,0],现在我想把键'k'对应的列表的第三个数改成3,即[0,0,3,0,0,0,0,0,0,0],可是意外的事情发生了,如果data还有一个键'k1',假设其值为[0,0,0,0,0,0,0,0,0,0],但是我操作完之后,居然也跟着变成了[0,0,3,0,0,0,0,0,0,0]。
具体代码如下:
data = {}
indexes = ['new','repeat']
ret = [{'i':1,'new':3,'repeat':11},{'i':3,'new':2,'repeat':6},
{'i':4,'new':9,'repeat':2},{'i':9,'new':1,'repeat':8}]
y_axis = [0]*10
for e in ret:
for index in indexes:
if not data.has_key(index):
data[index] = y_axis
i = e['i']
for index in indexes:
data[index][i] = e[index]
print data
代码不难看懂,我感觉理论上应该输出:{'new': [0, 3, 0, 2, 9, 0, 0, 0, 0, 1], 'repeat': [0, 11, 0, 6, 2, 0, 0, 0, 0, 8]},但是事与愿违,输出是:{'new': [0, 11, 0, 6, 2, 0, 0, 0, 0, 8], 'repeat': [0, 11, 0, 6, 2, 0, 0, 0, 0, 8]},感觉莫名其妙,于是准备调试,先import pdb,再在需要打断点的前一句加pdb.set_trace()即可,如下:
import pdb
data = {}
indexes = ['new','repeat']
ret = [{'i':1,'new':3,'repeat':11},{'i':3,'new':2,'repeat':6},
{'i':4,'new':9,'repeat':2},{'i':9,'new':1,'repeat':8}]
y_axis = [0]*10
for e in ret:
for index in indexes:
if not data.has_key(index):
data[index] = y_axis
i = e['i']
for index in indexes:
pdb.set_trace()
data[index][i] = e[index]
print data
接着,python test.py,到赋值data的键对应的列表某一个值那一句:
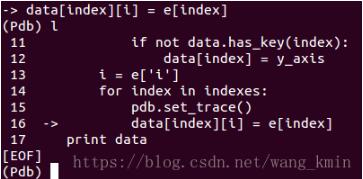
查看data和index值:

正常。往下执行一步,即执行赋值操作,再查看data值:
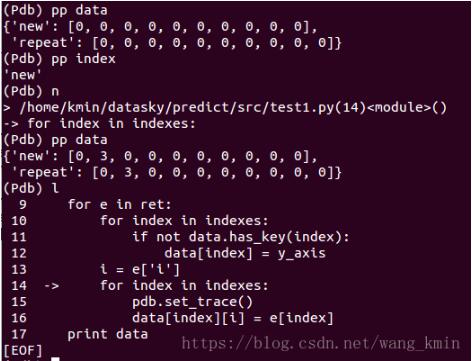
在这里真想来一句mdblgl,明明index是'new',明明是对data['new'][1]赋值,关data['repeat'][1]屁事,它跟着变什么?可想而知,后面对data['repeat'][1]再赋一个值11,那'new'的值不就也跟着一起变,结果就是得到了最后那个莫名其妙的结果。
试过很多办法,想过很多原因,无赖才疏学浅,不知道是什么原理,最后,只好用一种非常笨的方法解决了:
data = {}
indexes = ['new','repeat']
ret = [{'i':1,'new':3,'repeat':11},{'i':3,'new':2,'repeat':6},
{'i':4,'new':9,'repeat':2},{'i':9,'new':1,'repeat':8}]
y_axis = [0]*10
tmp = y_axis*len(indexes)
for k in range(len(indexes)):
for e in ret:
i = e['i']
tmp[i+len(y_axis)*k] = e[indexes[k]]
for k in range(len(indexes)):
data[indexes[k]] = tmp[(k*len(y_axis)):((k+1)*len(y_axis))]
print data
在此,希望知道为什么这样的大佬指点一下,万分感谢!
以上这篇解决python字典对值(值为列表)赋值出现重复的问题就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
python变量赋值方法(可变与不可变)
python中不存在所谓的传值调用,一切传递的都是对象的引用,也可以认为是传址. 一.可变对象和不可变对象 Python在heap中分配的对象分成两类:可变对象和不可变对象.所谓可变对象是指,对象的内容可变,而不可变对象是指对象内容不可变. 不可变(immutable):int.字符串(string).float.(数值型number).元组(tuple) 可变(mutable):字典型(dictionary).列表型(list) 不可变类型特点: 看下面的例子(例1) i = 73 i +=
-
浅谈python连续赋值可能引发的错误
今天写的代码片段: X = Y = [] .. X.append(x) Y.append(y) 其中x和y是读取的每一个数据的xy值,打算将其归入列表之后绘散点图,但是绘图出来却是一条直线,数据本身并不是这样分布的. 反复检查后,发现是X = Y =[]这一句的错误. 在python中,形如X = Y的拷贝都是浅拷贝,X和Y是公用同一块空间的,一旦对它们其中的任意一个进行数据操作,都会改变该空间的内容,除非重新赋一块空间,改变其指向的位置. 因此只需要改成: X = [] Y = [] 就可以运
-
Python创建一个空的dataframe,并循环赋值的方法
如下所示: # 创建一个空的 DataFrame df_empty = pd.DataFrame() #或者 df_empty = pd.DataFrame(columns=['A', 'B', 'C', 'D']) #添加数据 a为一个新的dataframe df_empty = df_empty.append(a) 以上这篇Python创建一个空的dataframe,并循环赋值的方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们.
-
python批量赋值操作实例
变量名和变量值俊发生规律的变化,利用for循环完成赋值操作. 举个例子: for i in range(1, 10): exec("t%d=i"%i) print(t1) print(t2) print(t3) print(t4) print(t5) print(t6) print(t7) print(t8) print(t9) 执行结果: 1 2 3 4 5 6 7 8 9 利用python中的exec()函数来完成. 以上这篇python批量赋值操作实例就是小编分享给大家的全部内容
-
Python动态赋值的陷阱知识点总结
忘了在哪看到一位编程大牛调侃,他说程序员每天就做两件事,其中之一就是处理字符串.相信不少同学会有同感. 几乎任何一种编程语言,都把字符串列为最基础和不可或缺的数据类型.而拼接字符串是必备的一种技能.今天,我跟大家一起来学习Python拼接字符串的七种方式. 1.来自C语言的%方式 print('%s %s' % ('Hello', 'world')) >>> Hello world %号格式化字符串的方式继承自古老的C语言,这在很多编程语言都有类似的实现.上例的%s是一个占位符,它仅代表
-
浅谈Python 列表字典赋值的陷阱
今天在用python刷leetcode 3Sum problem时,调入到了一个大坑中,检查半天并没有任何逻辑错误,但输出结果却总是不对,最终通过调试发现原来python中list和dict类型直接赋值竟然是浅拷贝!!!因此,在实际实验中,若要实现深拷贝,建立新list或dict,使新建的list或dict变量和以前的变量只是具有相同的值,但是却具有不同的存储地址,保证在改变以前的list变量的时候,不会对新的list产生任何影响. python中的深拷贝的实现需要通过copy.deepcopy
-
python 解决动态的定义变量名,并给其赋值的方法(大数据处理)
最近消费kafka数据到磁盘的时候遇到了这样的问题: 需求:每天大概有1千万条数据,每条数据包含19个字段信息,需要将数据写到服务器磁盘,以第二个字段作为大类建立目录,第7个字段作为小类配合时间戳作为文件名,临时文件后缀tmp,当每个文件的写入条数(可配置,比如100条)达到要求条数时,将后缀tmp改为out. 问题:大类共有30个,小类不计其数而且未知,比如大类为A,小类为a,时间戳为20180606095835234,则A目录下的文件名为20180606095835234_a.tmp,这样一
-
解决python字典对值(值为列表)赋值出现重复的问题
可能很少有人遇到这个问题,网上也没找到,这里记录一下,希望也可以帮到其他人. 问题描述:假设有一个字典data,其键不定,可能随时添加键(这不是关键),某一个键下面对应的值为一个长度为10的list,初始化为0,然后我想修改某些键下面的列表中的某一个值,比如data有一个键'k',对应的值为[0,0,0,0,0,0,0,0,0,0],现在我想把键'k'对应的列表的第三个数改成3,即[0,0,3,0,0,0,0,0,0,0],可是意外的事情发生了,如果data还有一个键'k1',假设其值为[0,0
-
Python字典中的值为列表或字典的构造实例
1.值为列表的构造实例 dic = {} dic.setdefault(key,[]).append(value) *********示例如下****** >>dic.setdefault('a',[]).append(1) >>dic.setdefault('a',[]).append(2) >>dic >>{'a': [1, 2]} 2.值为字典的构造实例 dic = {} dic.setdefault(key,{})[value] =1 *******
-

python字典多键值及重复键值的使用方法(详解)
在Python中使用字典,格式如下: dict={ key1:value1 , key2;value2 ...} 在实际访问字典值时的使用格式如下: dict[key] 多键值 字典的多键值形式如下: dict={(ke11,key12):value ,(key21,key22):value ...} 在实际访问字典里的值时的具体形式如下所示(以第一个键为例): dict[key11,key12] 或者是: dict[(key11,key12)] 以下是实际例子: 多值 在一个键值对应多个值时,
-
浅谈python字典多键值及重复键值的使用
在python中使用字典,格式如下: dict={ key1:value1 , key2;value2 ...} 在实际访问字典值时的使用格式如下: dict[key] 多键值 字典的多键值形式如下: dict={(ke11,key12):value ,(key21,key22):value ...} 在实际访问字典里的值时的具体形式如下所示(以第一个键为例): dict[key11,key12] 或者是: dict[(key11,key12)] 以下是实际例子: 多值 在一个键值对应多个值时,
-
python字典一键多值实例代码分享
python中字典可以一键多值,也就是意味着一个键可以对应多个值. 例: #encoding=utf-8 print '中国' #字典的一键多值 print'方案一 list作为dict的值 值允许重复' d1={} key=1 value=2 d1.setdefault(key,[]).append(value) value=2 d1.setdefault(key,[]).append(value) print d1 #获取值 print '方案一 获取值' print list(d1[key
-
python字典改变value值方法总结
今天这篇文章中我们来了解一下python之中的字典,在这文章之中我会对python字典修改进行说明,以及举例说明如何修改python字典内的值.废话不多说,我们开始进入文章吧. 首先我们得知道什么是修改字典 修改字典 向字典添加新内容的方法是增加新的键/值对,修改或删除已有键/值对如下实例: # !/usr/bin/python dict = {'Name': 'Zara', 'Age': 7, 'Class': 'First'}; dict['Age'] = 8; # update exist
-
python 字典 按key值大小 倒序取值的实例
如下所示: viedoUrl_dict = {1:'hello',2:'python',3:'nihao'} bit_list = sorted(viedoUrl_dict.keys()) bit_list.reverse() for key in bit_list: m3u8_url = viedoUrl_dict[key] print(m3u8_url) 以上这篇python 字典 按key值大小 倒序取值的实例就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们.
-
python 字典中取值的两种方法小结
如下所示: a={'name':'tony','sex':'male'} 获得name的值的方式有两种 print a['name'],type(a['name']) print a.get('name'),type(a.get('name')) 发现这两个结果完全一致,并没有任何的差异. 怎么选择这两个不同的字典取值方式呢? 如果字典已知,我们可以任选一个,而当我们不确定字典中是否存在某个键时,我之前的做法如下 if 'age' in a.keys(): print a['age'] 因为不先
-
解决Python字典写入文件出行首行有空格的问题
模拟购物车程序,判断用户薪资是否是0 如果是0就需要输入薪资,并记录到文件内. 可以预先存个字典格式的字符串,然后去读取文件的时候读到的是字字符串然后再去用eval去转换成字典. 当我们覆盖写到文件的时候就会发现首行会有空格,当我们再去读取eval的时候就会报错,那怎么样可以解决这个问题呢! import json info = { 'lisi':0, 'zhangshan':100, } f = open('json.txt','w') f.write(json.dumps(info)) {"
-
解决Python字典查找报Keyerror的问题
Python的字典一般都直接查找key ,比如 dict={'a':1,'b':2,'c':3} print(dict['a']) 但是如果在查找的key不存在的时候就会报:KeyError: 比如你要查看print(dict['d']) 由于这个时候dict里面并没有这个key ,所以就会直接报错,那么这个时候其实python给我们提供了一种很棒的解决方法,那就是用 setdefault,用法如下: dict.setdefault(key,[这里设置如果不存在想将值设置为啥,默认为None])