SQL Server Page结构深入分析
SQL Server存储数据的基本单元是Page,每一个Page的大小是8KB,数据文件是由Page构成的。在同一个数据库上,每一个Page都有一个唯一的资源标识,标识符由三部分组成:db_id,file_id,page_id,例如,15:1:8733,15是数据库的ID,1是数据文件的ID,8733是Page的编号,Page的编号从0依次递增。8个连续的Page组成一个区(Extent),数据文件中已分配(Allocated)的空间被分割成区的整数倍。一次磁盘IO操作作用于Page级别,而空间分配的最小单元是区。
Page是用于存储数据的,不同类型的Page存储的数据是不同的,Page的结构也是不同的。有些Page是用于存储数据的,叫做Data Page,有些Page是用于存储索引结构中的中间节点的,叫做Index Page,有些Page是SQL Server存储引擎使用的,用于管理Page的,叫做系统页。本文关注的是Data Page和Index Page,跟数据表有关。
日志文件没有Page结构,它是由一系列的日志记录构成的。
一,Page的结构
每一个Page都由 头部(Header),内容(Content)和行偏移量(Offset)组成,头部是在Page的开始处,占用96Bytes,用于存储Page的编号,Page的类型,分配单元(Allocation Unit)等系统信息。注:在单个Page中最多存储8060Bytes的数据。
The maximum amount of data and overhead that is contained in a single row on a page is 8,060 bytes (8 KB).
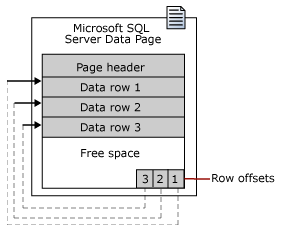
数据行存储在Page Header之后,数据行在Page中的物理存储是无序的,行的逻辑顺序是由行偏移(Row Offset)确定的,行偏移存储在Page的末尾,每一个行偏移是一个Slot,占用2B。行偏移连续排列在Page的末尾,称作槽数组(Slot Array)。行偏移以倒序方式存储行的偏移量,这意味着,从Page末尾向Page 开头计数,第一行的偏移量存储在Page的末尾Slot中,第二行的偏移量存储在Page末尾的第二个Slot中。
二,查看Page头部信息
Page头部信息存储的是Page的系统信息,可以使用非正式的命令来查看:
DBCC PAGE(['database name'|database id], file_id, page_number, print_option = [0|1|2|3] )
参数:file_id是数据库文件的ID;page_number是Page在当前文件中的编号;print_option是指打印信息的详细程度,默认值是0,只打印Page Header。
例如,查看资源标识符:15:1:8777733 Page的头部信息:
dbcc traceon(3604) dbcc page(15,1,8777733)
在我的数据库中,该Page的头部信息(移除Buffer的数据)如下所示,
PAGE: (1:8777733) PAGE HEADER: Page @0x0000005188B02000 m_pageId = (1:8777733) m_headerVersion = 1 m_type = 1 m_typeFlagBits = 0x0 m_level = 0 m_flagBits = 0x220 m_objId (AllocUnitId.idObj) = 28503 m_indexId (AllocUnitId.idInd) = 256 Metadata: AllocUnitId = 72057595905900544 Metadata: PartitionId = 72057594059423744 Metadata: IndexId = 1 Metadata: ObjectId = 1029578706 m_prevPage = (1:8777732) m_nextPage = (1:8777734) pminlen = 16 m_slotCnt = 2 m_freeCnt = 4513 m_freeData = 3675 m_reservedCnt = 0 m_lsn = (1212327:16:558) m_xactReserved = 0 m_xdesId = (0:799026688) m_ghostRecCnt = 0 m_tornBits = -1518328013 DB Frag ID = 1 Allocation Status GAM (1:8690944) = ALLOCATED SGAM (1:8690945) = NOT ALLOCATED PFS (1:8775480) = 0x40 ALLOCATED 0_PCT_FULL DIFF (1:8690950) = CHANGED ML (1:8690951) = NOT MIN_LOGGED
Page 头部中各个字段的含义:
1,Page的编号
m_pageId = (1:8777733),该Page所在的File ID 和Page ID
2,Page的类型
m_type = 1,Page的类型,常见的类型是数据页和索引页:
1 – data page,用于表示:堆表或聚集索引的叶子节点
2 – index page,用于表示:聚集索引的中间节点或者非聚集索引中所有级别的节点
其他Page类型(系统页是管理Page的Page,例如,GAM,IAM等)如下:
3 – text mix page,4 – text tree page,用于存储类型为文本的大对象数据
7 – sort page,用于存储排序操作的中间数据结果
8 – GAM page,用于存储全局分配映射数据GAM(Global Allocation Map),每一个数据文件被分割成4GB的空间块(Chunk),每一个Chunk都对应一个GAM数据页,GAM数据页出现在数据文件特定的位置处,一个bit映射当前Chunk中的一个区。
9 – SGAM page,用于存储SGAM页(Shared GAM)
10 – IAM page,用于存储IAM页(Index Allocation Map)
11 – PFS page,用于存储PFS页(Page Free Space)
13 – boot page,用于存储数据库的信息,只有一个Page,Page的标识符是:db_id:1:9,
15 – file header page,存储数据文件的数据,数据库的每一个文件都有一个,Page的编号是0。
16 – diff map page,存储差异备份的映射,表示从上一次完整备份之后,该区的数据是否修改过。
17 – ML map page,表示从上一次备份之后,在大容量日志(bulk-Logged)操作期间,该区的数据是否被修改过,This is what allows you to switch to bulk-logged mode for bulk-loads and index rebuilds without worrying about breaking a backup chain.
18 – a page that's be deallocated by DBCC CHECKDB during a repair operation.
19 – the temporary page that ALTER INDEX … REORGANIZE (or DBCC INDEXDEFRAG) uses when working on an index.
20 – a page pre-allocated as part of a bulk load operation, which will eventually be formatted as a ‘real' page.
3,Page在索引中的级数
数据页在索引中的索引级数,m_level=0,表示处于Leaf Level。
对于堆表(Heap),m_level=0表示的是Data Page;
对于聚集索引,m_level=0表示的是Data Page;
对于非聚集索引,m_level=0表示的是叶子节点
4, Page的元数据
Page的元数据十分重要,不仅能够查看处Page所在的Object,甚至能够查看该Page所在的分配单元和分区ID,在死锁进行故障排除时十分有用
Metadata: AllocUnitId =72057595905900544,该Page所在的分配单元ID(allocation_unit_id)
Metadata: PartitionId =72057594059423744,该Page所在的分区的分区ID(partition_id)
Metadata: IndexId = 1,该Page所在的索引ID
Metadata: ObjectId = 1029578706,用于表示Page所属对象的object_id
5,page的链指针
由于数据表的Page并不是单独存在的,而是通过双向链式结构连接在一起的,
m_prevPage = (1:8777732) :用于表示前一个page (FileID : PageID)
m_nextPage = (1:8777734) :用于表示下一个page (FileID:PageID)
6, 其他头部字段
m_slotCnt = 2 :页面中Slot的数量,用于Page中存储的数据行数
m_freeCnt = 4513 :页面中剩余的空间,单位是字节,还剩83字节的空间
m_reservedCnt = 0 :为活动事务保留的存储空间,单位是字节
m_ghostRecCnt = 0 :页面中存在的幽灵记录的总数(ghost record count)
关于Page头部的信息,可以阅读《Inside the Storage Engine: Anatomy of a page》;
三,利用Page的元数据排除死锁
Page的元数据包含分区ID,索引ID和对象ID,用户可以使用这些元数据,分析死锁产生的原因。系统追踪到产生死锁的资源,可能是一个Page的资源标识符,如果能够确认发生死锁是由于数据表或索引的分区不合理导致的,那么可以重新设置分区列,或者设置分区边界值,把单个分区拆分成多个分区,这样就能把竞争的临界资源分配到不同的分区中,避免查询请求对资源的竞争,进而减少死锁的发生。
Metadata: PartitionId ,该Page所在的分区的分区ID(partition_id);
Metadata: IndexId ,该Page所在索引ID;
Metadata: ObjectId,用于表示对象的object_id;
相关推荐
-
SQL Server怎么找出一个表包含的页信息(Page)
前言 在SQL Server中,如何找到一张表或某个索引拥有那些页面(page)呢? 有时候,我们在分析和研究(例如,死锁分析)的时候还真有这样的需求,那么如何做呢? SQL Server 2012提供了一个无文档的DMF(sys.dm_db_database_page_allocations)可以实现我们的需求,sys.dm_db_database_page_allocations有下面几个参数: @DatabaseId: 数据库的ID,可以用DB_ID()函数获取某个数据库或当前数据库
-
SQL Server Page结构深入分析
SQL Server存储数据的基本单元是Page,每一个Page的大小是8KB,数据文件是由Page构成的.在同一个数据库上,每一个Page都有一个唯一的资源标识,标识符由三部分组成:db_id,file_id,page_id,例如,15:1:8733,15是数据库的ID,1是数据文件的ID,8733是Page的编号,Page的编号从0依次递增.8个连续的Page组成一个区(Extent),数据文件中已分配(Allocated)的空间被分割成区的整数倍.一次磁盘IO操作作用于Page级别,而空间
-

SQL Server索引结构的具体使用
目录 名词介绍 索引表 数据页 索引是数据库的基础,只有先搞明白索引的结构,才能搞明白索引运行的逻辑 本文通过 索引表.数据页.执行计划.IO统计.B+Tree 来尽可能的介绍 SQL 语句中 WHERE 部分,和 SELECT 部分 的运行逻辑 名词介绍 B+Tree:一种数据结构 数据页:数据库保存数据的最小单位.(SQL Server一个数据页的大小是 8K,一个表中所有的数据都被保存到一个个的数据页中) 索引组织表:大白话一张表有聚集索引就是索引组织表(把表中的数据页以 B+Tree 的
-
SQL Server 索引结构及其使用(一)--深入浅出理解索引结构第1/4页
一.深入浅出理解索引结构 实际上,您可以把索引理解为一种特殊的目录.微软的SQL SERVER提供了两种索引:聚集索引(clustered index,也称聚类索引.簇集索引)和非聚集索引(nonclustered index,也称非聚类索引.非簇集索引). 下面,我们举例来说明一下聚集索引和非聚集索引的区别: 其实,我们的汉语字典的正文本身就是一个聚集索引.比如,我们要查"安"字,就会很自然地翻开字典的前几页,因为"安"的拼音是"an",而按照
-
SQL Server 索引结构及其使用(二) 改善SQL语句第1/3页
比如: select * from table1 where name=''zhangsan'' and tID > 10000 和执行: select * from table1 where tID > 10000 and name=''zhangsan'' 一些人不知道以上两条语句的执行效率是否一样,因为如果简单的从语句先后上看,这两个语句的确是不一样,如果tID是一个聚合索引,那么后一句仅仅从表的10000条以后的记录中查找就行了:而前一句则要先从全表中查找看有几个name=''zhan
-
sql server 表结构修改方法
如果我们需要修改sql server表结构,应该怎么做呢?下面就将教您如何修改sql server表结构的方法,希望对您学习sql server表结构方面能够有所帮助. 向sql server表中增加一个varchar列: ALTER TABLE distributors ADD COLUMN address varchar(30); 从sql server表中删除一个字段: ALTER TABLE distributors DROP COLUMN address RESTRICT; 在一个操作
-
SQL Server中Table字典数据的查询SQL示例代码
前言 在数据库系统原理与设计(第3版)教科书中这样写道: 数据库包含4类数据: 1.用户数据 2.元数据 3.索引 4.应用元数据 其中,元数据也叫数据字典,定义如下: 下面这篇文章就来给大家分享一个关于查询SQL Server Table 结构的SQL 语句. T-SQL 如下: SELECT (case when a.colorder=1 then d.name else '' end) 表名, a.colorder 字段序号,a.name 字段名, (case when a.colorde
-
SQL Server 2008存储结构之GAM、SGAM介绍
当我们创建一个数据库的时候,例如以缺省的方式CREATE DATABASE TESTDB,SQLServer自动帮我们创建好如下两个数据库文件. 这两个数据文件是实实在在的操作系统文件,其中一个是叫行数据文件,用来存储数据库的各种对象,另外一个是日志文件,从来记录数据变化的过程. 从逻辑角度而言,数据库的最小存储单位为页即8kb. 数据库被分成若干逻辑页面(每个页面8KB),并且在每个文件中,所有页面都被连续地从0到x编号,其中x是由文件的大小决定的.我们可以通过指定一个数据库ID.一个文件ID
-
详解SQL Server表和索引存储结构
本文详细分析了SQL Server中表和索引结构存储的原理以及对于如何加快搜索速度和提高效率等方面做了详细的分析,以下是主要内容. 下图显示了表的存储组织,每张表有一个对应的对象ID,并且包含一个或多个分区,每个分区会有一个堆或者多个B树,堆或者B树的结构是预留的.每个堆或者是B树都有三个分配单元用来存放数据,分别是数据.LOB.行溢出,使用最多的分配单元是数据.如果有LOB数据或者是长度超过8000字节的记录,则可能有另外的LOB分配单元和行溢出分配单元. 小总结: 一个表可以有多个分区,但是
-
Sql Server 和 Access 操作数据库结构Sql语句小结
下面是Sql Server 和 Access 操作数据库结构的常用Sql,希望对你有所帮助.内容由海娃整理,不正确与不完整之处还请提出,谢谢. 新建表:create table [表名]([自动编号字段] int IDENTITY (1,1) PRIMARY KEY ,[字段1] nVarChar(50) default '默认值' null ,[字段2] ntext null ,[字段3] datetime,[字段4] money null ,[字段5] int default 0,[字段6]