Java集合系列之LinkedHashMap源码分析
这篇文章我们开始分析LinkedHashMap的源码,LinkedHashMap继承了HashMap,也就是说LinkedHashMap是在HashMap的基础上扩展而来的,因此在看LinkedHashMap源码之前,读者有必要先去了解HashMap的源码,可以查看我上一篇文章的介绍《Java集合系列[3]----HashMap源码分析》。只要深入理解了HashMap的实现原理,回过头来再去看LinkedHashMap,HashSet和LinkedHashSet的源码那都是非常简单的。因此,读者们好好耐下性子来研究研究HashMap源码吧,这可是买一送三的好生意啊。在前面分析HashMap源码时,我采用以问题为导向对源码进行分析,这样使自己不会像无头苍蝇一样乱分析一通,读者也能够针对问题更加深入的理解。本篇我决定还是采用这样的方式对LinkedHashMap进行分析。
1. LinkedHashMap内部采用了什么样的结构?
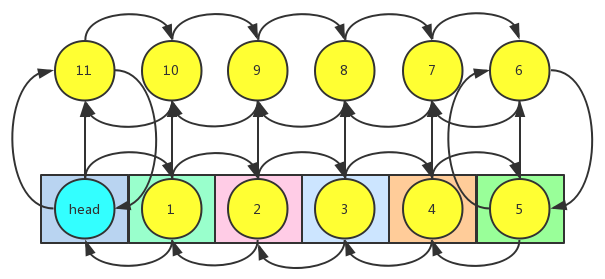
可以看到,由于LinkedHashMap是继承自HashMap的,所以LinkedHashMap内部也还是一个哈希表,只不过LinkedHashMap重新写了一个Entry,在原来HashMap的Entry上添加了两个成员变量,分别是前继结点引用和后继结点引用。这样就将所有的结点链接在了一起,构成了一个双向链表,在获取元素的时候就直接遍历这个双向链表就行了。我们看看LinkedHashMap实现的Entry是什么样子的。
private static class Entry<K,V> extends HashMap.Entry<K,V> {
//当前结点在双向链表中的前继结点的引用
Entry<K,V> before;
//当前结点在双向链表中的后继结点的引用
Entry<K,V> after;
Entry(int hash, K key, V value, HashMap.Entry<K,V> next) {
super(hash, key, value, next);
}
//从双向链表中移除该结点
private void remove() {
before.after = after;
after.before = before;
}
//将当前结点插入到双向链表中一个已存在的结点前面
private void addBefore(Entry<K,V> existingEntry) {
//当前结点的下一个结点的引用指向给定结点
after = existingEntry;
//当前结点的上一个结点的引用指向给定结点的上一个结点
before = existingEntry.before;
//给定结点的上一个结点的下一个结点的引用指向当前结点
before.after = this;
//给定结点的上一个结点的引用指向当前结点
after.before = this;
}
//按访问顺序排序时, 记录每次获取的操作
void recordAccess(HashMap<K,V> m) {
LinkedHashMap<K,V> lm = (LinkedHashMap<K,V>)m;
//如果是按访问顺序排序
if (lm.accessOrder) {
lm.modCount++;
//先将自己从双向链表中移除
remove();
//将自己放到双向链表尾部
addBefore(lm.header);
}
}
void recordRemoval(HashMap<K,V> m) {
remove();
}
}
2. LinkedHashMap是怎样实现按插入顺序排序的?
//父类put方法中会调用的该方法
void addEntry(int hash, K key, V value, int bucketIndex) {
//调用父类的addEntry方法
super.addEntry(hash, key, value, bucketIndex);
//下面操作是方便LRU缓存的实现, 如果缓存容量不足, 就移除最老的元素
Entry<K,V> eldest = header.after;
if (removeEldestEntry(eldest)) {
removeEntryForKey(eldest.key);
}
}
//父类的addEntry方法中会调用该方法
void createEntry(int hash, K key, V value, int bucketIndex) {
//先获取HashMap的Entry
HashMap.Entry<K,V> old = table[bucketIndex];
//包装成LinkedHashMap自身的Entry
Entry<K,V> e = new Entry<>(hash, key, value, old);
table[bucketIndex] = e;
//将当前结点插入到双向链表的尾部
e.addBefore(header);
size++;
}
LinkedHashMap重写了它的父类HashMap的addEntry和createEntry方法。当要插入一个键值对的时候,首先会调用它的父类HashMap的put方法。在put方法中会去检查一下哈希表中是不是存在了对应的key,如果存在了就直接替换它的value就行了,如果不存在就调用addEntry方法去新建一个Entry。注意,这时候就调用到了LinkedHashMap自己的addEntry方法。我们看到上面的代码,这个addEntry方法除了回调父类的addEntry方法之外还会调用removeEldestEntry去移除最老的元素,这步操作主要是为了实现LRU算法,下面会讲到。我们看到LinkedHashMap还重写了createEntry方法,当要新建一个Entry的时候最终会调用这个方法,createEntry方法在每次将Entry放入到哈希表之后,就会调用addBefore方法将当前结点插入到双向链表的尾部。这样双向链表就记录了每次插入的结点的顺序,获取元素的时候只要遍历这个双向链表就行了,下图演示了每次调用addBefore的操作。由于是双向链表,所以将当前结点插入到头结点之前其实就是将当前结点插入到双向链表的尾部。

3. 怎样利用LinkedHashMap实现LRU缓存?
我们知道缓存的实现依赖于计算机的内存,而内存资源是相当有限的,不可能无限制的存放元素,所以我们需要在容量不够的时候适当的删除一些元素,那么到底删除哪个元素好呢?LRU算法的思想是,如果一个数据最近被访问过,那么将来被访问的几率也更高。所以我们可以删除那些不经常被访问的数据。接下来我们看看LinkedHashMap内部是怎样实现LRU机制的。
public class LinkedHashMap<K,V> extends HashMap<K,V> implements Map<K,V> {
//双向链表头结点
private transient Entry<K,V> header;
//是否按访问顺序排序
private final boolean accessOrder;
...
public LinkedHashMap(int initialCapacity, float loadFactor, boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}
//根据key获取value值
public V get(Object key) {
//调用父类方法获取key对应的Entry
Entry<K,V> e = (Entry<K,V>)getEntry(key);
if (e == null) {
return null;
}
//如果是按访问顺序排序的话, 会将每次使用后的结点放到双向链表的尾部
e.recordAccess(this);
return e.value;
}
private static class Entry<K,V> extends HashMap.Entry<K,V> {
...
//将当前结点插入到双向链表中一个已存在的结点前面
private void addBefore(Entry<K,V> existingEntry) {
//当前结点的下一个结点的引用指向给定结点
after = existingEntry;
//当前结点的上一个结点的引用指向给定结点的上一个结点
before = existingEntry.before;
//给定结点的上一个结点的下一个结点的引用指向当前结点
before.after = this;
//给定结点的上一个结点的引用指向当前结点
after.before = this;
}
//按访问顺序排序时, 记录每次获取的操作
void recordAccess(HashMap<K,V> m) {
LinkedHashMap<K,V> lm = (LinkedHashMap<K,V>)m;
//如果是按访问顺序排序
if (lm.accessOrder) {
lm.modCount++;
//先将自己从双向链表中移除
remove();
//将自己放到双向链表尾部
addBefore(lm.header);
}
}
...
}
//父类put方法中会调用的该方法
void addEntry(int hash, K key, V value, int bucketIndex) {
//调用父类的addEntry方法
super.addEntry(hash, key, value, bucketIndex);
//下面操作是方便LRU缓存的实现, 如果缓存容量不足, 就移除最老的元素
Entry<K,V> eldest = header.after;
if (removeEldestEntry(eldest)) {
removeEntryForKey(eldest.key);
}
}
//是否删除最老的元素, 该方法设计成要被子类覆盖
protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {
return false;
}
}
为了更加直观,上面贴出的代码中我将一些无关的代码省略了,我们可以看到LinkedHashMap有一个成员变量accessOrder,该成员变量记录了是否需要按访问顺序排序,它提供了一个构造器可以自己指定accessOrder的值。每次调用get方法获取元素式都会调用e.recordAccess(this),该方法会将当前结点移到双向链表的尾部。现在我们知道了如果accessOrder为true那么每次get元素后都会把这个元素挪到双向链表的尾部。这一步的目的是区别出最常使用的元素和不常使用的元素,经常使用的元素放到尾部,不常使用的元素放到头部。我们再回到上面的代码中看到每次调用addEntry方法时都会判断是否需要删除最老的元素。判断的逻辑是removeEldestEntry实现的,该方法被设计成由子类进行覆盖并重写里面的逻辑。注意,由于最近被访问的结点都被挪动到双向链表的尾部,所以这里是从双向链表头部取出最老的结点进行删除。下面例子实现了一个简单的LRU缓存。
public class LRUMap<K, V> extends LinkedHashMap<K, V> {
private int capacity;
LRUMap(int capacity) {
//调用父类构造器, 设置为按访问顺序排序
super(capacity, 1f, true);
this.capacity = capacity;
}
@Override
public boolean removeEldestEntry(Map.Entry<K, V> eldest) {
//当键值对大于等于哈希表容量时
return this.size() >= capacity;
}
public static void main(String[] args) {
LRUMap<Integer, String> map = new LRUMap<Integer, String>(4);
map.put(1, "a");
map.put(2, "b");
map.put(3, "c");
System.out.println("原始集合:" + map);
String s = map.get(2);
System.out.println("获取元素:" + map);
map.put(4, "d");
System.out.println("插入之后:" + map);
}
}
结果如下:

注:以上全部分析基于JDK1.7,不同版本间会有差异,读者需要注意。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
您可能感兴趣的文章:
- java HashMap,TreeMap与LinkedHashMap的详解
- Java使用LinkedHashMap进行分数排序
- 详解Java中LinkedHashMap
- Java集合框架源码分析之LinkedHashMap详解
- Java中LinkedHashMap源码解析
相关推荐
-
java HashMap,TreeMap与LinkedHashMap的详解
java HashMap,TreeMap与LinkedHashMap的详解 今天上午面试的时候 问到了Java,Map相关的事情,我记错了HashMap和TreeMap相关的内容,回来赶紧尝试了几个demo理解下 package Map; import java.util.*; public class HashMaps { public static void main(String[] args) { Map map = new HashMap(); map.put("a", &
-
Java集合框架源码分析之LinkedHashMap详解
LinkedHashMap简介 LinkedHashMap是HashMap的子类,与HashMap有着同样的存储结构,但它加入了一个双向链表的头结点,将所有put到LinkedHashmap的节点一一串成了一个双向循环链表,因此它保留了节点插入的顺序,可以使节点的输出顺序与输入顺序相同. LinkedHashMap可以用来实现LRU算法(这会在下面的源码中进行分析). LinkedHashMap同样是非线程安全的,只在单线程环境下使用. LinkedHashMap源码剖析 LinkedHashM
-
Java中LinkedHashMap源码解析
概述: LinkedHashMap实现Map继承HashMap,基于Map的哈希表和链该列表实现,具有可预知的迭代顺序. LinedHashMap维护着一个运行于所有条目的双重链表结构,该链表定义了迭代顺序,可以是插入或者访问顺序. LintHashMap的节点对象继承HashMap的节点对象,并增加了前后指针 before after: /** * LinkedHashMap节点对象 */ static class Entry<K,V> extends HashMap.Node<K,V
-
Java使用LinkedHashMap进行分数排序
分数排序的特殊问题 在java中实现排序远比C/C++简单,我们只要让集合中元素对应的类实现Comparable接口,然后调用Collections.sort();方法即可. 这种方法对于排序存在许多相同元素的情况有些浪费,明显即使值相等,两个元素之间也要比较一下,这在现实中是没有意义的. 典型例子就是学生成绩统计的问题,例如高考中,满分是150,成千上万的学生成绩都在0-150之间,平均一个分数的人数成百上千,这时如果排序还用传统方法明显就浪费了. 进一步思考 成绩既然有固定的分数等级,我们可
-

详解Java中LinkedHashMap
初识LinkedHashMap 大多数情况下,只要不涉及线程安全问题,Map基本都可以使用HashMap,不过HashMap有一个问题,就是迭代HashMap的顺序并不是HashMap放置的顺序,也就是无序.HashMap的这一缺点往往会带来困扰,因为有些场景,我们期待一个有序的Map. 这个时候,LinkedHashMap就闪亮登场了,它虽然增加了时间和空间上的开销,但是通过维护一个运行于所有条目的双向链表,LinkedHashMap保证了元素迭代的顺序. 四个关注点在LinkedHashMa
-
Java集合系列之LinkedHashMap源码分析
这篇文章我们开始分析LinkedHashMap的源码,LinkedHashMap继承了HashMap,也就是说LinkedHashMap是在HashMap的基础上扩展而来的,因此在看LinkedHashMap源码之前,读者有必要先去了解HashMap的源码,可以查看我上一篇文章的介绍<Java集合系列[3]----HashMap源码分析>.只要深入理解了HashMap的实现原理,回过头来再去看LinkedHashMap,HashSet和LinkedHashSet的源码那都是非常简单的.因此,读
-
Java集合系列之LinkedList源码分析
上篇我们分析了ArrayList的底层实现,知道了ArrayList底层是基于数组实现的,因此具有查找修改快而插入删除慢的特点.本篇介绍的LinkedList是List接口的另一种实现,它的底层是基于双向链表实现的,因此它具有插入删除快而查找修改慢的特点,此外,通过对双向链表的操作还可以实现队列和栈的功能.LinkedList的底层结构如下图所示. F表示头结点引用,L表示尾结点引用,链表的每个结点都有三个元素,分别是前继结点引用(P),结点元素的值(E),后继结点的引用(N).结点由内部类No
-
Java集合系列之HashMap源码分析
前面我们已经分析了ArrayList和LinkedList这两个集合,我们知道ArrayList是基于数组实现的,LinkedList是基于链表实现的.它们各自有自己的优劣势,例如ArrayList在定位查找元素时会优于LinkedList,而LinkedList在添加删除元素时会优于ArrayList.而本篇介绍的HashMap综合了二者的优势,它的底层是基于哈希表实现的,如果不考虑哈希冲突的话,HashMap在增删改查操作上的时间复杂度都能够达到惊人的O(1).我们先看看它所基于的哈希表的结
-
Java集合系列之ArrayList源码分析
本篇分析ArrayList的源码,在分析之前先跟大家谈一谈数组.数组可能是我们最早接触到的数据结构之一,它是在内存中划分出一块连续的地址空间用来进行元素的存储,由于它直接操作内存,所以数组的性能要比集合类更好一些,这是使用数组的一大优势.但是我们知道数组存在致命的缺陷,就是在初始化时必须指定数组大小,并且在后续操作中不能再更改数组的大小.在实际情况中我们遇到更多的是一开始并不知道要存放多少元素,而是希望容器能够自动的扩展它自身的容量以便能够存放更多的元素.ArrayList就能够很好的满足这样的
-
Java并发系列之Semaphore源码分析
Semaphore(信号量)是JUC包中比较常用到的一个类,它是AQS共享模式的一个应用,可以允许多个线程同时对共享资源进行操作,并且可以有效的控制并发数,利用它可以很好的实现流量控制.Semaphore提供了一个许可证的概念,可以把这个许可证看作公共汽车车票,只有成功获取车票的人才能够上车,并且车票是有一定数量的,不可能毫无限制的发下去,这样就会导致公交车超载.所以当车票发完的时候(公交车以满载),其他人就只能等下一趟车了.如果中途有人下车,那么他的位置将会空闲出来,因此如果这时其他人想要上车
-
Java并发系列之ConcurrentHashMap源码分析
我们知道哈希表是一种非常高效的数据结构,设计优良的哈希函数可以使其上的增删改查操作达到O(1)级别.Java为我们提供了一个现成的哈希结构,那就是HashMap类,在前面的文章中我曾经介绍过HashMap类,知道它的所有方法都未进行同步,因此在多线程环境中是不安全的.为此,Java为我们提供了另外一个HashTable类,它对于多线程同步的处理非常简单粗暴,那就是在HashMap的基础上对其所有方法都使用synchronized关键字进行加锁.这种方法虽然简单,但导致了一个问题,那就是在同一时间
-
Java并发系列之AbstractQueuedSynchronizer源码分析(概要分析)
学习Java并发编程不得不去了解一下java.util.concurrent这个包,这个包下面有许多我们经常用到的并发工具类,例如:ReentrantLock, CountDownLatch, CyclicBarrier, Semaphore等.而这些类的底层实现都依赖于AbstractQueuedSynchronizer这个类,由此可见这个类的重要性.所以在Java并发系列文章中我首先对AbstractQueuedSynchronizer这个类进行分析,由于这个类比较重要,而且代码比较长,为了
-
Java并发系列之CountDownLatch源码分析
CountDownLatch(闭锁)是一个很有用的工具类,利用它我们可以拦截一个或多个线程使其在某个条件成熟后再执行.它的内部提供了一个计数器,在构造闭锁时必须指定计数器的初始值,且计数器的初始值必须大于0.另外它还提供了一个countDown方法来操作计数器的值,每调用一次countDown方法计数器都会减1,直到计数器的值减为0时就代表条件已成熟,所有因调用await方法而阻塞的线程都会被唤醒.这就是CountDownLatch的内部机制,看起来很简单,无非就是阻塞一部分线程让其在达到某个条
-
Java并发系列之CyclicBarrier源码分析
现实生活中我们经常会遇到这样的情景,在进行某个活动前需要等待人全部都齐了才开始.例如吃饭时要等全家人都上座了才动筷子,旅游时要等全部人都到齐了才出发,比赛时要等运动员都上场后才开始.在JUC包中为我们提供了一个同步工具类能够很好的模拟这类场景,它就是CyclicBarrier类.利用CyclicBarrier类可以实现一组线程相互等待,当所有线程都到达某个屏障点后再进行后续的操作.下图演示了这一过程. 在CyclicBarrier类的内部有一个计数器,每个线程在到达屏障点的时候都会调用await
-
Java并发系列之AbstractQueuedSynchronizer源码分析(共享模式)
通过上一篇的分析,我们知道了独占模式获取锁有三种方式,分别是不响应线程中断获取,响应线程中断获取,设置超时时间获取.在共享模式下获取锁的方式也是这三种,而且基本上都是大同小异,我们搞清楚了一种就能很快的理解其他的方式.虽然说AbstractQueuedSynchronizer源码有一千多行,但是重复的也比较多,所以读者不要刚开始的时候被吓到,只要耐着性子去看慢慢的自然能够渐渐领悟.就我个人经验来说,阅读AbstractQueuedSynchronizer源码有几个比较关键的地方需要弄明白,分别是