pandas去除重复列的实现方法
数据准备
假设我们目前有两个数据表:
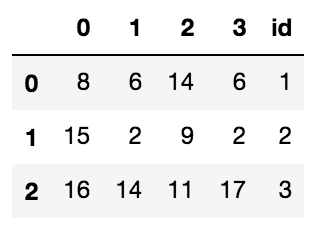
① 一个数据表是关于三个人他们的id以及其他的几列属性信息
import pandas as pd import numpy as np data = pd.DataFrame(np.random.randint(low=1,high=20,size=(3,4))) data['id'] = range(1,4) # 输出:其中,最左边的0 1 2 为其索引
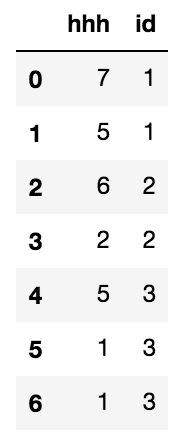
② 另外一个数据表是3个用户的app操作日志信息,一个人会有多条app操作记录
sample = pd.DataFrame(np.random.randint(low=1,high=9,size=(7,1)),columns=['hhh']) sample['id'] = [1,1,2,2,3,3,3] # 输出:
问题描述
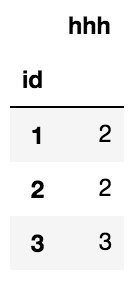
① 首先我们需要统计每个用户app操作记录数,比如上表可以看出用户id为1的用户有2条操作记录,用户id为3的用户有3条操作记录
s = sample.groupby('id').count()
# 输出:
② 此时,S是一个以id为索引,count出来的记录数为value的Series结构。因为考虑到后面我们需要id列进行merge,所以我们需要让id列从索引列变成真实的一列。
s = s.reset_index() # 输出:

③ 将S与最上的data表进行merge,我们不想要看到重复的id列,甚至我们也可以将问题延伸为S与data表不止是id列的重复,还有好多条其他的列的重复,那么如何保证将它们merge之后没有重复列呢?
解决方案
第一想法是用 DataFrame.drop(‘列名') 或者用 del DataFrame[‘列名']
但是如果用该方法,会删除掉所有的重复列,而达不到我们的要求。
办法是: 参考StackOverflow解答
cols_to_use = s.columns.difference(data.columns) # pandas版本在0.15及之上的都可以用这种方法,该方法找出S和data表的不同列,然后再进行merge pd.merge(data, s[cols_to_use], left_index=True, right_index=True, how='outer')

以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
pandas带有重复索引操作方法
有的时候,可能会遇到表格中出现重复的索引,在操作重复索引的时候可能要注意一些问题. 一.判断索引是否重复 a.Series索引重复判断 s = Series([1,2,3,4,5],index=["a","a","b","b","c"]) print(s.index.is_unique) #False Series.index.is_unique为False表示索引重复. b.DataFrame索引重复判断
-
Pandas统计重复的列里面的值方法
pandas 代码如下: import pandas as pd import numpy as np salaries = pd.DataFrame({ 'name': ['BOSS', 'Lilei', 'Lilei', 'Han', 'BOSS', 'BOSS', 'Han', 'BOSS'], 'Year': [2016, 2016, 2016, 2016, 2017, 2017, 2017, 2017], 'Salary': [1, 2, 3, 4, 5, 6, 7, 8], 'Bon
-
pandas 根据列的值选取所有行的示例
如下所示: # 选取等于某些值的行记录 用 == df.loc[df['column_name'] == some_value] # 选取某列是否是某一类型的数值 用 isin df.loc[df['column_name'].isin(some_values)] # 多种条件的选取 用 & df.loc[(df['column'] == some_value) & df['other_column'].isin(some_values)] # 选取不等于某些值的行记录 用 != df.l
-
Pandas标记删除重复记录的方法
Pandas提供了duplicated.Index.duplicated.drop_duplicates函数来标记及删除重复记录 duplicated函数用于标记Series中的值.DataFrame中的记录行是否是重复,重复为True,不重复为False pandas.DataFrame.duplicated(self, subset=None, keep='first') pandas.Series.duplicated(self, keep='first') 其中参数解释如下: subse
-
pandas数据框,统计某列数据对应的个数方法
现在要解决的问题如下: 我们有一个数据的表 第7列有许多数字,并且是用逗号分隔的,数字又有一个对应的关系: 我们要得到第7列对应关系的统计,就是每一行的第7列a有多少个,b有多少个 好了,我给的解决方法如下: #!/bin/python #-*-coding:UTF-8-*- import pandas as pd import numpy as np dfidspec = pd.read_table("one.txt")#这个是对应关系的文件 dfmgs = pd.read_tabl
-
pandas去除重复列的实现方法
数据准备 假设我们目前有两个数据表: ① 一个数据表是关于三个人他们的id以及其他的几列属性信息 import pandas as pd import numpy as np data = pd.DataFrame(np.random.randint(low=1,high=20,size=(3,4))) data['id'] = range(1,4) # 输出:其中,最左边的0 1 2 为其索引 ② 另外一个数据表是3个用户的app操作日志信息,一个人会有多条app操作记录 sample = p
-
pandas统计重复值次数的方法实现
本文主要介绍了pandas统计重复值次数的方法实现,分享给大家,具体如下: from pandas import DataFrame df = DataFrame({'key1':['a','a','b','b','a','a'], 'key2':['one','two','one','two','one','one'], 'data1':[1,2,3,2,1,1], # 'data2':np.random.randn(5) }) # 打印数据框 print(df) # data1 key1 k
-

pandas去除重复值的实战
目录 加载数据 sample抽样函数 指定需要更新的值 append直接添加 append函数用法 根据某一列key值进行去重(key唯一) 加载数据 首先,我们需要加载到所需要的数据,这里我们所需要的数据是同过sample函数采样过来的. import pandas as pd #这里说明一下,clean_beer.csv数据有两千多行数据 #所以从其中采样一部分,来进行演示,当然可以简单实用data.head()也可以做练习 data = pd.read_csv('clean_beer.cs
-
C# EF去除重复列DistinctBy方式
目录 C# EF去除重复列DistinctBy C#集合用Distinct去掉重复的元素,IEqualityComparer<T>原理 json测试数据 实体类型 总结 C# EF去除重复列DistinctBy 在网上看了LinQ有DistinctBy方法,实际在用的时候并没有找到,后来参照了该网站才发现写的是拓展方法 https://www.jb51.net/article/273355.htm 1.添加一个扩展方法 public static class DistinctByCla
-
JavaScript中数组去除重复的三种方法
废话不多说了,具体方法如下所示: 方法一:返回新数组每个位子类型没变 function outRepeat(a){ var hash=[],arr=[]; for (var i = 0; i < a.length; i++) { hash[a[i]]!=null; if(!hash[a[i]]){ arr.push(a[i]); hash[a[i]]=true; } } console.log(arr); } outRepeat([2,4,4,5,"a","a"
-
oracle数据库去除重复数据常用的方法总结
目录 创建测试数据 针对指定列,查出去重后的结果集 distinct row_number() 针对指定列,查出所有重复的行 count having count over 删除所有重复的行 删除重复数据并保留一条 分析函数法 group by 总结 创建测试数据 create table nayi224_180824(col_1 varchar2(10), col_2 varchar2(10), col_3 varchar2(10)); insert into nayi224_180824 s
-
pandas 选取行和列数据的方法详解
前言 本文介绍在 pandas 中如何读取数据行列的方法.数据由行和列组成,在数据库中,一般行被称作记录 (record),列被称作字段 (field).回顾一下我们对记录和字段的获取方式:一般情况下,字段根据名称获取,记录根据筛选条件获取.比如获取 student_id 和 studnent_name 两个字段:记录筛选,比如 sales_amount 大于 10000 的所有记录.对于熟悉 SQL 语句的人来说,就是下面的语句: select student_id, student_name
-
JS去除重复并统计数量的实现方法
js去除重复并统计数量方法 首先点击按钮触发事件,然后用class选择器,迭代要获取的文本(这里最好用text()方法)加入到Array()集合里.然后创建一个map{},遍历Array()集合,取一个值作为map的key,然后判断是否有值,如果没有就输入值1,如果有就累加1.最后就可以统计出重复的有多少个. for(var key in map){}为迭代方法. 这里附上文本格式,方便大家复制. jQuery("#count").on("click",functi
-
Pandas之drop_duplicates:去除重复项方法
方法 DataFrame.drop_duplicates(subset=None, keep='first', inplace=False) 参数 这个drop_duplicate方法是对DataFrame格式的数据,去除特定列下面的重复行.返回DataFrame格式的数据. subset : column label or sequence of labels, optional 用来指定特定的列,默认所有列 keep : {'first', 'last', False}, default '