基于SQL Server OS的任务调度机制详解
简介
SQL Server OS是在Windows之上,用于服务SQL Server的一个用户级别的操作系统层次。它将操作系统部分的功能从整个SQL Server引擎中抽象出来,单独形成一层,以便为存储引擎提供服务。SQL Server OS主要提供了任务调度、内存分配、死锁检测、资源检测、锁管理、Buffer Pool管理等多种功能。本篇文章主要是谈一谈SQL OS中所提供的任务调度机制。
抢占式(Preemptive)调度与非抢占式(non-Preemptive)调度
数据库层面的任务调度的起源是ACM上的一篇名为“Operating System Support for Database Management”。但是对于Windows来说,在操作系统层面专门加入支持数据库的任务调度,还不如在SQL Server中专门抽象出来一层进行调度,既然可以抽象出来一层进行数据库层面的任务调度,那么何不在这个抽象层进行内存和IO等的管理呢?这个想法,就是SQL Server OS的起源。
在Windows NT4之后,Windows任务调度是抢占式的,也就是说Windows任务是根据任务的优先级和时间片来决定。如果一个任务的时间片用完,或是有更高优先级的任务正在等待,那么操作系统可以强制剥夺正在运行的线程(线程是任务调度的基本单位)所占用的CPU,将CPU资源让给其它线程。
但是对于SQL Server来说,这种非合作式的、基于时间片的任务调度机制就不那么合适了。如果SQL Server使用Windows内的任务调度机制来进行任务调度的话,Windows不会根据SQL Server的调度机制进行优化,只是根据时间片和优先级来中断线程,这会导致如下两个缺陷:
Windows不会知道SQL Server中任务(也就是SQL OS中的Task,会在文章后面讲到)的最佳中断点,这势必会造成更多的Context Switch(Context Switch代价非常非常高昂,需要线程字用户态和核心态之间转换),因为Windows调度不是线程本身决定是否该出让CPU,而是由Windows决定。Windows并不会知道当前数据库中对应的线程是否正在做关键任务,只会不分青红皂白的夺取线程的CPU。 连入SQL Server的连接不可能一直在执行,每一个Batch之间会有大量空闲时间。如果每个连接都需要单独占用一个线程,那么SQL Server维护这些线程就需要消耗额外的资源,这是很不明智的。
而对于SQL Server OS来说,线程调度采用的合作模式而不是抢占模式。这是因为这些数据库内的任务都在SQL Server这个SandBox之内,SQL Server充分相信其内线程,所以除非线程主动放弃CPU,SQL Server OS不会强制剥夺线程的CPU。这样一来,虽然Worker之间的切换依然是通过Windows的Context Switch进行,但这种合作模式会大大减少所需Context Switch的次数。
SQL Server决定哪一个时间点哪一个线程运行,是通过一个叫Scheduler的东西进行的,下面让我们来看Scheduler。
Scheduler
SQL Server中每一个逻辑CPU都有一个与之对应的Scheduler,只有拿到Scheduler所有权的任务才允许被执行,Scheduler可以看做一个队SQLOS来说的逻辑CPU。您可以通过sys.dm_os_schedulers这个DMV来看系统中所有的Scheduler,如图1所示。
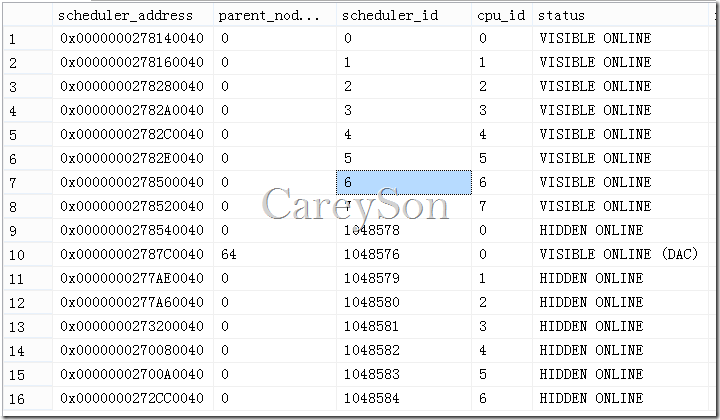
图1.查看sys.dm_os_schedulers
我的笔记本是一个i7四核8线程的CPU,对应的,可以看到除了DAC和运行系统任务的HIDDEN Scheduler,剩下的Scheduler一共8个,每个对应一个逻辑CPU,用于处理内部Task。当然,您也可以通过设置Affinity来将某些Scheduler Offline,如图2所示。注意,这个过程是在线的,无需重启SQL Server就能实现。
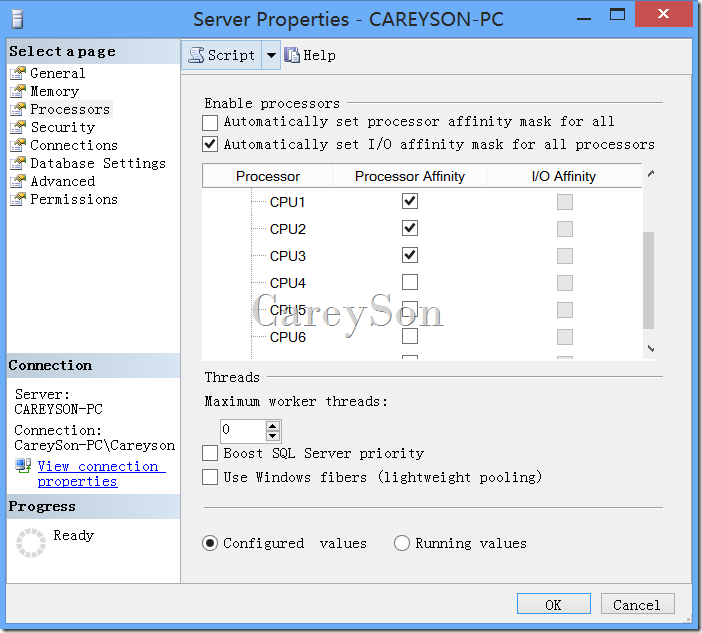
图2.设置Affinity
此时,无需重启实例就能看到4个Scheduler被Offline,如图3所示:
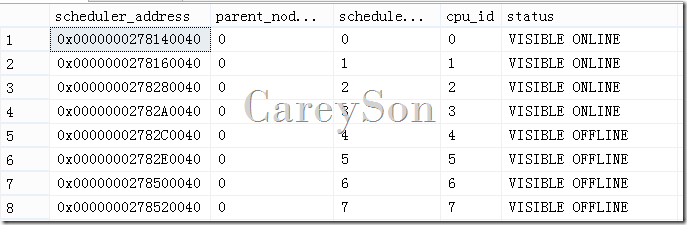
图3.在线Offline 4个Scheduler
一般来说,除非您的服务器上运行其他实例或程序,否则不需要控制Affinity。
在图1中,我们还注意到,除了Visible的Scheduler之外,还有一些特殊的Scheduler,这些Scheduler的ID都大于255,这类Scheduler都用于系统内部使用,比如说资源管理、DAC、备份还原操作等。另外,虽然Scheduler和逻辑CPU的个数一致,但这并不意味着Scheduler和固定的逻辑CPU相绑定,而是Scheduler可以在任何CPU上运行,只有您设置了Affinity Mask之后,Scheduler才会被固定在某个CPU上。这样的一个好处是,当一个Scheduler非常繁忙时,可能不会导致只有一个物理CPU繁忙,因为Scheduler会在多个CPU之间移动,从而使得CPU的使用倾向于平均。
这意味着对于一个比较长的查询,可以前半部分在CPU0上执行,而后半部分在CPU1上执行。
另外,在每一个Scheduler上,同一时间只能有一个Worker运行,所有的资源都就绪但没有拿到Scheduler,那么这个Worker就处于Runnable状态。下面让我们来看一看Worker。
Worker
每一个Worker可以看做是对应一个线程(或纤程),Scheduler不会直接调度线程,而是调度Worker。Worker会随着负载的增加而增加,换句话说,Worker是按需增加,直到增加到最大数字。在SQL Server中,默认的Worker最大数是由SQL Server进行管理的。根据32位还是64位,以及CPU的数量来设置最大Worker,具体的计算公式,您可以参阅BOL:http://msdn.microsoft.com/zh-cn/library/ms187024(v=sql.105).aspx。当然您也可以设置最大Worker数量,如图4所示。
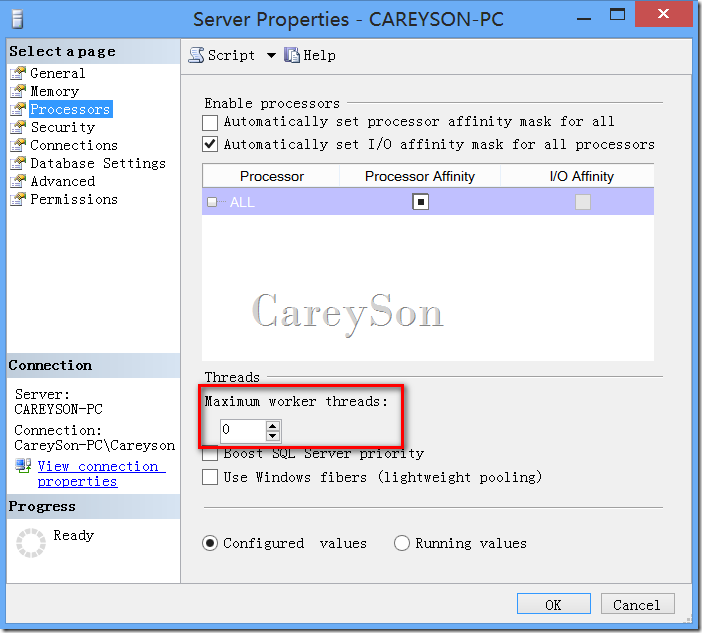
图4.设置最大Worker数量
如果是自动配置,那么SQL Server的最大工作线程数量可以在sys.dm_os_sys_info中看到,如图5所示。
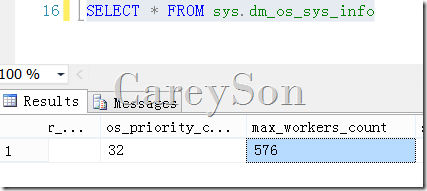
图5.查看自动配置的最大Worker数量
一般来说,这个值您都无需进行设置,但也有一些情况,需要设置这个值。那就是Worker线程用尽,此时除了DAC之外,您甚至无法连入SQL Server。
Worker实际上会对应Windows上的一个线程,并与某个特定Scheduler绑定,每一个Worker只要开始执行Task,除非Task完成,否则Worker永远不会放弃这个Task,如果一个Task在运行过程由于锁、IO等陷入等待,那么实际上Worker就会陷入等待。
此外,同一个连接内的多个Batch之间倾向于使用同一个Worker,比如第一个Batch使用了Worker 100,那么第二个Batch也同样倾向于是用Worker 100,但这并不绝对。
正在运行的任务所是用的Worker,我们可以通过DMV sys.dm_exec_requests查看正在运行的任务,其中的Task_Address列可以看到正在运行的Task,再通过sys.dm_os_tasks的Worker_Address来查看对应的Worker。
SQL Server会为每一个Worker保留大约2M左右的内存,对于每一个Scheduler上所能有的Worker数量是服务器的最大Worker数量/在线的Scheduler,每一个Scheduler所绑定的Worker会形成Worker池,这意味着每一个Scheduler需要Worker时,首先在Worker池中中查找空闲的Worker,如果没有空闲的Worker时,才会创建新的Worker。这个行为会和连接池类似。
那么当一个Scheduler空闲超过15分钟,或是Windows面临内存压力时。SQL Server就会尝试Trim这个Worker池来释放被Worker所占用的内存。
Task
Task是Worker上运行的最小任务单元。只能拿到Worker的Task才能够运行。我们可以看下面一个简单的例子,如代码1所示。
SELECT @@VERSION goSELECT @@SPID go
代码1.一个连接上的两个Batch
代码1中的两个Batch属于一个连接,每一个Batch中都是一个简单的Task,如我们前面所说,这两个Task更倾向于复用同一个Worker,因为他们属于同一个连接。但也有可能,这两个Task使用了不同的Worker,甚至是不同的Scheduler。
除了用户所用的Task之外,还有一些永久的系统Task,这类Task会永远占据Worker,这些Task包括死锁检测、Lazy Writer等。
Task在Scheduler上的平均分配
新的Task还会尝试在Scheduler之间平均分配,可以通过sys.dm_os_schedulers来看到一个load_factor列,这列的值就是用于供Task向Scheduler进行分配时,用来参考。
每次一个新的Task进入Node时,会选择负载最少的的Scheduler。但是,如果每次都来做一次选择,那么就会在Task入队时造成瓶颈(这个瓶颈类似于TempDB SGAM页争抢)。因此SQL OS对于每一个连接,都会记住上次运行的Scheduler ID,在新的Task进入时作为提示(Hint)。但如果一个Scheduler的负载大于所有Scheduler平均值的20%,则会忽略这个提示。负载可以通过上面提到的load_factor列来看,对于某个Task运行的时间比较长,则很有可能造成Scheduler上Task分配的不均匀。
Worker的Yield
由于SQL Server是非抢占式调度,那么就不能为了完成某个Task,让Worker占据Scheduler一直运行。如果是这样,那么处于Runnable的Worker将会饥饿,这不利于大量并发,也违背了SQL OS调度的初衷。
因此,在合适的时间点让出Scheduler就是关键。Worker让出CPU使得其它Worker可以运行的过程称之为yield。yield大体可分为两种,一种是所谓的“natural yield”,这种方式是Worker在运行过程中被锁或是某些资源阻塞,此时,该Worker就会让出Scheduler来让其它Worker运行。另外一种情况是Worker没有遇到阻塞,但在时间片到了之后,主动让出Scheduler,这就是所谓的“voluntarily yield”,这也就是SOS_SCHEDULER_YIELD等待类型的由来,一个Worker由RUNNING状态转到WAITING状态的过程被称之为switching。SQL OS的一个基本思想就是,要多进行switching,来保证高并发。下面我们来看几种常见的yield场景:
基于时间片的voluntarily yield大概使得Worker每4秒yield一次。这个值可以通过sys.dm_os_schedulers的quantum_length_us列看到。
每64K结果集排序,就做一次yield。
语句complie,会做yield。
读取数据页时
batch中每一句话做完,就会做一次yield。
如果客户端不能及时取走数据,worker也会做yield。
SQL Server OS中的抢占式任务调度
对于一些代码来说,SQL Server会存在一些抢占式代码。如果您在等待类型中看到“PREEMPTIVE_*”类型的等待,说明这里面的代码正在运行在抢占式任务调度模式。这类任务包括扩展存储过程、调用Windows API、日志增长(日志填0)。我们知道,合作式的任务调度需要任务本身Yield,但这类代码在SQL Server 之外,如果让他们运行在合作式任务调度这个SandBox之内,这类代码如果不yield,则会永远占用Scheduler。这是非常危险的。
因此,在进入抢占式模式之前,首先需要将Scheduler的控制权交给在Runable队列中的下一个Worker。此时,抢占式模式运行的代码不再由SQL OS控制,转而由Windows任务调度系统控制。因此一个Task的生命周期如果再加上转到抢占式任务调度模式,则会如图6所示。
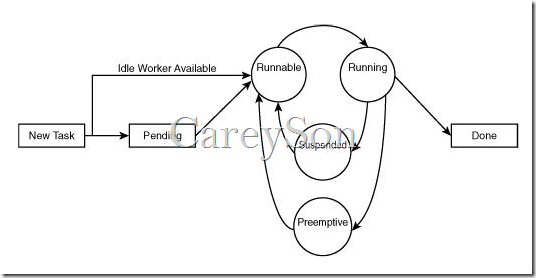
图6.一个Task完整的生命周期
每一个Scheduler的任务调度
对于每一个Scheduler的调度,一个简单的模型如图7所示。 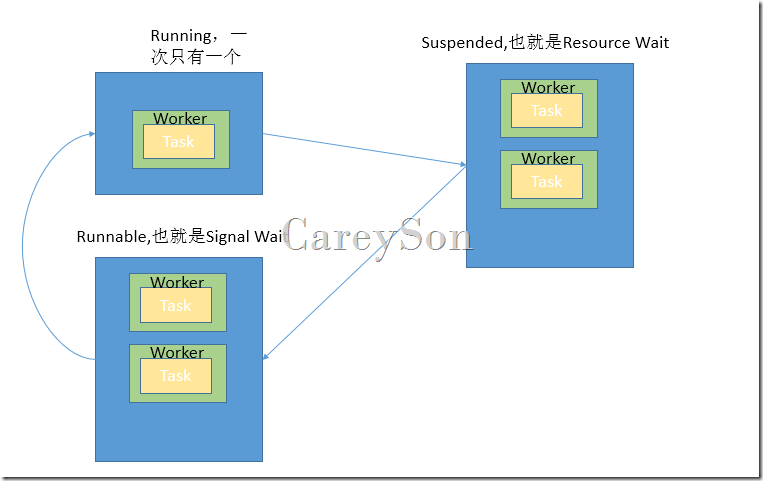
图7.一个Scheduler的调度周期模型
小结
SQL Server OS在Windows之上抽象出一套非抢占式的任务调度机制,从而减少了Context Switch。同时,又有一套线程自己的yield机制,相比Windows随机抢占数据库之内的线程而言,让线程自己来yield则会大量减少Context Switch,从而提升了并发性。
相关推荐
-
java多线程并发executorservice(任务调度)类
复制代码 代码如下: package com.yao; import java.util.concurrent.Executors;import java.util.concurrent.ScheduledExecutorService;import java.util.concurrent.ScheduledFuture;import java.util.concurrent.TimeUnit; /** * 以下是一个带方法的类,它设置了 ScheduledExecutorService ,2
-
PL/SQL实现Oracle数据库任务调度
正在看的ORACLE教程是:PL/SQL实现Oracle数据库任务调度.摘要:本文主要就数据库恢复与系统任务的调度,在结合一般性的数据库后台处理的经验上,提出较为实用而新颖的解决方法,拓宽了数据库后台开发的思路. 关键词:数据恢复,任务调度,ORACLE,PL/SQL 在数据库操作中时常会有这样的情况发生,由于一时的疏忽而误删或误改了一些重要的数据,另外还有一些重要的任务需要周期性地运行.显然,前一类问题主要是数据备份与恢复方面的,而后一类则主要是系统的任务调度.本文将针对这两类问题,从应用程序
-

基于SQL Server OS的任务调度机制详解
简介 SQL Server OS是在Windows之上,用于服务SQL Server的一个用户级别的操作系统层次.它将操作系统部分的功能从整个SQL Server引擎中抽象出来,单独形成一层,以便为存储引擎提供服务.SQL Server OS主要提供了任务调度.内存分配.死锁检测.资源检测.锁管理.Buffer Pool管理等多种功能.本篇文章主要是谈一谈SQL OS中所提供的任务调度机制. 抢占式(Preemptive)调度与非抢占式(non-Preemptive)调度 数据库层面的任务调度的
-
SQL Server 2012 FileTable 新特性详解
FileTable是基于FILESTREAM的一个特性.有以下一些功能: •一行表示一个文件或者目录. •每行包含以下信息: • •file_Stream流数据,stream_id标示符(GUID). •用户表示和维护文件及目录层次关系的path_locator和parent_path_locator •有10个文件属性 •支持对文件和文档的全文搜索和语义搜索的类型列. •filetable强制执行某些系统定义的约束和触发器来维护命名空间的语义 •针对非事务访问时,SQL Server配置FIL
-
SQL Server实现全文搜索查询详解
目录 一.概述 二.全文搜索查询 三.将全文搜索查询与 LIKE 谓词进行比较 四.全文搜索体系结构 4.1.SQL Server 进程 4.2.过滤器守护程序主机进程 五.全文搜索处理 5.1.全文索引过程 5.2.全文查询流程 六.全文索引体系结构 6.1.全文索引结构 6.2.全文索引片段 6.3.全文索引和常规 SQL Server 索引之间的差异 总结 一.概述 全文索引在表中包括一个或多个基于字符的列.这些列可以具有以下任何数据类型:char.varchar.nchar.nvarch
-
sql server 交集,差集的用法详解
概述 为什么使用集合运算: 在集合运算中比联接查询和EXISTS/NOT EXISTS更方便. 并集运算(UNION) 并集:两个集合的并集是一个包含集合A和B中所有元素的集合. 在T-SQL中.UNION集合运算可以将两个输入查询的结果组合成一个结果集.需要注意的是:如果一个行在任何一个输入集合中出现,它也会在UNION运算的结果中出现.T-SQL支持以下两种选项: (1)UNION ALL:不会删除重复行 -- union allselect country, region, city fr
-
SQL Server批量插入数据案例详解
在SQL Server 中插入一条数据使用Insert语句,但是如果想要批量插入一堆数据的话,循环使用Insert不仅效率低,而且会导致SQL一系统性能问题.下面介绍SQL Server支持的两种批量数据插入方法:Bulk和表值参数(Table-Valued Parameters),高效插入数据. 新建数据库: --Create DataBase create database BulkTestDB; go use BulkTestDB; go --Create Table Create tab
-
SQL Server的行级安全性详解
目录 一.前言 二.描述 三.权限 四.安全说明:侧信道攻击 五.跨功能兼容性 六.示例 一.前言 行级别安全性使您能够使用组成员身份或执行上下文来控制对数据库表中行的访问. 行级别安全性 (RLS) 简化了应用程序中的安全性设计和编码.RLS 可帮助您对数据行访问实施限制.例如,您可以确保工作人员仅访问与其部门相关的数据行.另一个示例是将客户的数据访问限制为仅与其公司相关的数据. 访问限制逻辑位于数据库层中,而不是远离另一个应用程序层中的数据.每次尝试从任何层访问数据时,数据库系统都会应用访问
-
SQL Server中索引的用法详解
目录 一.索引的介绍 什么是索引? 1.聚集索引和非聚集索引 2.索引的利弊 3.索引的存储机制 二.设置索引的权衡 1.什么情况下设置索引 2.什么情况下不要设置索引 三.聚集索引 1.使用SSMS创建聚集索引 2.使用T-SQL创建聚集索引 四.非聚集索引 1.SSMS创建方法同上,T-SQL创建方法如下: 2.添加索引选项 五.示例 六.管理索引 一.索引的介绍 什么是索引? 索引是一种磁盘上的数据结构,建立在表或视图的基础上.使用索引可以使数据的获取更快更高校,也会影响其他的一些性能,如
-
SQL Server时间戳功能与用法详解
本文实例讲述了SQL Server时间戳功能与用法.分享给大家供大家参考,具体如下: 一直对时间戳这个概念比较模糊,相信有很多朋友也都会误认为:时间戳是一个时间字段,每次增加数据时,填入当前的时间值.其实这误导了很多朋友. 1.基本概念 时间戳:数据库中自动生成的唯一二进制数字,与时间和日期无关的, 通常用作给表行加版本戳的机制.存储大小为 8个字节. 每个数据库都有一个计数器,当对数据库中包含 timestamp 列的表执行插入或更新操作时,该计数器值就会增加.该计数器是数据库时间戳.这 可以
-
sql server 自定义分割月功能详解及实现代码
在最近的项目开发过程中,遇到了Sql server自动分割月的功能需求,这里在网上整理下资料. 1.为何出现自定义分割月的需求 今天梳理一个平台的所有函数时,发现了一个自定义分割月函数,也就是指定分割月的开始日索引值(可以从1-31闭区间内的任何一个值)来获取指定日期所对应的分割月数值.这个函数当时是为了解决业务部门获取非标准月(标准月就是从每个月的第一天到最后一天组成一个完成的标准月份)的统计汇总数据的.例如:如果指定分割月的开始日索引值为5则表示某个月的5号到下个月的4号之间作为一个完整的分
-
Python操作Sql Server 2008数据库的方法详解
本文实例讲述了Python操作Sql Server 2008数据库的方法.分享给大家供大家参考,具体如下: 最近由于公司的一个项目需要,需要使用Sql Server 2008数据库,开发语言使用Python,并基于windows平台上的Wing IDE4.0进行. 之前并未使用过Sql Server数据库,这次也当作一次练手,并把这次数据库前期开发过程中遇到的一些问题进行记录. 一.关于pyodbc库和pymssql库的选择 在使用python语言进行开发之前,需要确定使用哪种第三方的数据库操作