js实现敏感词过滤算法及实现逻辑
最近弄了一个用户发表评论的功能,用户上传了评论,再文章下可以看到自己的评论,但作为社会主义接班人,践行社会主义核心价值观,所以给评论敏感词过滤的功能不可少,在网上找了资料,发现已经有非常成熟的解决方案。 常用的方案用这么两种
1.全文搜索,逐个匹配。这种听起来就不够高大上,在数据量大的情况下,会有效率问题,文末有比较
2.DFA算法-确定有限状态自动机 附上百科链接确定有限状态自动机
DFA算法介绍
DFA是一种计算模型,数据源是一个有限个集合,通过当前状态和事件来确定下一个状态,即 状态+事件=下一状态,由此逐步构建一个有向图,其中的节点就是状态,所以在DFA算法中只有查找和判断,没有复杂的计算,从而提高算法效率
参考文章 Java实现敏感词过滤
实现逻辑
构造数据结构
将敏感词转换成树结构,举例敏感词有着这么几个 ['日本鬼子','日本人','日本男人'] ,那么数据结构如下(图片引用参考文章)

每个文字是一个节点,连续的节点组成一个词, 日本人 对应的就是中间的那条链,我们可以使用对象或者map来构建树,这里的栗子采用 map 构建节点,每个节点中有个状态标识,用来表示当前节点是不是最后一个,每条链路必须要有个终点节点,先来看下构建节点的流程图
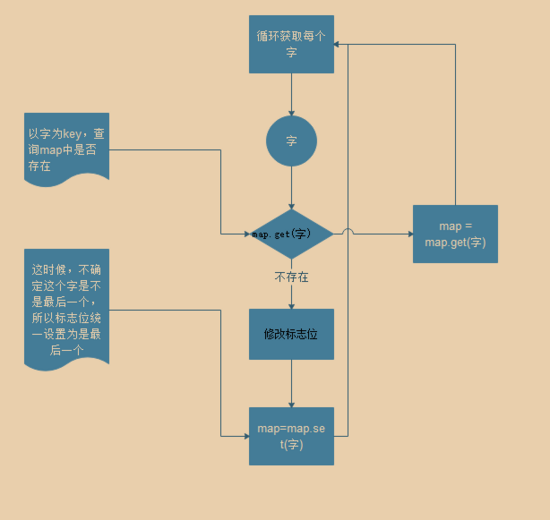
判断逻辑
先从文本的第一个字开始检查,比如 你我是日本鬼子 ,第一个字 你 ,在树的第一层找不到这个节点,那么继续找第二个字,到了 日 的时候,第一层节点找到了,那么接着下一层节点中查找 本 ,同时判断这个节点是不是结尾节点,若是结尾节点,则匹配成功了,反之继续匹配
代码实现
####构造数据结构
/**
* @description
* 构造敏感词map
* @private
* @returns
*/
private makeSensitiveMap(sensitiveWordList) {
// 构造根节点
const result = new Map();
for (const word of sensitiveWordList) {
let map = result;
for (let i = 0; i < word.length; i++) {
// 依次获取字
const char = word.charAt(i);
// 判断是否存在
if (map.get(char)) {
// 获取下一层节点
map = map.get(char);
} else {
// 将当前节点设置为非结尾节点
if (map.get('laster') === true) {
map.set('laster', false);
}
const item = new Map();
// 新增节点默认为结尾节点
item.set('laster', true);
map.set(char, item);
map = map.get(char);
}
}
}
return result;
}
最终map结构如下
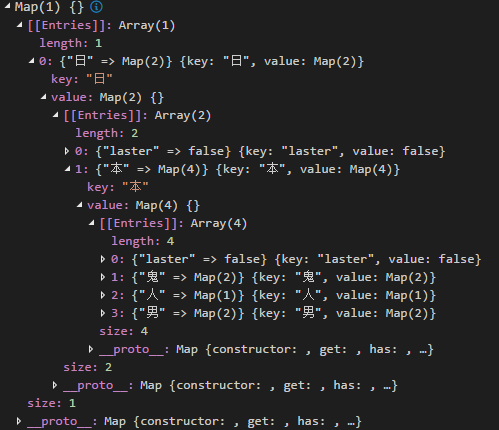
查找敏感词
/**
* @description
* 检查敏感词是否存在
* @private
* @param {any} txt
* @param {any} index
* @returns
*/
private checkSensitiveWord(sensitiveMap, txt, index) {
let currentMap = sensitiveMap;
let flag = false;
let wordNum = 0;//记录过滤
let sensitiveWord = ''; //记录过滤出来的敏感词
for (let i = index; i < txt.length; i++) {
const word = txt.charAt(i);
currentMap = currentMap.get(word);
if (currentMap) {
wordNum++;
sensitiveWord += word;
if (currentMap.get('laster') === true) {
// 表示已到词的结尾
flag = true;
break;
}
} else {
break;
}
}
// 两字成词
if (wordNum < 2) {
flag = false;
}
return { flag, sensitiveWord };
}
/**
* @description
* 判断文本中是否存在敏感词
* @param {any} txt
* @returns
*/
public filterSensitiveWord(txt, sensitiveMap) {
let matchResult = { flag: false, sensitiveWord: '' };
// 过滤掉除了中文、英文、数字之外的
const txtTrim = txt.replace(/[^\u4e00-\u9fa5\u0030-\u0039\u0061-\u007a\u0041-\u005a]+/g, '');
for (let i = 0; i < txtTrim.length; i++) {
matchResult = checkSensitiveWord(sensitiveMap, txtTrim, i);
if (matchResult.flag) {
console.log(`sensitiveWord:${matchResult.sensitiveWord}`);
break;
}
}
return matchResult;
}
效率
为了看出DFA的效率,我做了个简单的小测试,测试的文本长度为5095个汉字,敏感词词库中有2000个敏感词,比较的算法分别为 DFA算法 和 String原生对象提供的 indexOf API做比较
// 简单的字符串匹配-indexOf
ensitiveWords.forEach((word) => {
if (ss.indexOf(word) !== -1) {
console.log(word)
}
})
分别将两个算法执行100次,得到如下结果
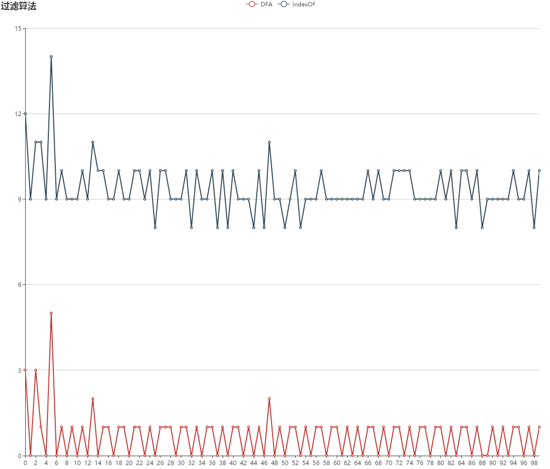
可直观看出, DFA 的平均耗时是在1ms左右,最大为5ms; indexOf 方式的平均耗时在9ms左右,最大为14ms,所以DFA效率上还是非常明显有优势的。
总结
以上所述是小编给大家介绍的js实现敏感词过滤算法及实现逻辑,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对我们网站的支持!
相关推荐
-

JS使用ActiveXObject实现用户提交表单时屏蔽敏感词功能
本例中敏感词ciku.txt放在C盘根目录下,采用的ActiveXObject插件获取本地文件内容.使用此插件不需网上下插件,直接用如下js代码即可. 浏览器需修改interner安全选项的级别,启用ActiveX才能获取到代码中的ActiveXObject插件.如下图所示: js代码实现如下: <script type="text/javascript"> // -------------- 全局变量,用来判断文本域中是否包含脏词,默认为false,即不包含脏词-----
-
JS敏感词过滤代码
过滤敏感.不良词汇.本文主要讲述两种方式过滤敏感词汇. 我在这里直接以函数的形式体现出来,也就是说,用的时候直接调用函数即可. 方式一.RegExp() function filter() { // 获取输入框的内容inputContent var inputContent = input.value; // 多个敏感词,这里直接以数组的形式展示出来 var arrMg = ["fuck", "tmd", "他妈的"]; // 显示的内容--sh
-
JavaScript实现自动对页面上敏感词进行屏蔽的方法
本文实例讲述了JavaScript实现自动对页面上敏感词进行屏蔽的方法.分享给大家供大家参考.具体如下: <html> <head> <title>Bad Words Example</title> <script type="text/javascript"> function filterText(sText) { var reBadWords = /badword|anotherbadword/gi; return sT
-
Jsp敏感词过滤的示例代码
大部分论坛.网站等,为了方便管理,都进行了关于敏感词的设定. 在多数网站,敏感词一般是指带有敏感政治倾向(或反执政党倾向).暴力倾向.不健康色彩的词或不文明语,也有一些网站根据自身实际情况,设定一些只适用于本网站的特殊敏感词. 比如,当你发贴的时候带有某些事先设定的词时,这个贴是不能发出的.或者这个词被自动替换为星号(*)或叉号(X)等,或者说是被和谐掉了. 在我看来敏感词过滤最重要的是在写过滤词汇的算法,如何过滤出大批量的敏感词,我感觉DFA的思想不错 DFA简介 在实现文字过滤的算法中,DF
-
js实现敏感词过滤算法及实现逻辑
最近弄了一个用户发表评论的功能,用户上传了评论,再文章下可以看到自己的评论,但作为社会主义接班人,践行社会主义核心价值观,所以给评论敏感词过滤的功能不可少,在网上找了资料,发现已经有非常成熟的解决方案. 常用的方案用这么两种 1.全文搜索,逐个匹配.这种听起来就不够高大上,在数据量大的情况下,会有效率问题,文末有比较 2.DFA算法-确定有限状态自动机 附上百科链接确定有限状态自动机 DFA算法介绍 DFA是一种计算模型,数据源是一个有限个集合,通过当前状态和事件来确定下一个状态,即 状态+事件
-
java利用DFA算法实现敏感词过滤功能
前言 敏感词过滤应该是不用给大家过多的解释吧?讲白了就是你在项目中输入某些字(比如输入xxoo相关的文字时)时要能检 测出来,很多项目中都会有一个敏感词管理模块,在敏感词管理模块中你可以加入敏感词,然后根据加入的敏感词去过滤输 入内容中的敏感词并进行相应的处理,要么提示,要么高亮显示,要么直接替换成其它的文字或者符号代替. 敏感词过滤的做法有很多,我简单描述我现在理解的几种: ①查询数据库当中的敏感词,循环每一个敏感词,然后去输入的文本中从头到尾搜索一遍,看是否存在此敏感词,有则做相 应的处理,
-
Python基于DFA算法实现内容敏感词过滤
DFA 算法是通过提前构造出一个 树状查找结构,之后根据输入在该树状结构中就可以进行非常高效的查找. 设我们有一个敏感词库,词酷中的词汇为: 我爱你 我爱他 我爱她 我爱你呀 我爱他呀 我爱她呀 我爱她啊 那么就可以构造出这样的树状结构: 设玩家输入的字符串为:白菊我爱你呀哈哈哈 我们遍历玩家输入的字符串 str,并设指针 i 指向树状结构的根节点,即最左边的空白节点: str[0] = ‘白’ 时,此时 tree[i] 没有指向值为 ‘白’ 的节点,所以不满足匹配条件,继续往下遍历 str[1
-
Java实现敏感词过滤实例
敏感词.文字过滤是一个网站必不可少的功能,如何设计一个好的.高效的过滤算法是非常有必要的.前段时间我一个朋友(马上毕业,接触编程不久)要我帮他看一个文字过滤的东西,它说检索效率非常慢.我把它程序拿过来一看,整个过程如下:读取敏感词库.如果HashSet集合中,获取页面上传文字,然后进行匹配.我就想这个过程肯定是非常慢的.对于他这个没有接触的人来说我想也只能想到这个,更高级点就是正则表达式.但是非常遗憾,这两种方法都是不可行的.当然,在我意识里没有我也没有认知到那个算法可以解决问题,但是Googl
-
python 实现敏感词过滤的方法
如下所示: #!/usr/bin/python2.6 # -*- coding: utf-8 -*- import time class Node(object): def __init__(self): self.children = None # The encode of word is UTF-8 def add_word(root,word): node = root for i in range(len(word)): if node.children == None: node.c
-
Python实现敏感词过滤的4种方法
在我们生活中的一些场合经常会有一些不该出现的敏感词,我们通常会使用*去屏蔽它,例如:尼玛 -> **,一些骂人的敏感词和一些政治敏感词都不应该出现在一些公共场合中,这个时候我们就需要一定的手段去屏蔽这些敏感词.下面我来介绍一些简单版本的敏感词屏蔽的方法. (我已经尽量把脏话做成图片的形式了,要不然文章发不出去) 方法一:replace过滤 replace就是最简单的字符串替换,当一串字符串中有可能会出现的敏感词时,我们直接使用相应的replace方法用*替换出敏感词即可. 缺点: 文本和敏感词少
-
servlet实现简单的权限管理和敏感词过滤功能
前言 JavaEE课要求用servlet和过滤器实现权限管理和敏感词过滤功能,故有此文. 虽然早已知道了原理和用法,但是实际操作起来还是遇到了各种奇葩的情况. 一.如何实现权限管理 1.思路 当用户访问某个资源时,我们必须对其权限控制,所以得用到servlet中过滤器来对请求做一次预处理,判断该用户是否有权限访问该资源,如果有则放行;如果没有则返回拒绝访问的通知. 那么我们如何判断该用户是否有权限访问呢? 这就要求我们在用户登录的时候保存其登录状态. 可我们知道http请求是无状态的,即这次请求
-
C#敏感词过滤实现方法
本文实例讲述了C#敏感词过滤实现方法.分享给大家供大家参考.具体如下: 这两天突然想到了敏感词过滤 就结合网上找到的资料自己写了一个,脏字数量700+(效率不是很高 测试在110多KB的情况下比replace快 3-4倍) 测试结果图 单位:秒 代码如下: System.Text.StringBuilder sb = new System.Text.StringBuilder(text.Length); string filterText = "需要过滤的脏字 以|分开"; //脏字
-
浅谈Python 敏感词过滤的实现
一个简单的实现 class NaiveFilter(): '''Filter Messages from keywords very simple filter implementation >>> f = NaiveFilter() >>> f.add("sexy") >>> f.filter("hello sexy baby") hello **** baby ''' def __init__(self):