python tensorflow学习之识别单张图片的实现的示例
假设我们已经安装好了tensorflow。
一般在安装好tensorflow后,都会跑它的demo,而最常见的demo就是手写数字识别的demo,也就是mnist数据集。
然而我们仅仅是跑了它的demo而已,可能很多人会有和我一样的想法,如果拿来一张数字图片,如何应用我们训练的网络模型来识别出来,下面我们就以mnist的demo来实现它。
1.训练模型
首先我们要训练好模型,并且把模型model.ckpt保存到指定文件夹
saver = tf.train.Saver() saver.save(sess, "model_data/model.ckpt")
将以上两行代码加入到训练的代码中,训练完成后保存模型即可,如果这部分有问题,你可以百度查阅资料,tensorflow怎么保存训练模型,在这里我们就不罗嗦了。
2.测试模型
我们训练好模型后,将它保存在了model_data文件夹中,你会发现文件夹中出现了4个文件

然后,我们就可以对这个模型进行测试了,将待检测图片放在images文件夹下,执行
# -*- coding:utf-8 -*-
import cv2
import tensorflow as tf
import numpy as np
from sys import path
path.append('../..')
from common import extract_mnist
#初始化单个卷积核上的参数
def weight_variable(shape):
initial = tf.truncated_normal(shape, stddev=0.1)
return tf.Variable(initial)
#初始化单个卷积核上的偏置值
def bias_variable(shape):
initial = tf.constant(0.1, shape=shape)
return tf.Variable(initial)
#输入特征x,用卷积核W进行卷积运算,strides为卷积核移动步长,
#padding表示是否需要补齐边缘像素使输出图像大小不变
def conv2d(x, W):
return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME')
#对x进行最大池化操作,ksize进行池化的范围,
def max_pool_2x2(x):
return tf.nn.max_pool(x, ksize=[1, 2, 2, 1],strides=[1, 2, 2, 1], padding='SAME')
def main():
#定义会话
sess = tf.InteractiveSession()
#声明输入图片数据,类别
x = tf.placeholder('float',[None,784])
x_img = tf.reshape(x , [-1,28,28,1])
W_conv1 = weight_variable([5, 5, 1, 32])
b_conv1 = bias_variable([32])
W_conv2 = weight_variable([5,5,32,64])
b_conv2 = bias_variable([64])
W_fc1 = weight_variable([7*7*64,1024])
b_fc1 = bias_variable([1024])
W_fc2 = weight_variable([1024,10])
b_fc2 = bias_variable([10])
saver = tf.train.Saver(write_version=tf.train.SaverDef.V1)
saver.restore(sess , 'model_data/model.ckpt')
#进行卷积操作,并添加relu激活函数
h_conv1 = tf.nn.relu(conv2d(x_img,W_conv1) + b_conv1)
#进行最大池化
h_pool1 = max_pool_2x2(h_conv1)
#同理第二层卷积层
h_conv2 = tf.nn.relu(conv2d(h_pool1,W_conv2) + b_conv2)
h_pool2 = max_pool_2x2(h_conv2)
#将卷积的产出展开
h_pool2_flat = tf.reshape(h_pool2,[-1,7*7*64])
#神经网络计算,并添加relu激活函数
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat,W_fc1) + b_fc1)
#输出层,使用softmax进行多分类
y_conv=tf.nn.softmax(tf.matmul(h_fc1, W_fc2) + b_fc2)
# mnist_data_set = extract_mnist.MnistDataSet('../../data/')
# x_img , y = mnist_data_set.next_train_batch(1)
im = cv2.imread('images/888.jpg',cv2.IMREAD_GRAYSCALE).astype(np.float32)
im = cv2.resize(im,(28,28),interpolation=cv2.INTER_CUBIC)
#图片预处理
#img_gray = cv2.cvtColor(im , cv2.COLOR_BGR2GRAY).astype(np.float32)
#数据从0~255转为-0.5~0.5
img_gray = (im - (255 / 2.0)) / 255
#cv2.imshow('out',img_gray)
#cv2.waitKey(0)
x_img = np.reshape(img_gray , [-1 , 784])
print x_img
output = sess.run(y_conv , feed_dict = {x:x_img})
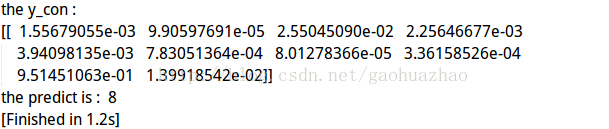
print 'the y_con : ', '\n',output
print 'the predict is : ', np.argmax(output)
#关闭会话
sess.close()
if __name__ == '__main__':
main()
ok,贴一下效果图

输出:
最后再贴一个cifar10的,感觉我的输入数据有点问题,因为直接读cifar10的数据测试是没问题的,但是换成自己的图片做预处理后输入结果就有问题,(参考:cv2读入的数据是BGR顺序,PIL读入的数据是RGB顺序,cifar10的数据是RGB顺序),哪位童鞋能指出来记得留言告诉我
# -*- coding:utf-8 -*-
from sys import path
import numpy as np
import tensorflow as tf
import time
import cv2
from PIL import Image
path.append('../..')
from common import extract_cifar10
from common import inspect_image
#初始化单个卷积核上的参数
def weight_variable(shape):
initial = tf.truncated_normal(shape, stddev=0.1)
return tf.Variable(initial)
#初始化单个卷积核上的偏置值
def bias_variable(shape):
initial = tf.constant(0.1, shape=shape)
return tf.Variable(initial)
#卷积操作
def conv2d(x, W):
return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME')
def main():
#定义会话
sess = tf.InteractiveSession()
#声明输入图片数据,类别
x = tf.placeholder('float',[None,32,32,3])
y_ = tf.placeholder('float',[None,10])
#第一层卷积层
W_conv1 = weight_variable([5, 5, 3, 64])
b_conv1 = bias_variable([64])
#进行卷积操作,并添加relu激活函数
conv1 = tf.nn.relu(conv2d(x,W_conv1) + b_conv1)
# pool1
pool1 = tf.nn.max_pool(conv1, ksize=[1, 3, 3, 1], strides=[1, 2, 2, 1],padding='SAME', name='pool1')
# norm1
norm1 = tf.nn.lrn(pool1, 4, bias=1.0, alpha=0.001 / 9.0, beta=0.75,name='norm1')
#第二层卷积层
W_conv2 = weight_variable([5,5,64,64])
b_conv2 = bias_variable([64])
conv2 = tf.nn.relu(conv2d(norm1,W_conv2) + b_conv2)
# norm2
norm2 = tf.nn.lrn(conv2, 4, bias=1.0, alpha=0.001 / 9.0, beta=0.75,name='norm2')
# pool2
pool2 = tf.nn.max_pool(norm2, ksize=[1, 3, 3, 1],strides=[1, 2, 2, 1], padding='SAME', name='pool2')
#全连接层
#权值参数
W_fc1 = weight_variable([8*8*64,384])
#偏置值
b_fc1 = bias_variable([384])
#将卷积的产出展开
pool2_flat = tf.reshape(pool2,[-1,8*8*64])
#神经网络计算,并添加relu激活函数
fc1 = tf.nn.relu(tf.matmul(pool2_flat,W_fc1) + b_fc1)
#全连接第二层
#权值参数
W_fc2 = weight_variable([384,192])
#偏置值
b_fc2 = bias_variable([192])
#神经网络计算,并添加relu激活函数
fc2 = tf.nn.relu(tf.matmul(fc1,W_fc2) + b_fc2)
#输出层,使用softmax进行多分类
W_fc2 = weight_variable([192,10])
b_fc2 = bias_variable([10])
y_conv=tf.maximum(tf.nn.softmax(tf.matmul(fc2, W_fc2) + b_fc2),1e-30)
#
saver = tf.train.Saver()
saver.restore(sess , 'model_data/model.ckpt')
#input
im = Image.open('images/dog8.jpg')
im.show()
im = im.resize((32,32))
# r , g , b = im.split()
# im = Image.merge("RGB" , (r,g,b))
print im.size , im.mode
im = np.array(im).astype(np.float32)
im = np.reshape(im , [-1,32*32*3])
im = (im - (255 / 2.0)) / 255
batch_xs = np.reshape(im , [-1,32,32,3])
#print batch_xs
#获取cifar10数据
# cifar10_data_set = extract_cifar10.Cifar10DataSet('../../data/')
# batch_xs, batch_ys = cifar10_data_set.next_train_batch(1)
# print batch_ys
output = sess.run(y_conv , feed_dict={x:batch_xs})
print output
print 'the out put is :' , np.argmax(output)
#关闭会话
sess.close()
if __name__ == '__main__':
main()
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
您可能感兴趣的文章:
- Python用imghdr模块识别图片格式实例解析
相关推荐
-
Python用imghdr模块识别图片格式实例解析
imghdr模块 功能描述:imghdr模块用于识别图片的格式.它通过检测文件的前几个字节,从而判断图片的格式. 唯一一个API imghdr.what(file, h=None) 第一个参数file可以是用rb模式打开的file对象或者表示路径的字符串和PathLike对象.h参数是一段字节串.函数返回表示图片格式的字符串. >>> import imghdr >>> imghdr.what('test.jpg') 'jpeg' 具体的返回值和描述如下: 返回值 描述
-
python tensorflow学习之识别单张图片的实现的示例
假设我们已经安装好了tensorflow. 一般在安装好tensorflow后,都会跑它的demo,而最常见的demo就是手写数字识别的demo,也就是mnist数据集. 然而我们仅仅是跑了它的demo而已,可能很多人会有和我一样的想法,如果拿来一张数字图片,如何应用我们训练的网络模型来识别出来,下面我们就以mnist的demo来实现它. 1.训练模型 首先我们要训练好模型,并且把模型model.ckpt保存到指定文件夹 saver = tf.train.Saver() saver.save(s
-
python入门学习之自带help功能初步使用示例
目录 python help使用 modules keywords symbols python help使用 C:\Users\wusong>python Python 3.8.2rc1 (tags/v3.8.2rc1:8623e68, Feb 11 2020, 10:46:21) [MSC v.1916 64 bit (AMD64)] on win32 Type "help", "copyright", "credits" or &qu
-
Tensorflow模型实现预测或识别单张图片
利用Tensorflow训练好的模型,图片进行预测和识别,并输出相应的标签和预测概率. 如果想要多张图片,可以进行批次加载和预测,这里仅用单张图片进行演示. 模型文件: 预测图片: 这里直接贴代码,都有注释,应该很好理解 import tensorflow as tf import inference image_size = 128 # 输入层图片大小 # 模型保存的路径和文件名 MODEL_SAVE_PATH = "model/" MODEL_NAME = "model.
-

Python实现获取本地及远程图片大小的方法示例
本文实例讲述了Python实现获取本地及远程图片大小的方法.分享给大家供大家参考,具体如下: 了解过Pillow的都知道,Pillow是一个非常强大的图片处理器,这篇文章主要记录一下Pillow对图片信息的获取: 安装Pillow pip install pillow 本地图片 # -*- coding:utf-8 -*- #! python2 import os from PIL import Image path = os.path.join(os.getcwd(),"23.png"
-
Python深度学习实战PyQt5窗口切换的堆叠布局示例详解
目录 1. 堆叠布局简介 1. 1什么是堆叠布局(Stacked Layout) 1.2 堆叠布局的实现方法 2. 创建多窗口切换的堆叠布局 3. 堆叠布局的主程序设计 3.1 QStackedWidget 类 3.2 建立信号/槽连接 3.3 页面控制程序 3.4 堆叠布局中的控件操作 软件项目中经常需要多种不同的图形界面,以适应不同的任务场景.选项卡控件(QTackedWidget)通过标签选择打开对应的对话框页面,不需要另外编程.堆叠窗口控件(QStackedWidget)在主程序中通过编
-
Python深度学习实战PyQt5布局管理项目示例详解
目录 1. 从绝对定位到布局管理 1.1 什么是布局管理 1.2 Qt 中的布局管理方法 2. 水平布局(Horizontal Layout) 3. 垂直布局(Vertical Layout) 4. 栅格布局(Grid Layout) 5. 表格布局(Form Layout) 6. 嵌套布局 7. 容器布局 布局管理就是管理图形窗口中各个部件的位置和排列.图形窗口中的大量部件也需要通过布局管理,对部件进行整理分组.排列定位,才能使界面整齐有序.美观大方. 1. 从绝对定位到布局管理 1.1 什么
-
详解如何用TensorFlow训练和识别/分类自定义图片
很多正在入门或刚入门TensorFlow机器学习的同学希望能够通过自己指定图片源对模型进行训练,然后识别和分类自己指定的图片.但是,在TensorFlow官方入门教程中,并无明确给出如何把自定义数据输入训练模型的方法.现在,我们就参考官方入门课程<Deep MNIST for Experts>一节的内容(传送门:https://www.tensorflow.org/get_started/mnist/pros),介绍如何将自定义图片输入到TensorFlow的训练模型. 在<Deep M
-
python深度学习tensorflow实例数据下载与读取
目录 一.mnist数据 二.CSV数据 三.cifar10数据 一.mnist数据 深度学习的入门实例,一般就是mnist手写数字分类识别,因此我们应该先下载这个数据集. tensorflow提供一个input_data.py文件,专门用于下载mnist数据,我们直接调用就可以了,代码如下: import tensorflow.examples.tutorials.mnist.input_data mnist = input_data.read_data_sets("MNIST_data/&q
-
python深度学习tensorflow训练好的模型进行图像分类
目录 正文 随机找一张图片 读取图片进行分类识别 最后输出 正文 谷歌在大型图像数据库ImageNet上训练好了一个Inception-v3模型,这个模型我们可以直接用来进来图像分类. 下载链接: https://pan.baidu.com/s/1XGfwYer5pIEDkpM3nM6o2A 提取码: hu66 下载完解压后,得到几个文件: 其中 classify_image_graph_def.pb 文件就是训练好的Inception-v3模型. imagenet_synset_to_huma
-
Python tensorflow实现mnist手写数字识别示例【非卷积与卷积实现】
本文实例讲述了Python tensorflow实现mnist手写数字识别.分享给大家供大家参考,具体如下: 非卷积实现 import tensorflow as tf from tensorflow.examples.tutorials.mnist import input_data data_path = 'F:\CNN\data\mnist' mnist_data = input_data.read_data_sets(data_path,one_hot=True) #offline da