Spring Cloud Hystrix 线程池队列配置(踩坑)
背景:
有一次在生产环境,突然出现了很多笔还款单被挂起,后来排查原因,发现是内部系统调用时出现了Hystrix调用异常。在开发过程中,因为核心线程数设置的比较大,没有出现这种异常。放到了测试环境,偶尔有出现这种情况,后来在网上查找解决方案,网上的方案是调整maxQueueSize属性就好了,当时调整了一下,确实有所改善。可没想到在生产环境跑了一段时间后却又出现这种了情况,此时我第一想法就是去查看maxQueueSize属性,可是maxQueueSize属性是设置值了。当时就比较纳闷了,为什么maxQueueSize属性不起作用,后来通过查看官方文档发现Hystrix还有一个queueSizeRejectionThreshold属性,这个属性是控制队列最大阈值的,而Hystrix默认只配置了5个,因此就算我们把maxQueueSize的值设置再大,也是不起作用的。两个属性必须同时配置
先看一下正确的Hystrix配置姿势。
application.yml:
hystrix: threadpool: default: coreSize: 200 #并发执行的最大线程数,默认10 maxQueueSize: 1000 #BlockingQueue的最大队列数,默认值-1 queueSizeRejectionThreshold: 800 #即使maxQueueSize没有达到,达到queueSizeRejectionThreshold该值后,请求也会被拒绝,默认值5
接下来编写一个测试类,来验证几种错误配置,看看会出现什么情况。
测试类代码(A调用方):
/**
* @Author: XiongFeng
* @Description:
* @Date: Created in 11:12 2018/6/11
*/
public class RepaymentHelperTest extends FundApplicationTests {
@Autowired
RepaymentHelper repaymentHelper;
@Autowired
private RouterFeign routerFeign;
@Test
public void hystrixTest() throws InterruptedException {
for (int i = 0; i < 135; i++) {
new Thread(new Runnable() {
@Override
public void run() {
job();
}
}).start();
}
Thread.currentThread().join();
}
public void job() {
String repaymentNo = "xf1002";
String transNo = "T4324324234";
String reqNo = "xf1002";
String begintime = "20180831130030";
String endtime = "20180831130050";
TransRecQueryReqDto transRecQueryReqDto = new TransRecQueryReqDto();
transRecQueryReqDto.setTransNo(transNo);
transRecQueryReqDto.setBeginTime(begintime);
transRecQueryReqDto.setEndTime(endtime);
transRecQueryReqDto.setReqNo(reqNo);
Resp<List<TransRecDto>> queryTransRecListResp = routerFeign.queryTransRec(new Req<>(repaymentNo, "2018080200000002", null, null, transRecQueryReqDto));
System.out.println(String.format("获取结果为:【%s】", JsonUtil.toJson(queryTransRecListResp)));
}
}
这个测试类的作用就是创建135个线程,通过RouterFeign类并发请求B服务方,看看请求结果是否出现异常。
Feign调用代码:
@FeignClient(value = "${core.name}", fallbackFactory = RouterFeignBackFactory.class, path = "/router")
public interface RouterFeign {
/**
* 代扣结果查询
* @param transRecQueryReqDtoReq
* @return
*/
@PostMapping("/queryTransRec")
Resp<List<TransRecDto>> queryTransRec(@RequestBody Req<TransRecQueryReqDto> transRecQueryReqDtoReq);
}
这个类,就是通过Feign方式去调用B服务方的客户端
服务提供方代码(B服务方):
/**
* @Author: XiongFeng
* @Description:
* @Date: Created in 16:04 2018/5/24
*/
@Api("还款服务")
@RefreshScope
@RestController
@RequestMapping("/router")
public class TestController {
private static Logger logger = LoggerFactory.getLogger(TestController.class);
// 计数器
private static AtomicInteger count = new AtomicInteger(1);
@ApiOperation(value = "代扣结果查询")
@PostMapping("/queryTransRec")
Resp<List<TransRecDto>> queryTransRec(@RequestBody Req<TransRecQueryReqDto> transRecQueryReqDtoReq) throws InterruptedException {
System.out.println(String.format("查询支付结果......计数: %s", count.getAndAdd(1)));
Thread.sleep(500);
return Resp.success(RespStatus.SUCCESS.getDesc(), null);
}
这个类的作用,就是一个服务提供方,计数并返回结果。
下面我们看一下几种错误的配置。
案例一(将核心线程数调低,最大队列数调大一点,但是队列拒绝阈值设置小一点):
hystrix: threadpool: default: coreSize: 10 maxQueueSize: 1000 queueSizeRejectionThreshold: 20
此时的结果:
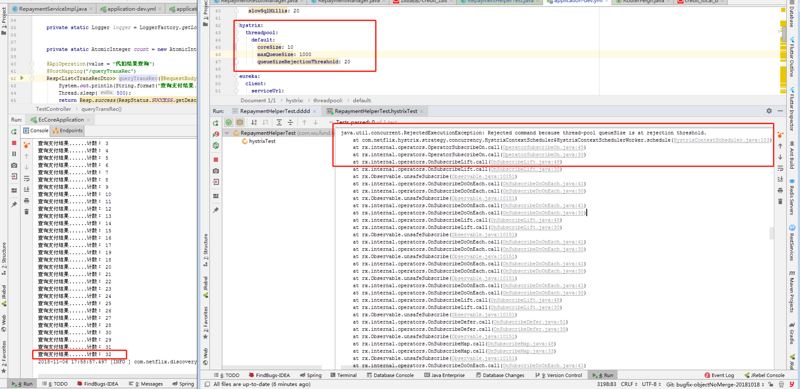
左窗口是B服务方,右窗口是A调用方。从结果可以看出,调用135次,成功32次左右,其余线程全部抛异常。
案例二(将核心线程数调低,最大队列数调小一点,但是队列拒绝阈值设置大一点):
hystrix: threadpool: default: coreSize: 10 maxQueueSize: 15 queueSizeRejectionThreshold: 2000
此时的结果:
java.util.concurrent.RejectedExecutionException: Task java.util.concurrent.FutureTask@7d6d472b rejected from java.util.concurrent.ThreadPoolExecutor@17f8bcb7[Running, pool size = 3, active threads = 3, queued tasks = 15, completed tasks = 0]

左窗口是B服务方,右窗口是A调用方。从结果可以看出,调用135次,成功25次左右,其余线程全部抛异常。。
案例三(将核心线程数调低,最大队列数调大一点,但是队列拒绝阈值不设置值):
hystrix: threadpool: default: coreSize: 10 maxQueueSize: 1500
此时的结果:
java.util.concurrent.RejectedExecutionException: Rejected command because thread-pool queueSize is at rejection threshold.

左窗口是B服务方,右窗口是A调用方。此时的结果和案例一的情况一样,调用135次,成功47次左右,其余线程全部抛异常。报错跟案例一一样
案例四(将核心线程数调低,最大队列数不设值,但是队列拒绝阈值设置的比较大):
hystrix: threadpool: default: coreSize: 10 queueSizeRejectionThreshold: 1000
此时的结果:
java.util.concurrent.RejectedExecutionException: Task java.util.concurrent.FutureTask@23d268ea rejected from java.util.concurrent.ThreadPoolExecutor@66d0e2f4[Running, pool size = 0, active threads = 0, queued tasks = 0, completed tasks = 0]
at java.util.concurrent.ThreadPoolExecutor$AbortPolicy.rejectedExecution(ThreadPoolExecutor.java:2063)
at java.util.concurrent.ThreadPoolExecutor.reject(ThreadPoolExecutor.java:830)
at java.util.concurrent.ThreadPoolExecutor.execute(ThreadPoolExecutor.java:1379)
at java.util.concurrent.AbstractExecutorService.submit(AbstractExecutorService.java:112)

左窗口是B服务方,右窗口是A调用方。此时的结果和案例二的情况一样,调用135次,成功10次左右,其余线程全部抛异常。报错跟案例二一样
下面来看一看正确的配置案例
案例一:将核心线程数调低,最大队列数和队列拒绝阈值的值都设置大一点):
hystrix: threadpool: default: coreSize: 10 maxQueueSize: 1500 queueSizeRejectionThreshold: 1000
此时的结果:
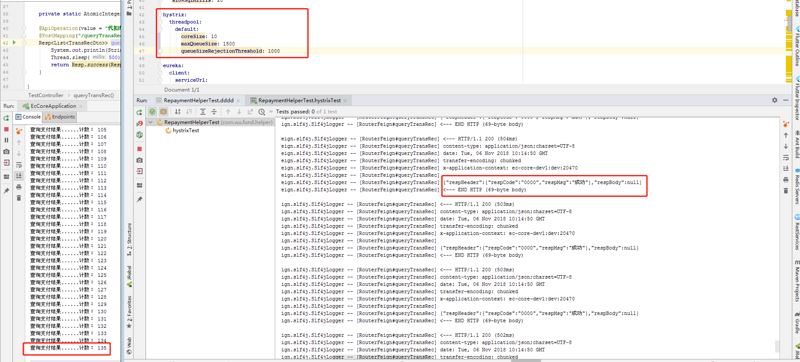
左窗口是B服务方,右窗口是A调用方。此时的结果就完全正常了,并发请求了135次,全部成功!
结论:官方默认队列阈值只有5个, 如果要调整队列,必须同时修改maxQueueSize和queueSizeRejectionThreshold属性的值,否则都会出现异常!参考文档:
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-

详解Spring Cloud中Hystrix的请求合并
在微服务架构中,我们将一个项目拆分成很多个独立的模块,这些独立的模块通过远程调用来互相配合工作,但是,在高并发情况下,通信次数的增加会导致总的通信时间增加,同时,线程池的资源也是有限的,高并发环境会导致有大量的线程处于等待状态,进而导致响应延迟,为了解决这些问题,我们需要来了解Hystrix的请求合并. Hystrix中的请求合并,就是利用一个合并处理器,将对同一个服务发起的连续请求合并成一个请求进行处理(这些连续请求的时间窗默认为10ms),在这个过程中涉及到的一个核心类就是HystrixCo
-
详解Spring Cloud Hystrix断路器实现容错和降级
简介 Spring cloud提供了Hystrix容错库用以在服务不可用时,对配置了断路器的方法实行降级策略,临时调用备用方法.这篇文章将创建一个产品微服务,注册到eureka服务注册中心,然后我们使用web客户端访问/products API来获取产品列表,当产品服务故障时,则调用本地备用方法,以降级但正常提供服务. 基础环境 JDK 1.8 Maven 3.3.9 IntelliJ 2018.1 Git:项目源码 添加产品服务 在intelliJ中创建一个新的maven项目,使用如下配置 g
-
spring cloud Hystrix断路器的使用(熔断器)
1.Hystrix客户端 Netflix已经创建了一个名为Hystrix的库,实现了断路器的模式.在microservice架构通常有多个层的服务调用. 低水平的服务的服务失败会导致级联故障一直给到用户.当调用一个特定的服务达到一定阈值(默认5秒失败20次),打开断路器.在错误的情况下和一个开启的断路回滚应可以由开发人员提供. 有一个断路器阻止级联失败并且允许关闭服务一段时间进行愈合.回滚会被其他hystrix保护调用,静态数据或健全的空值. 代码如下: @SpringBootApplicati
-
详解SpringCloud微服务架构之Hystrix断路器
一:什么是Hystrix 在分布式环境中,许多服务依赖项中的一些将不可避免地失败.Hystrix是一个库,通过添加延迟容差和容错逻辑来帮助您控制这些分布式服务之间的交互.Hystrix通过隔离服务之间的访问点,停止其间的级联故障以及提供回退选项,从而提高系统的整体弹性. Hystrix旨在执行以下操作 1:对通过第三方客户端库访问(通常通过网络)的依赖关系提供保护并控制延迟和故障. 2:隔离复杂分布式系统中的级联故障. 3:快速发现故障,尽快恢复. 4:回退,尽可能优雅地降级. 5:启用近实时监
-
Spring Cloud Hystrix入门和Hystrix命令原理分析
断路由器模式 在分布式架构中,当某个服务单元发生故障之后,通过断路由器的故障监控(类似熔断保险丝),向调用方返回一个错误响应,而不是长时间的等待.这样就不会使得线程因调用故障服务被长时间占用不释放,避免了故障在分布式系统中的蔓延. Spring Cloud Hystrix针对上述问题实现了断路由器.线程隔离等一系列服务保护功能.它是基于Netflix Hystrix实现,该框架的目标在于通过控制那些访问远程系统.服务和第三方库的节点,从而对延迟和故障提供更强大的容错能力. Hystrix具备服务
-
详解springcloud Feign的Hystrix支持
本文介绍了springcloud Feign的Hystrix支持,分享给大家,具体如下: 一.Feign client中加入Hystrix的fallback @FeignClient(name="springboot-h2", fallback=HystrixClientFallback.class) //在fallback属性中指定断路器的fallback public interface UserFeignClient { // @GetMapping("/user/{i
-
详解spring cloud hystrix缓存功能的使用
hystrix缓存的作用是 - 1.减少重复的请求数,降低依赖服务的返回数据始终保持一致. - 2.==在同一个用户请求的上下文中,相同依赖服务的返回数据始终保持一致==. - 3.请求缓存在run()和construct()执行之前生效,所以可以有效减少不必要的线程开销. 1 通过HystrixCommand类实现 1.1 开启缓存功能 继承HystrixCommand或HystrixObservableCommand,覆盖getCacheKey()方法,指定缓存的key,开启缓存配置. im
-
详解spring cloud使用Hystrix实现单个方法的fallback
本文介绍了spring cloud-使用Hystrix实现单个方法的fallback,分享给大家,具体如下: 一.加入Hystrix依赖 <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-hystrix</artifactId> </dependency> 二.编写Controller package c
-
springcloud 熔断器Hystrix的具体使用
说起springcloud熔断让我想起了去年股市中的熔断,多次痛的领悟,随意实施的熔断对整个系统的影响是灾难性的,好了接下来我们还是说正事. 熔断器 雪崩效应 在微服务架构中通常会有多个服务层调用,基础服务的故障可能会导致级联故障,进而造成整个系统不可用的情况,这种现象被称为服务雪崩效应.服务雪崩效应是一种因"服务提供者"的不可用导致"服务消费者"的不可用,并将不可用逐渐放大的过程. 如果下图所示:A作为服务提供者,B为A的服务消费者,C和D是B的服务消费者.A不可
-
Spring Cloud Hystrix 线程池队列配置(踩坑)
背景: 有一次在生产环境,突然出现了很多笔还款单被挂起,后来排查原因,发现是内部系统调用时出现了Hystrix调用异常.在开发过程中,因为核心线程数设置的比较大,没有出现这种异常.放到了测试环境,偶尔有出现这种情况,后来在网上查找解决方案,网上的方案是调整maxQueueSize属性就好了,当时调整了一下,确实有所改善.可没想到在生产环境跑了一段时间后却又出现这种了情况,此时我第一想法就是去查看maxQueueSize属性,可是maxQueueSize属性是设置值了.当时就比较纳闷了,为什么ma
-
Spring Cloud Hystrix线程池不足的解决方法
现象: 昨天突然线上很多接口获取失败,通过 kibana发现大量异常,具体异常信息: ...into fallback. Rejected command because thread-pool queueSize is at rejection threshold. 异常代码出处: @FeignClient(name = "api", fallbackFactory = LoadBalancingFallbackFactory.class) public interface Load
-
Spring线程池ThreadPoolTaskExecutor配置详情
本文介绍了Spring线程池ThreadPoolTaskExecutor配置,分享给大家,具体如下: 1. ThreadPoolTaskExecutor配置 <!-- spring thread pool executor --> <bean id="taskExecutor" class="org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor"> <!-- 线
-
基于Spring Boot的线程池监控问题及解决方案
目录 前言 为什么需要对线程池进行监控 如何做线程池的监控 数据采集 数据存储以及大盘的展示 进一步扩展以及思考 如何合理配置线程池参数 如何动态调整线程池参数 如何给不同的服务之间做线程池的隔离 实现方案 前言 这篇是推动大家异步编程的思想的线程池的准备篇,要做好监控,让大家使用无后顾之忧,敬畏生产. 为什么需要对线程池进行监控 Java线程池作为最常使用到的并发工具,相信大家都不陌生,但是你真的确定使用对了吗?大名鼎鼎的阿里Java代码规范要求我们不使用 Executors来快速创建线程池,
-
Spring Cloud Hystrix 服务容错保护的原理实现
一.Hystrix 是什么 在微服务架构中,我们将系统拆分成了若干弱小的单元,单元与单元之间通过HTTP或者TCP等方式相互访问,各单元的应用间通过服务注册与订阅的方式相互依赖.由于每个单元都在不同的进程中运行,依赖 远程调用 的方式执行,这样就可能引起因为网速变慢或者网络故障导致请求变慢或超时,若此时调用方的请求在不断增加,最后就会因等待出现故障的依赖方响应形成任务积压,最终导致自身服务的瘫痪. Hystrix 是Netflix 中的一个组件库,它隔离了服务之间的访问点,阻止了故障节点
-
Spring Cloud Hystrix的基本用法大全
目录 1. Hystrix的简单使用 1.1 服务降级 1.2 服务熔断 2. OpenFeign集成Hystrix 3. Hystrix熔断原理 3.1 熔断状态 3.2 熔断的工作原理 4. 代码地址 本文主要讲述Hystrix,也可以称之为豪猪哥. 它是Spring Cloud中集成的一个组件,在整个生态中主要为我们提供以下功能: 服务隔离 服务隔离主要包括线程池隔离以及信号量隔离. 服务熔断 当请求持续失败的时候,服务进行熔断,默认熔断5S,也是就说在这5S内的请求一律拒绝. 服务降级
-
Spring Boot使用Spring的异步线程池的实现
前言 线程池,从名字上来看,就是一个保存线程的"池子",凡事都有其道理,那线程池的好处在哪里呢? 我们要让计算机为我们干一些活,其实都是在使用线程,使用方法就是new一个Runnable接口或者新建一个子类,继承于Thread类,这就会涉及到线程对象的创建与销毁,这两个操作无疑是耗费我们系统处理器资源的,那如何解决这个问题呢? 线程池其实就是为了解决这个问题而生的. 线程池提供了处理系统性能和大用户量请求之间的矛盾的方法,通过对多个任务重用已经存在的线程对象,降低了对线程对象创建和销毁
-
对spring task和线程池的深入研究
目录 spring task和线程池的研究 1.如何实现spring task定时任务的配置 2.task里面的一个job方法如何使用多线程,配置线程池 spring 线程池配置 默认线程池ThreadPoolTaskExecutor配置 自定义线程池ThreadPoolTaskExecutor配置 spring task和线程池的研究 最近因工作需求,研究了一下spring task定时任务,和线程池,有了一定收获,记录一下 涉及如下内容 1.如何实现spring task定时任务的配置 2.
-
Spring Boot使用线程池处理上万条数据插入功能
目录 # 前言 # 使用步骤 # 前言 前两天做项目的时候,想提高一下插入表的性能优化,因为是两张表,先插旧的表,紧接着插新的表,一万多条数据就有点慢了 后面就想到了线程池ThreadPoolExecutor,而用的是Spring Boot项目,可以用Spring提供的对ThreadPoolExecutor封装的线程池ThreadPoolTaskExecutor,直接使用注解启用 # 使用步骤 先创建一个线程池的配置,让Spring Boot加载,用来定义如何创建一个ThreadPoolTask