机器学习python实战之手写数字识别
看了上一篇内容之后,相信对K近邻算法有了一个清晰的认识,今天的内容——手写数字识别是对上一篇内容的延续,这里也是为了自己能更熟练的掌握k-NN算法。
我们有大约2000个训练样本和1000个左右测试样本,训练样本所在的文件夹是trainingDigits,测试样本所在的文件夹是testDigits。文本文件中是0~9的数字,但是是用二值图表示出来的,如图。我们要做的就是使用训练样本训练模型,并用测试样本来检测模型的性能。
首先,我们需要将文本文件中的内容转化为向量,因为图片大小是32*32,所以我们可以将其转化为1*1024的向量。具体代码实现如下:
def img2vector(filename):
imgVec = zeros((1,1024))
file = open(filename)
for i in range(32):
lines = file.readline()
for j in range(32):
imgVec[0,32*i+j] = lines[j]
return imgVec
实现了图片到向量的转化之后,我们就可以对测试文件中的内容进行识别了。这里的识别我们可以使用上一篇中的自定义函数classify0,这个函数的第一个参数是测试向量,第二个参数是训练数据集,第三个参数是训练集的标签。所以,我们首先需要将训练数据集转化为(1934*1024)的矩阵,1934这里是训练集的组数即trainingDigits目录下的文件数,其对应的标签转化为(1*1934)的向量。之后要编写的代码就是对测试数据集中的每个文本文件进行识别,也就是需要将每个文件都转化成一个(1*1024)的向量,再传入classify0函数的第一个形参。整体代码如下:
def handWriteNumClassTest():
NumLabels = []
TrainingDirfile = listdir(r'D:\ipython\num_recognize\trainingDigits')#文件目录
L = len(TrainingDirfile) #该目录中有多少文件
TrainMat = zeros((L,1024))
for i in range(L):
file_n = TrainingDirfile[i]
fileName = file_n.split('.')[0]
ClassName = int(file_n.split('_')[0])
NumLabels.append(ClassName)
TrainMat[i,:] = img2vector(r'D:\ipython\num_recognize\trainingDigits\%s'%file_n)
TestfileDir = listdir(r'D:\ipython\num_recognize\testDigits')
error_cnt = 0.0
M = len(TestfileDir)
for j in range(M):
Testfile = TestfileDir[j]
TestfileName = Testfile.split('.')[0]
TestClassName = int(Testfile.split('_')[0])
TestVector = img2vector(r'D:\ipython\num_recognize\testDigits\%s'%Testfile)
result = classify0(TestVector,TrainMat,NumLabels,3)
print('the result is %d,the real answer is %d\n'%(result,TestClassName))
if result!=TestClassName:
error_cnt+=1
print('the total num of errors is %f\n'%error_cnt)
print('the error rate is %f\n'%(error_cnt/float(M)))
这里需要首先导入listdir方法,from os import listdir,它可以列出给定目录的文件名。对于测试的每个文件,如果识别的分类结果跟真实结果不一样,则错误数+1,最终用错误数/测试总数 来表示该模型的性能。下面给出结果
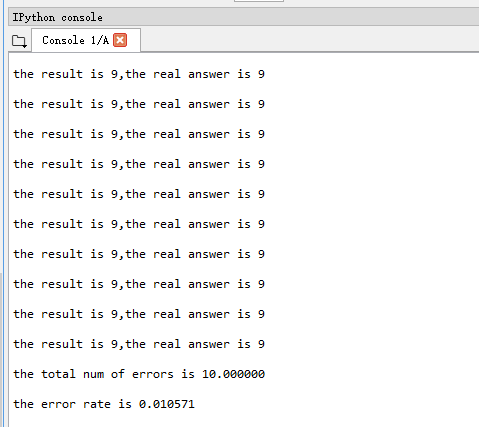
这里测试的总共946个项目中,一共有10个出现了错误,出错率为1%,这个性能还是可以接受的。有了上一篇内容的理解,这篇就简单多了吧!
训练数据集和测试集文件下载
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
python下调用pytesseract识别某网站验证码的实现方法
一.pytesseract介绍 1.pytesseract说明 pytesseract最新版本0.1.6,网址:https://pypi.python.org/pypi/pytesseract Python-tesseract is a wrapper for google's Tesseract-OCR ( http://code.google.com/p/tesseract-ocr/ ). It is also useful as a stand-alone invocation scrip
-

Python验证码识别处理实例
一.准备工作与代码实例 (1)安装PIL:下载后是一个exe,直接双击安装,它会自动安装到C:\Python27\Lib\site-packages中去, (2)pytesser:下载解压后直接放C:\Python27\Lib\site-packages(根据你安装的Python路径而不同),同时,新建一个pytheeer.pth,内容就写pytesser,注意这里的内容一定要和pytesser这个文件夹同名,意思就是pytesser文件夹,pytesser.pth,及内容都要一样! (3)Te
-
kNN算法python实现和简单数字识别的方法
本文实例讲述了kNN算法python实现和简单数字识别的方法.分享给大家供大家参考.具体如下: kNN算法算法优缺点: 优点:精度高.对异常值不敏感.无输入数据假定 缺点:时间复杂度和空间复杂度都很高 适用数据范围:数值型和标称型 算法的思路: KNN算法(全称K最近邻算法),算法的思想很简单,简单的说就是物以类聚,也就是说我们从一堆已知的训练集中找出k个与目标最靠近的,然后看他们中最多的分类是哪个,就以这个为依据分类. 函数解析: 库函数: tile() 如tile(A,n)就是将A重复n次
-
Python验证码识别的方法
本文实例讲述了Python验证码识别的方法.分享给大家供大家参考.具体实现方法如下: #encoding=utf-8 import Image,ImageEnhance,ImageFilter import sys image_name = "./22.jpeg" #去处 干扰点 im = Image.open(image_name) im = im.filter(ImageFilter.MedianFilter()) enhancer = ImageEnhance.Contrast(
-
详解Python验证码识别
以前写过一个刷校内网的人气的工具,Java的(以后再也不行Java程序了),里面用到了验证码识别,那段代码不是我自己写的:-) 校内的验证是完全单色没有任何干挠的验证码,识别起来比较容易,不过从那段代码中可以看到基本的验证码识别方式.这几天在写一个程序的时候需要识别验证码,因为程序是Python写的自然打算用Python进行验证码的识别. 以前没用Python处理过图像,不太了解PIL(Python Image Library)的用法,这几天看了看PIL,发现它太强大了,简直和ImageMagi
-
python验证码识别的实例详解
其实关于验证码识别涉及很多方面的内容,入手难度大,但是入手后,可拓展性又非常广泛,可玩性极强,成就感也很足,对这感兴趣的朋友们下面跟着小编一起来学习学习吧. 依赖 sudo apt-get install python-imaging sudo apt-get install tesseract-ocr pip install pytesseract 利用google ocr来识别验证码 from PIL import Image import pytesseract image = Image
-
Python+Opencv识别两张相似图片
在网上看到python做图像识别的相关文章后,真心感觉python的功能实在太强大,因此将这些文章总结一下,建立一下自己的知识体系. 当然了,图像识别这个话题作为计算机科学的一个分支,不可能就在本文简单几句就说清,所以本文只作基本算法的科普向. 看到一篇博客是介绍这个,但他用的是PIL中的Image实现的,感觉比较麻烦,于是利用Opencv库进行了更简洁化的实现. 相关背景 要识别两张相似图像,我们从感性上来谈是怎么样的一个过程?首先我们会区分这两张相片的类型,例如是风景照,还是人物照.风景照中
-
Python 40行代码实现人脸识别功能
前言 很多人都认为人脸识别是一项非常难以实现的工作,看到名字就害怕,然后心怀忐忑到网上一搜,看到网上N页的教程立马就放弃了.这些人里包括曾经的我自己.其实如果如果你不是非要深究其中的原理,只是要实现这一工作的话,人脸识别也没那么难.今天我们就来看看如何在40行代码以内简单地实现人脸识别. 一点区分 对于大部分人来说,区分人脸检测和人脸识别完全不是问题.但是网上有很多教程有无无意地把人脸检测说成是人脸识别,误导群众,造成一些人认为二者是相同的.其实,人脸检测解决的问题是确定一张图上有木有人脸,而人
-
python实现识别相似图片小结
文章简介 在网上看到python做图像识别的相关文章后,真心感觉python的功能实在太强大,因此将这些文章总结一下,建立一下自己的知识体系. 当然了,图像识别这个话题作为计算机科学的一个分支,不可能就在本文简单几句就说清,所以本文只作基本算法的科普向. 如有错误,请多包涵和多多指教. 参考的文章和图片来源会在底部一一列出. 以及本篇文章所用的代码都会在底下给出github地址. 安装相关库 python用作图像处理的相关库主要有openCV(C++编写,提供了python语言的接口),PIL,
-
Python中利用Scipy包的SIFT方法进行图片识别的实例教程
scipy scipy包包含致力于科学计算中常见问题的各个工具箱.它的不同子模块相应于不同的应用.像插值,积分,优化,图像处理,,特殊函数等等. scipy可以与其它标准科学计算程序库进行比较,比如GSL(GNU C或C++科学计算库),或者Matlab工具箱.scipy是Python中科学计算程序的核心包;它用于有效地计算numpy矩阵,来让numpy和scipy协同工作. 在实现一个程序之前,值得检查下所需的数据处理方式是否已经在scipy中存在了.作为非专业程序员,科学家总是喜欢重新发明造