Python决策树分类算法学习
从这一章开始进入正式的算法学习。
首先我们学习经典而有效的分类算法:决策树分类算法。
1、决策树算法
决策树用树形结构对样本的属性进行分类,是最直观的分类算法,而且也可以用于回归。不过对于一些特殊的逻辑分类会有困难。典型的如异或(XOR)逻辑,决策树并不擅长解决此类问题。
决策树的构建不是唯一的,遗憾的是最优决策树的构建属于NP问题。因此如何构建一棵好的决策树是研究的重点。
J. Ross Quinlan在1975提出将信息熵的概念引入决策树的构建,这就是鼎鼎大名的ID3算法。后续的C4.5, C5.0, CART等都是该方法的改进。
熵就是“无序,混乱”的程度。刚接触这个概念可能会有些迷惑。想快速了解如何用信息熵增益划分属性,可以参考这位兄弟的文章:Python机器学习之决策树算法
如果还不理解,请看下面这个例子。
假设要构建这么一个自动选好苹果的决策树,简单起见,我只让他学习下面这4个样本:
样本 红 大 好苹果
0 1 1 1
1 1 0 1
2 0 1 0
3 0 0 0
样本中有2个属性,A0表示是否红苹果。A1表示是否大苹果。
那么这个样本在分类前的信息熵就是S = -(1/2 * log(1/2) + 1/2 * log(1/2)) = 1。
信息熵为1表示当前处于最混乱,最无序的状态。
本例仅2个属性。那么很自然一共就只可能有2棵决策树,如下图所示:
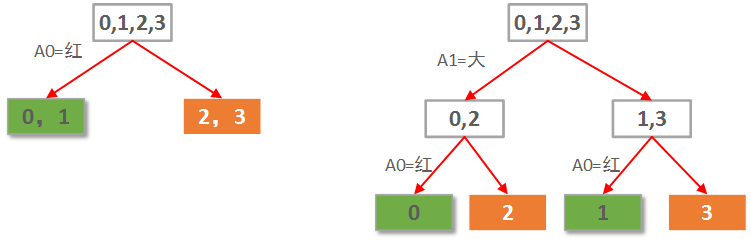
显然左边先使用A0(红色)做划分依据的决策树要优于右边用A1(大小)做划分依据的决策树。
当然这是直觉的认知。定量的考察,则需要计算每种划分情况的信息熵增益。
先选A0作划分,各子节点信息熵计算如下:
0,1叶子节点有2个正例,0个负例。信息熵为:e1 = -(2/2 * log(2/2) + 0/2 * log(0/2)) = 0。
2,3叶子节点有0个正例,2个负例。信息熵为:e2 = -(0/2 * log(0/2) + 2/2 * log(2/2)) = 0。
因此选择A0划分后的信息熵为每个子节点的信息熵所占比重的加权和:E = e1*2/4 + e2*2/4 = 0。
选择A0做划分的信息熵增益G(S, A0)=S - E = 1 - 0 = 1.
事实上,决策树叶子节点表示已经都属于相同类别,因此信息熵一定为0。
同样的,如果先选A1作划分,各子节点信息熵计算如下:
0,2子节点有1个正例,1个负例。信息熵为:e1 = -(1/2 * log(1/2) + 1/2 * log(1/2)) = 1。
1,3子节点有1个正例,1个负例。信息熵为:e2 = -(1/2 * log(1/2) + 1/2 * log(1/2)) = 1。
因此选择A1划分后的信息熵为每个子节点的信息熵所占比重的加权和:E = e1*2/4 + e2*2/4 = 1。也就是说分了跟没分一样!
选择A1做划分的信息熵增益G(S, A1)=S - E = 1 - 1 = 0.
因此,每次划分之前,我们只需要计算出信息熵增益最大的那种划分即可。
2、数据集
为方便讲解与理解,我们使用如下一个极其简单的测试数据集:
1.5 50 thin
1.5 60 fat
1.6 40 thin
1.6 60 fat
1.7 60 thin
1.7 80 fat
1.8 60 thin
1.8 90 fat
1.9 70 thin
1.9 80 fat
这个数据一共有10个样本,每个样本有2个属性,分别为身高和体重,第三列为类别标签,表示“胖”或“瘦”。该数据保存在1.txt中。
我们的任务就是训练一个决策树分类器,输入身高和体重,分类器能给出这个人是胖子还是瘦子。
(数据是作者主观臆断,具有一定逻辑性,但请无视其合理性)
决策树对于“是非”的二值逻辑的分枝相当自然。而在本数据集中,身高与体重是连续值怎么办呢?
虽然麻烦一点,不过这也不是问题,只需要找到将这些连续值划分为不同区间的中间点,就转换成了二值逻辑问题。
本例决策树的任务是找到身高、体重中的一些临界值,按照大于或者小于这些临界值的逻辑将其样本两两分类,自顶向下构建决策树。
使用python的机器学习库,实现起来相当简单和优雅。
3、Python实现
Python代码实现如下:
# -*- coding: utf-8 -*-
import numpy as np
import scipy as sp
from sklearn import tree
from sklearn.metrics import precision_recall_curve
from sklearn.metrics import classification_report
from sklearn.cross_validation import train_test_split
''''' 数据读入 '''
data = []
labels = []
with open("data\\1.txt") as ifile:
for line in ifile:
tokens = line.strip().split(' ')
data.append([float(tk) for tk in tokens[:-1]])
labels.append(tokens[-1])
x = np.array(data)
labels = np.array(labels)
y = np.zeros(labels.shape)
''''' 标签转换为0/1 '''
y[labels=='fat']=1
''''' 拆分训练数据与测试数据 '''
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.2)
''''' 使用信息熵作为划分标准,对决策树进行训练 '''
clf = tree.DecisionTreeClassifier(criterion='entropy')
print(clf)
clf.fit(x_train, y_train)
''''' 把决策树结构写入文件 '''
with open("tree.dot", 'w') as f:
f = tree.export_graphviz(clf, out_file=f)
''''' 系数反映每个特征的影响力。越大表示该特征在分类中起到的作用越大 '''
print(clf.feature_importances_)
'''''测试结果的打印'''
answer = clf.predict(x_train)
print(x_train)
print(answer)
print(y_train)
print(np.mean( answer == y_train))
'''''准确率与召回率'''
precision, recall, thresholds = precision_recall_curve(y_train, clf.predict(x_train))
answer = clf.predict_proba(x)[:,1]
print(classification_report(y, answer, target_names = ['thin', 'fat']))
输出结果类似如下所示:
[ 0.2488562 0.7511438]
array([[ 1.6, 60. ],
[ 1.7, 60. ],
[ 1.9, 80. ],
[ 1.5, 50. ],
[ 1.6, 40. ],
[ 1.7, 80. ],
[ 1.8, 90. ],
[ 1.5, 60. ]])
array([ 1., 0., 1., 0., 0., 1., 1., 1.])
array([ 1., 0., 1., 0., 0., 1., 1., 1.])
1.0
precision recall f1-score support
thin 0.83 1.00 0.91 5
fat 1.00 0.80 0.89 5
avg / total 1.00 1.00 1.00 8
array([ 0., 1., 0., 1., 0., 1., 0., 1., 0., 0.])
array([ 0., 1., 0., 1., 0., 1., 0., 1., 0., 1.])
可以看到,对训练过的数据做测试,准确率是100%。但是最后将所有数据进行测试,会出现1个测试样本分类错误。
说明本例的决策树对训练集的规则吸收的很好,但是预测性稍微差点。
这里有3点需要说明,这在以后的机器学习中都会用到。
1、拆分训练数据与测试数据。
这样做是为了方便做交叉检验。交叉检验是为了充分测试分类器的稳定性。
代码中的0.2表示随机取20%的数据作为测试用。其余80%用于训练决策树。
也就是说10个样本中随机取8个训练。本文数据集小,这里的目的是可以看到由于取的训练数据随机,每次构建的决策树都不一样。
2、特征的不同影响因子。
样本的不同特征对分类的影响权重差异会很大。分类结束后看看每个样本对分类的影响度也是很重要的。
在本例中,身高的权重为0.25,体重为0.75,可以看到重量的重要性远远高于身高。对于胖瘦的判定而言,这也是相当符合逻辑的。
3、准确率与召回率。
这2个值是评判分类准确率的一个重要标准。比如代码的最后将所有10个样本输入分类器进行测试的结果:
测试结果:array([ 0., 1., 0., 1., 0., 1., 0., 1., 0., 0.])
真实结果:array([ 0., 1., 0., 1., 0., 1., 0., 1., 0., 1.])
分为thin的准确率为0.83。是因为分类器分出了6个thin,其中正确的有5个,因此分为thin的准确率为5/6=0.83。
分为thin的召回率为1.00。是因为数据集中共有5个thin,而分类器把他们都分对了(虽然把一个fat分成了thin!),召回率5/5=1。
分为fat的准确率为1.00。不再赘述。
分为fat的召回率为0.80。是因为数据集中共有5个fat,而分类器只分出了4个(把一个fat分成了thin!),召回率4/5=0.80。
很多时候,尤其是数据分类难度较大的情况,准确率与召回率往往是矛盾的。你可能需要根据你的需要找到最佳的一个平衡点。
比如本例中,你的目标是尽可能保证找出来的胖子是真胖子(准确率),还是保证尽可能找到更多的胖子(召回率)。
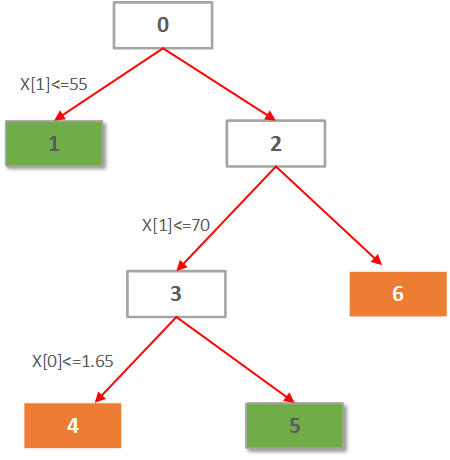
代码还把决策树的结构写入了tree.dot中。打开该文件,很容易画出决策树,还可以看到决策树的更多分类信息。
本文的tree.dot如下所示:
digraph Tree {
0 [label="X[1] <= 55.0000\nentropy = 0.954434002925\nsamples = 8", shape="box"] ;
1 [label="entropy = 0.0000\nsamples = 2\nvalue = [ 2. 0.]", shape="box"] ;
0 -> 1 ;
2 [label="X[1] <= 70.0000\nentropy = 0.650022421648\nsamples = 6", shape="box"] ;
0 -> 2 ;
3 [label="X[0] <= 1.6500\nentropy = 0.918295834054\nsamples = 3", shape="box"] ;
2 -> 3 ;
4 [label="entropy = 0.0000\nsamples = 2\nvalue = [ 0. 2.]", shape="box"] ;
3 -> 4 ;
5 [label="entropy = 0.0000\nsamples = 1\nvalue = [ 1. 0.]", shape="box"] ;
3 -> 5 ;
6 [label="entropy = 0.0000\nsamples = 3\nvalue = [ 0. 3.]", shape="box"] ;
2 -> 6 ;
}
根据这个信息,决策树应该长的如下这个样子:
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-

python利用sklearn包编写决策树源代码
本文实例为大家分享了python编写决策树源代码,供大家参考,具体内容如下 因为最近实习的需要,所以用python里的sklearn包重新写了一次决策树. 工具:sklearn,将dot文件转化为pdf格式(是为了将形成的决策树可视化)graphviz-2.38,下载解压之后将其中的bin文件的目录添加进环境变量 源代码如下: from sklearn.feature_extraction import DictVectorizer import csv from sklearn import
-
python实现决策树
本文实例为大家分享了python实现决策树的具体代码,供大家参考,具体内容如下 算法优缺点: 优点:计算复杂度不高,输出结果易于理解,对中间值缺失不敏感,可以处理不相关的特征数据 缺点:可能会产生过度匹配的问题 适用数据类型:数值型和标称型 算法思想: 1.决策树构造的整体思想: 决策树说白了就好像是if-else结构一样,它的结果就是你要生成这个一个可以从根开始不断判断选择到叶子节点的树,但是呢这里的if-else必然不会是让我们认为去设置的,我们要做的是提供一种方法,计算机可以根据这种方法得
-
Python机器学习之决策树算法
一.决策树原理 决策树是用样本的属性作为结点,用属性的取值作为分支的树结构. 决策树的根结点是所有样本中信息量最大的属性.树的中间结点是该结点为根的子树所包含的样本子集中信息量最大的属性.决策树的叶结点是样本的类别值.决策树是一种知识表示形式,它是对所有样本数据的高度概括决策树能准确地识别所有样本的类别,也能有效地识别新样本的类别. 决策树算法ID3的基本思想: 首先找出最有判别力的属性,把样例分成多个子集,每个子集又选择最有判别力的属性进行划分,一直进行到所有子集仅包含同一类型的数据为止.最后
-
python决策树之C4.5算法详解
本文为大家分享了决策树之C4.5算法,供大家参考,具体内容如下 1. C4.5算法简介 C4.5算法是用于生成决策树的一种经典算法,是ID3算法的一种延伸和优化.C4.5算法对ID3算法主要做了一下几点改进: (1)通过信息增益率选择分裂属性,克服了ID3算法中通过信息增益倾向于选择拥有多个属性值的属性作为分裂属性的不足: (2)能够处理离散型和连续型的属性类型,即将连续型的属性进行离散化处理: (3)构造决策树之后进行剪枝操作: (4)能够处理具有缺失属性值的训练数据. 2
-
python实现决策树分类算法
本文实例为大家分享了python实现决策树分类算法的具体代码,供大家参考,具体内容如下 1.概述 决策树(decision tree)--是一种被广泛使用的分类算法. 相比贝叶斯算法,决策树的优势在于构造过程不需要任何领域知识或参数设置 在实际应用中,对于探测式的知识发现,决策树更加适用. 2.算法思想 通俗来说,决策树分类的思想类似于找对象.现想象一个女孩的母亲要给这个女孩介绍男朋友,于是有了下面的对话: 女儿:多大年纪了? 母亲:26. 女儿:长的帅不帅? 母亲:挺帅的. 女儿:收入高不?
-
python编写分类决策树的代码
决策树通常在机器学习中用于分类. 优点:计算复杂度不高,输出结果易于理解,对中间值缺失不敏感,可以处理不相关特征数据. 缺点:可能会产生过度匹配问题. 适用数据类型:数值型和标称型. 1.信息增益 划分数据集的目的是:将无序的数据变得更加有序.组织杂乱无章数据的一种方法就是使用信息论度量信息.通常采用信息增益,信息增益是指数据划分前后信息熵的减少值.信息越无序信息熵越大,获得信息增益最高的特征就是最好的选择. 熵定义为信息的期望,符号xi的信息定义为: 其中p(xi)为该分类的概率. 熵,即信息
-
python机器学习之决策树分类详解
决策树分类与上一篇博客k近邻分类的最大的区别就在于,k近邻是没有训练过程的,而决策树是通过对训练数据进行分析,从而构造决策树,通过决策树来对测试数据进行分类,同样是属于监督学习的范畴.决策树的结果类似如下图: 图中方形方框代表叶节点,带圆边的方框代表决策节点,决策节点与叶节点的不同之处就是决策节点还需要通过判断该节点的状态来进一步分类. 那么如何通过训练数据来得到这样的决策树呢? 这里涉及要信息论中一个很重要的信息度量方式,香农熵.通过香农熵可以计算信息增益. 香农熵的计算公式如下: p(xi)
-
python决策树之CART分类回归树详解
决策树之CART(分类回归树)详解,具体内容如下 1.CART分类回归树简介 CART分类回归树是一种典型的二叉决策树,可以处理连续型变量和离散型变量.如果待预测分类是离散型数据,则CART生成分类决策树:如果待预测分类是连续型数据,则CART生成回归决策树.数据对象的条件属性为离散型或连续型,并不是区别分类树与回归树的标准,例如表1中,数据对象xi的属性A.B为离散型或连续型,并是不区别分类树与回归树的标准. 表1 2.CART分类回归树分裂属性的选择 2.1 CART分类树--待预测
-
python代码实现ID3决策树算法
本文实例为大家分享了python实现ID3决策树算法的具体代码,供大家参考,具体内容如下 ''''' Created on Jan 30, 2015 @author: 史帅 ''' from math import log import operator import re def fileToDataSet(fileName): ''''' 此方法功能是:从文件中读取样本集数据,样本数据的格式为:数据以空白字符分割,最后一列为类标签 参数: fileName:存放样本集数据的文件路径 返回值:
-
Python决策树分类算法学习
从这一章开始进入正式的算法学习. 首先我们学习经典而有效的分类算法:决策树分类算法. 1.决策树算法 决策树用树形结构对样本的属性进行分类,是最直观的分类算法,而且也可以用于回归.不过对于一些特殊的逻辑分类会有困难.典型的如异或(XOR)逻辑,决策树并不擅长解决此类问题. 决策树的构建不是唯一的,遗憾的是最优决策树的构建属于NP问题.因此如何构建一棵好的决策树是研究的重点. J. Ross Quinlan在1975提出将信息熵的概念引入决策树的构建,这就是鼎鼎大名的ID3算法.后续的C4.5,
-
Python KNN分类算法学习
本文实例为大家分享了Python KNN分类算法的具体代码,供大家参考,具体内容如下 1.KNN分类算法 KNN分类算法(K-Nearest-Neighbors Classification),又叫K近邻算法,是一个概念极其简单,而分类效果又很优秀的分类算法. 他的核心思想就是,要确定测试样本属于哪一类,就寻找所有训练样本中与该测试样本"距离"最近的前K个样本,然后看这K个样本大部分属于哪一类,那么就认为这个测试样本也属于哪一类.简单的说就是让最相似的K个样本来投票决定. 这里所说的距
-
python实现决策树分类算法代码示例
目录 前置信息 1.决策树 2.样本数据 策树分类算法 1.构建数据集 2.数据集信息熵 3.信息增益 4.构造决策树 5.实例化构造决策树 6.测试样本分类 后置信息:绘制决策树代码 总结 前置信息 1.决策树 决策树是一种十分常用的分类算法,属于监督学习:也就是给出一批样本,每个样本都有一组属性和一个分类结果.算法通过学习这些样本,得到一个决策树,这个决策树能够对新的数据给出合适的分类 2.样本数据 假设现有用户14名,其个人属性及是否购买某一产品的数据如下: 编号 年龄 收入范围 工作性质
-
python入门之算法学习
前言 参考学习书籍:<算法图解>[美]Aditya Bhargava,袁国忠(译)北京人民邮电出版社,2017 二分查找 binary_search 实现二分查找的python代码如下: def binary_search(list, item): low = 0 #最低位索引位置为0 high = len(list)- 1 #最高位索引位置为总长度-1 while low <= high: mid = (low + high)//2 #检查中间的元素,书上是一条斜杠,我试过加两条斜杠才
-
Python决策树和随机森林算法实例详解
本文实例讲述了Python决策树和随机森林算法.分享给大家供大家参考,具体如下: 决策树和随机森林都是常用的分类算法,它们的判断逻辑和人的思维方式非常类似,人们常常在遇到多个条件组合问题的时候,也通常可以画出一颗决策树来帮助决策判断.本文简要介绍了决策树和随机森林的算法以及实现,并使用随机森林算法和决策树算法来检测FTP暴力破解和POP3暴力破解,详细代码可以参考: https://github.com/traviszeng/MLWithWebSecurity 决策树算法 决策树表现了对象属性和
-
python sklearn常用分类算法模型的调用
本文实例为大家分享了python sklearn分类算法模型调用的具体代码,供大家参考,具体内容如下 实现对'NB', 'KNN', 'LR', 'RF', 'DT', 'SVM','SVMCV', 'GBDT'模型的简单调用. # coding=gbk import time from sklearn import metrics import pickle as pickle import pandas as pd # Multinomial Naive Bayes Classifier d
-
python实现决策树分类(2)
在上一篇文章中,我们已经构建了决策树,接下来可以使用它用于实际的数据分类.在执行数据分类时,需要决策时以及标签向量.程序比较测试数据和决策树上的数值,递归执行直到进入叶子节点. 这篇文章主要使用决策树分类器就行分类,数据集采用UCI数据库中的红酒,白酒数据,主要特征包括12个,主要有非挥发性酸,挥发性酸度, 柠檬酸, 残糖含量,氯化物, 游离二氧化硫, 总二氧化硫,密度, pH,硫酸盐,酒精, 质量等特征. 下面是具体代码的实现: #coding :utf-8 ''' 2017.6.26 aut
-
用Python实现KNN分类算法
本文实例为大家分享了Python KNN分类算法的具体代码,供大家参考,具体内容如下 KNN分类算法应该算得上是机器学习中最简单的分类算法了,所谓KNN即为K-NearestNeighbor(K个最邻近样本节点).在进行分类之前KNN分类器会读取较多数量带有分类标签的样本数据作为分类的参照数据,当它对类别未知的样本进行分类时,会计算当前样本与所有参照样本的差异大小:该差异大小是通过数据点在样本特征的多维度空间中的距离来进行衡量的,也就是说,如果两个样本点在在其特征数据多维度空间中的距离越近,则这
-
Python机器学习应用之决策树分类实例详解
目录 一.数据集 二.实现过程 1 数据特征分析 2 利用决策树模型在二分类上进行训练和预测 3 利用决策树模型在多分类(三分类)上进行训练与预测 三.KEYS 1 构建过程 2 划分选择 3 重要参数 一.数据集 小企鹅数据集,提取码:1234 该数据集一共包含8个变量,其中7个特征变量,1个目标分类变量.共有150个样本,目标变量为 企鹅的类别 其都属于企鹅类的三个亚属,分别是(Adélie, Chinstrap and Gentoo).包含的三种种企鹅的七个特征,分别是所在岛屿,嘴巴长度,